
Даны определения Функции распределения случайной величины и Плотности вероятности непрерывной случайной величины. Эти понятия активно используются в статьях о статистике сайта
www.excel2.ru
. Рассмотрены примеры вычисления Функции распределения и Плотности вероятности с помощью функций MS EXCEL
.
Введем базовые понятия статистики, без которых невозможно объяснить более сложные понятия.
Генеральная совокупность и случайная величина
Пусть у нас имеется
генеральная совокупность
(population) из N объектов, каждому из которых присуще определенное значение некоторой числовой характеристики Х.
Примером генеральной совокупности (ГС) может служить совокупность весов однотипных деталей, которые производятся станком.
Поскольку в математической статистике, любой вывод делается только на основании характеристики Х (абстрагируясь от самих объектов), то с этой точки зрения
генеральная совокупность
представляет собой N чисел, среди которых, в общем случае, могут быть и одинаковые.
В нашем примере, ГС — это просто числовой массив значений весов деталей. Х – вес одной из деталей.
Если из заданной ГС мы выбираем случайным образом один объект, имеющей характеристику Х, то величина Х является
случайной величиной
. По определению, любая
случайная величина
имеет
функцию распределения
, которая обычно обозначается F(x).
Функция распределения
Функцией распределения
вероятностей
случайной величины
Х называют функцию F(x), значение которой в точке х равно вероятности события X
F(x) = P(X
Поясним на примере нашего станка. Хотя предполагается, что наш станок производит только один тип деталей, но, очевидно, что вес изготовленных деталей будет слегка отличаться друг от друга. Это возможно из-за того, что при изготовлении мог быть использован разный материал, а условия обработки также могли слегка различаться и пр. Пусть самая тяжелая деталь, произведенная станком, весит 200 г, а самая легкая — 190 г. Вероятность того, что случайно выбранная деталь Х будет весить меньше 200 г равна 1. Вероятность того, что будет весить меньше 190 г равна 0. Промежуточные значения определяются формой Функции распределения. Например, если процесс настроен на изготовление деталей весом 195 г, то разумно предположить, что вероятность выбрать деталь легче 195 г равна 0,5.
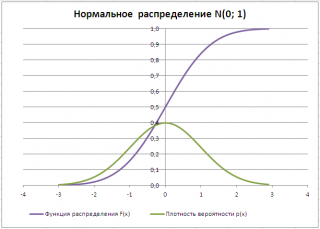
Типичный график
Функции распределения
для непрерывной случайной величины приведен на картинке ниже (фиолетовая кривая, см.
файл примера
):
В справке MS EXCEL
Функцию распределения
называют
Интегральной
функцией распределения
(
Cumulative
Distribution
Function
,
CDF
).
Приведем некоторые свойства
Функции распределения:
Функция распределения
F(x) изменяется в интервале [0;1], т.к. ее значения равны вероятностям соответствующих событий (по определению вероятность может быть в пределах от 0 до 1);
Функция распределения
– неубывающая функция;-
Вероятность того, что случайная величина приняла значение из некоторого диапазона [x1;x2): P(x
1
<=X
2)=F(x
2
)-F(x
1
).
Существует 2 типа распределений:
непрерывные распределения
и
дискретные распределения
.
Дискретные распределения
Если случайная величина может принимать только определенные значения и количество таких значений конечно, то соответствующее распределение называется
дискретным
. Например, при бросании монеты, имеется только 2 элементарных исхода, и, соответственно, случайная величина может принимать только 2 значения. Например, 0 (выпала решка) и 1 (не выпала решка) (см.
схему Бернулли
). Если монета симметричная, то вероятность каждого исхода равна 1/2. При бросании кубика случайная величина принимает значения от 1 до 6. Вероятность каждого исхода равна 1/6. Сумма вероятностей всех возможных значений случайной величины равна 1.
Примечание
: В MS EXCEL имеется несколько функций, позволяющих вычислить вероятности дискретных случайных величин. Перечень этих функций приведен в статье
Распределения случайной величины в MS EXCEL
.
Непрерывные распределения и плотность вероятности
В случае
непрерывного распределения
случайная величина может принимать любые значения из интервала, в котором она определена. Т.к. количество таких значений бесконечно велико, то мы не можем, как в случае дискретной величины, сопоставить каждому значению случайной величины ненулевую вероятность (т.е. вероятность попадания в любую точку (заданную до опыта) для
непрерывной случайной величины
равна нулю). Т.к. в противном случае сумма вероятностей всех возможных значений случайной величины будет равна бесконечности, а не 1. Выходом из этой ситуации является введение так называемой
функции плотности распределения p(x)
. Чтобы найти вероятность того, что непрерывная случайная величина Х примет значение, заключенное в интервале (а; b), необходимо найти приращение
функции распределения
на этом интервале:
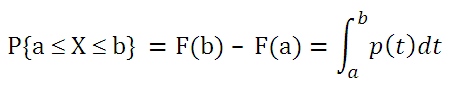
Как видно из формулы выше
плотность распределения
р(х) представляет собой производную
функции распределения
F(x), т.е. р(х) = F’(x).
Типичный график
функции плотности распределения
для непрерывной случайно величины приведен на картинке ниже (зеленая кривая):
Примечание
: В MS EXCEL имеется несколько функций, позволяющих вычислить вероятности непрерывных случайных величин. Перечень этих функций приведен в статье
Распределения случайной величины в MS EXCEL
.
В литературе
Функция плотности распределения
непрерывной случайной величины может называться:
Плотность вероятности, Плотность распределения, англ. Probability Density Function (PDF)
.
Чтобы все усложнить, термин
Распределение
(в литературе на английском языке —
Probability
Distribution
Function
или просто
Distribution
)
в зависимости от контекста может относиться как
Интегральной
функции распределения,
так и кее
Плотности распределения.
Из определения
функции плотности распределения
следует, что p(х)>=0. Следовательно, плотность вероятности для непрерывной величины может быть, в отличие от
Функции распределения,
больше 1. Например, для
непрерывной равномерной величины
, распределенной на интервале [0; 0,5]
плотность вероятности
равна 1/(0,5-0)=2. А для
экспоненциального распределения
с параметром
лямбда
=5, значение
плотности вероятности
в точке х=0,05 равно 3,894. Но, при этом можно убедиться, что вероятность на любом интервале будет, как обычно, от 0 до 1.
Напомним, что
плотность распределения
является производной от
функции распределения
, т.е. «скоростью» ее изменения: p(x)=(F(x2)-F(x1))/Dx при Dx стремящемся к 0, где Dx=x2-x1. Т.е. тот факт, что
плотность распределения
>1 означает лишь, что функция распределения растет достаточно быстро (это очевидно на примере
экспоненциального распределения
).
Примечание
: Площадь, целиком заключенная под всей кривой, изображающей
плотность распределения
, равна 1.
Примечание
: Напомним, что функцию распределения F(x) называют в функциях MS EXCEL
интегральной функцией распределения
. Этот термин присутствует в параметрах функций, например в
НОРМ.РАСП
(x; среднее; стандартное_откл;
интегральная
). Если функция MS EXCEL должна вернуть
Функцию распределения,
то параметр
интегральная
, д.б. установлен ИСТИНА. Если требуется вычислить
плотность вероятности
, то параметр
интегральная
, д.б. ЛОЖЬ.
Примечание
: Для
дискретного распределения
вероятность случайной величине принять некое значение также часто называется плотностью вероятности (англ. probability mass function (pmf)). В справке MS EXCEL
плотность вероятности
может называть даже «функция вероятностной меры» (см. функцию
БИНОМ.РАСП()
).
Вычисление плотности вероятности с использованием функций MS EXCEL
Понятно, что чтобы вычислить
плотность вероятности
для определенного значения случайной величины, нужно знать ее распределение.
Найдем
плотность вероятности
для
стандартного нормального распределения
N(0;1) при x=2. Для этого необходимо записать формулу
=НОРМ.СТ.РАСП(2;ЛОЖЬ)
=0,054 или
=НОРМ.РАСП(2;0;1;ЛОЖЬ)
.
Напомним, что
вероятность
того, что
непрерывная случайная величина
примет конкретное значение x равна 0. Для
непрерывной случайной величины
Х можно вычислить только вероятность события, что Х примет значение, заключенное в интервале (а; b).
Вычисление вероятностей с использованием функций MS EXCEL
1) Найдем вероятность, что случайная величина, распределенная по
стандартному нормальному распределению
(см. картинку выше), приняла положительное значение. Согласно свойству
Функции распределения
вероятность равна F(+∞)-F(0)=1-0,5=0,5.
В MS EXCEL для нахождения этой вероятности используйте формулу
=НОРМ.СТ.РАСП(9,999E+307;ИСТИНА) -НОРМ.СТ.РАСП(0;ИСТИНА)
=1-0,5. Вместо +∞ в формулу введено значение 9,999E+307= 9,999*10^307, которое является максимальным числом, которое можно ввести в ячейку MS EXCEL (так сказать, наиболее близкое к +∞).
2) Найдем вероятность, что случайная величина, распределенная по
стандартному нормальному распределению
, приняла отрицательное значение. Согласно определения
Функции распределения,
вероятность равна F(0)=0,5.
В MS EXCEL для нахождения этой вероятности используйте формулу
=НОРМ.СТ.РАСП(0;ИСТИНА)
=0,5.
3) Найдем вероятность того, что случайная величина, распределенная по
стандартному нормальному распределению
, примет значение, заключенное в интервале (0; 1). Вероятность равна F(1)-F(0), т.е. из вероятности выбрать Х из интервала (-∞;1) нужно вычесть вероятность выбрать Х из интервала (-∞;0). В MS EXCEL используйте формулу
=НОРМ.СТ.РАСП(1;ИСТИНА) — НОРМ.СТ.РАСП(0;ИСТИНА)
.
Все расчеты, приведенные выше, относятся к случайной величине, распределенной по
стандартному нормальному закону
N(0;1). Понятно, что значения вероятностей зависят от конкретного распределения. В статье
Распределения случайной величины в MS EXCEL
приведены распределения, для которых в MS EXCEL имеются соответствующие функции, позволяющие вычислить вероятности.
Обратная функция распределения (Inverse Distribution Function)
Вспомним задачу из предыдущего раздела:
Найдем вероятность, что случайная величина, распределенная по стандартному нормальному распределению, приняла отрицательное значение.
Вероятность этого события равна 0,5.
Теперь решим обратную задачу: определим х, для которого вероятность, того что случайная величина Х примет значение
медиану
или 50-ю
процентиль
).
Для этого необходимо на графике
функции распределения
найти точку, для которой F(х)=0,5, а затем найти абсциссу этой точки. Абсцисса точки =0, т.е. вероятность, того что случайная величина Х примет значение <0, равна 0,5.
В MS EXCEL используйте формулу
=НОРМ.СТ.ОБР(0,5)
=0.
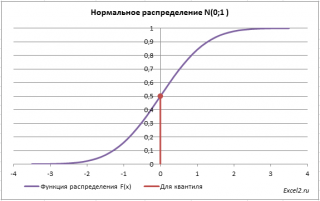
Однозначно вычислить значение
случайной величины
позволяет свойство монотонности
функции распределения.
Обратите внимание, что для вычисления обратной функции мы использовали именно
функцию распределения
, а не
плотность распределения
. Поэтому, в аргументах функции
НОРМ.СТ.ОБР()
отсутствует параметр
интегральная
, который подразумевается. Подробнее про функцию
НОРМ.СТ.ОБР()
см. статью про
нормальное распределение
.
Обратная функция распределения
вычисляет
квантили распределения
, которые используются, например, при
построении доверительных интервалов
. Т.е. в нашем случае число 0 является 0,5-квантилем
нормального распределения
. В
файле примера
можно вычислить и другой
квантиль
этого распределения. Например, 0,8-квантиль равен 0,84.
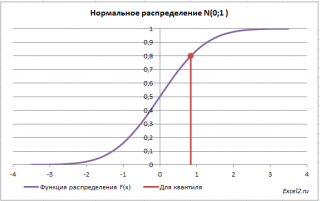
В англоязычной литературе
обратная функция распределения
часто называется как Percent Point Function (PPF).
Примечание
: При вычислении
квантилей
в MS EXCEL используются функции:
НОРМ.СТ.ОБР()
,
ЛОГНОРМ.ОБР()
,
ХИ2.ОБР(),
ГАММА.ОБР()
и т.д. Подробнее о распределениях, представленных в MS EXCEL, можно прочитать в статье
Распределения случайной величины в MS EXCEL
.
To begin with, statistical function in Excel let’s first understand what is statistics and why we need it? So, statistics is a branch of sciences that can give a property to a sample. It deals with collecting, organizing, analyzing, and presenting the data. One of the great mathematicians Karl Pearson, also the father of modern statistics quoted that, “statistics is the grammar of science”.
We used statistics in every industry, including business, marketing, governance, engineering, health, etc. So in short statistics a quantitative tool to understand the world in a better way. For example, the government studies the demography of his/her country before making any policy and the demography can only study with the help of statistics. We can take another example for making a movie or any campaign it is very important to understand your audience and there too we used statistics as our tool.
Ways to approach statistical function in Excel:
In Excel, we have a range of statical functions, we can perform basic mead, median mode to more complex statistical distribution, and probability test. In order to understand statistical Functions we will divide them into two sets:
- Basic statistical Function
- Intermediate Statistical Function.
Statistical Function in Excel
Excel is the best tool to apply statistical functions. As discussed above we first discuss the basic statistical function, and then we will study intermediate statistical function. Throughout the article, we will take data and by using it we will understand the statistical function.
So, let’s take random data of a book store that sells textbooks for classes 11th and 12th.
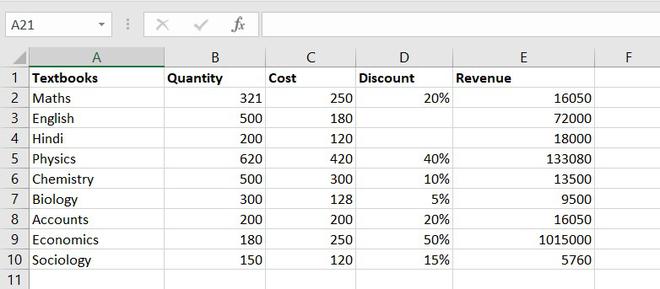
Example of statistical function.
Basic statistical Function
These are some most common and useful functions. These include the COUNT function, COUNTA function, COUNTBLANK function, COUNTIFS function. Let’s discuss one by one:
1. COUNT function
The COUNT function is used to count the number of cells containing a number. Always remember one thing that it will only count the number.
Formula for COUNT function = COUNT(value1, [value2], …)
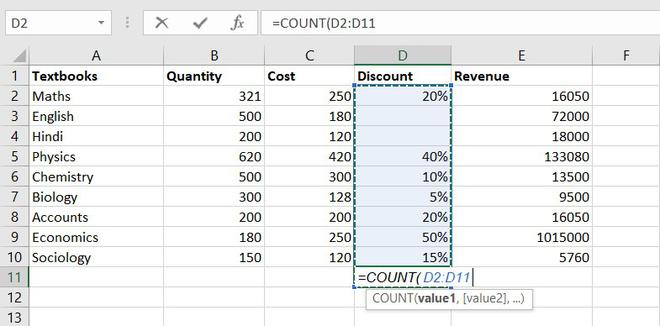
Example of statistical function.
Thus, there are 7 textbooks that have a discount out of 9 books.
2. COUNTA function
This function will count everything, it will count the number of the cell containing any kind of information, including numbers, error values, empty text.
Formula for COUNTA function = COUNTA(value1, [value2], …)
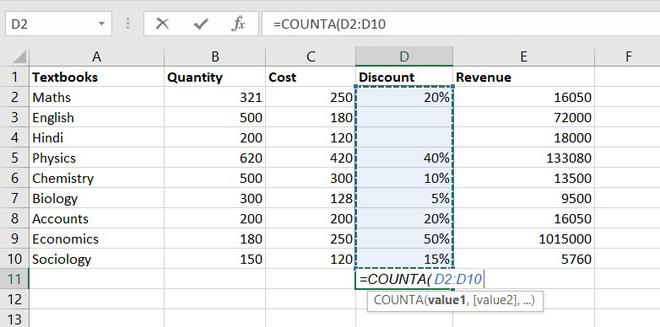
Example of statistical function.
So, there are a total of 9 subjects that being sold in the store
3. COUNTBLANK function
COUNTBLANK function, as the term, suggest it will only count blank or empty cells.
Formula for COUNTBlANK function = COUNTBLANK(range)
![]()
Example of statistical function.
There are 2 subjects that don’t have any discount.
4. COUNTIFS function
COUNTIFS function is the most used function in Excel. The function will work on one or more than one condition in a given range and counts the cell that meets the condition.
Formula for COUNTIFS function = COUNTIFS (range1, criteria1, [range2], [criteria2], ...)
Intermediate Statistical Function
Let’s discuss some intermediate statistical functions in Excel. These functions used more often by the analyst. It includes functions like AVERAGE function, MEDIAN function, MODE function, STANDARD DEVIATION function, VARIANCE function, QUARTILES function, CORRELATION function.
1. AVERAGE value1, [value2], …)
The AVERAGE function is one of the most used intermediate functions. The function will return the arithmetic mean or an average of the cell in a given range.
Formula for AVERAGE function = AVERAGE(number1, [number2], …)
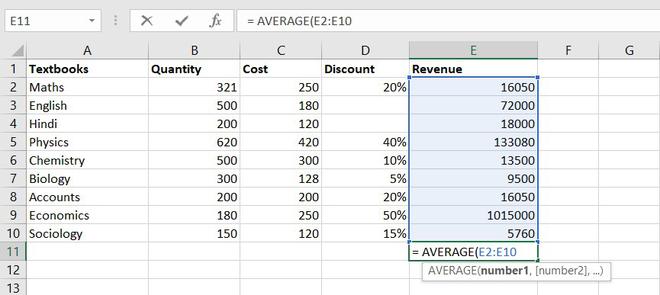
Example of statistical function.
So the average total revenue is Rs.144326.6667
2. AVERAGEIF function
The function will return the arithmetic mean or an average of the cell in a given range that meets the given criteria.
Formula for AVERAGEIF function = AVERAGEIF(range, criteria, [average_range])
3. MEDIAN function
The MEDIAN function will return the central value of the data. Its syntax is similar to the AVERAGE function.
Formula for MEDIAN function = MEDIAN(number1, [number2], …)
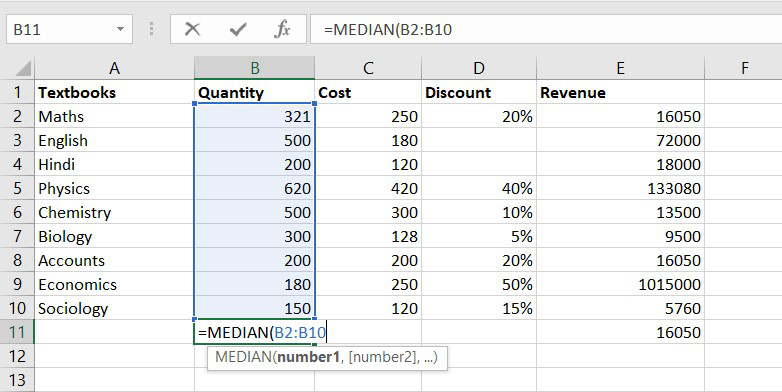
Example of statistical function.
Thus, the median quantity sold is 300.
4. MODE function
The MODE function will return the most frequent value of the cell in a given range.
Formula for MODE function = MODE.SNGL(number1,[number2],…)
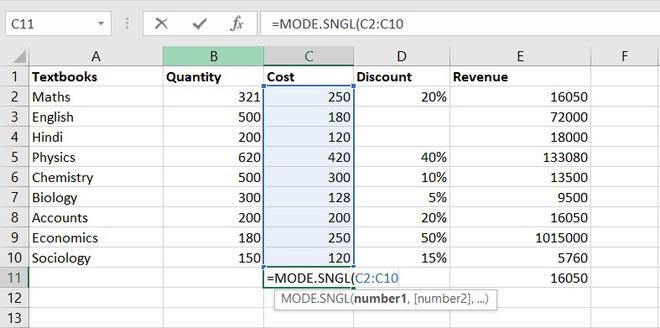
Example of statistical function.
Thus, the most frequent or repetitive cost is Rs. 250.
5. STANDARD DEVIATION
This function helps us to determine how much observed value deviated or varied from the average. This function is one of the useful functions in Excel.
Formula for STANDARD DEVIATION function = STDEV.P(number1,[number2],…)
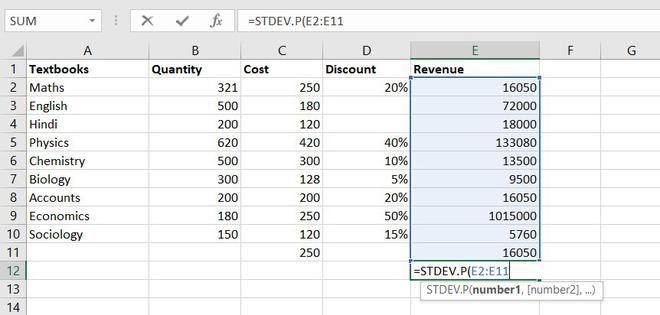
Example of statistical function.
Thus, Standard Deviation of total revenue =296917.8172
6. VARIANCE function
To understand the VARIANCE function, we first need to know what is variance? Basically, Variance will determine the degree of variation in your data set. The more data is spread it means the more is variance.
Formula for VARIANCE function = VAR(number1, [number2], …)
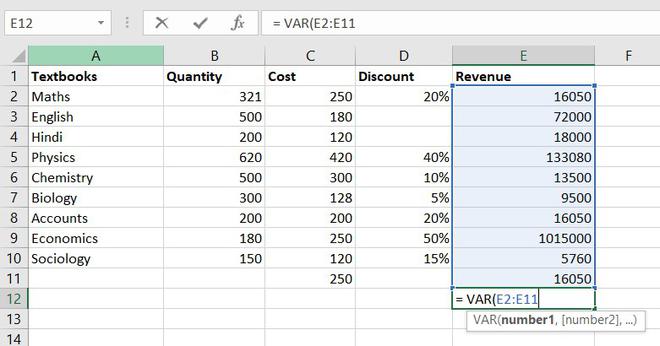
Example of statistical function.
So, the variance of Revenue= 97955766832
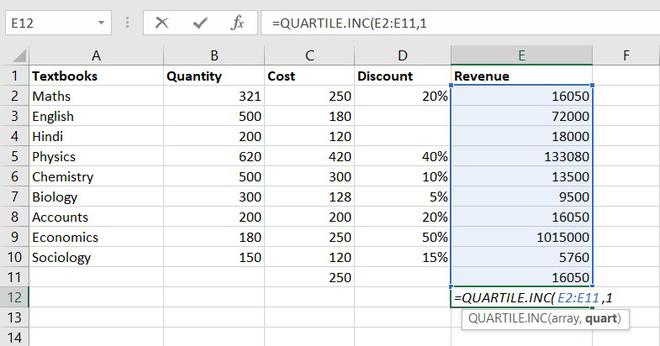
7. QUARTILES function
Quartile divides the data into 4 parts just like the median which divides the data into two equal parts. So, the Excel QUARTILES function returns the quartiles of the dataset. It can return the minimum value, first quartile, second quartile, third quartile, and max value. Let’s see the syntax :
Formula for QUARTILES function = QUARTILE (array, quart)
Example of statistical function.
So, the first quartile = 14137.5
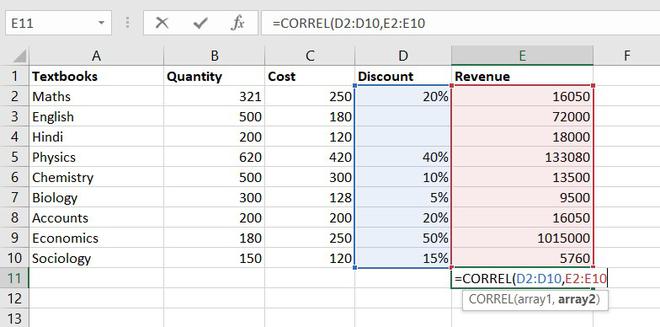
8. CORRELATION function
CORRELATION function, help to find the relationship between the two variables, this function mostly used by the analyst to study the data. The range of the CORRELATION coefficient lies between -1 to +1.
Formula for CORRELATION function = CORREL(array1, array2)
Example of statistical function.
So, the correlation coefficient between discount and revenue of store = 0.802428894. Since it is a positive number, thus we can conclude discount is positively related to revenue.
9. MAX function
The MAX function will return the largest numeric value within a given set of data or an array.
Formula for MAX function = MAX (number1, [number2], ...)
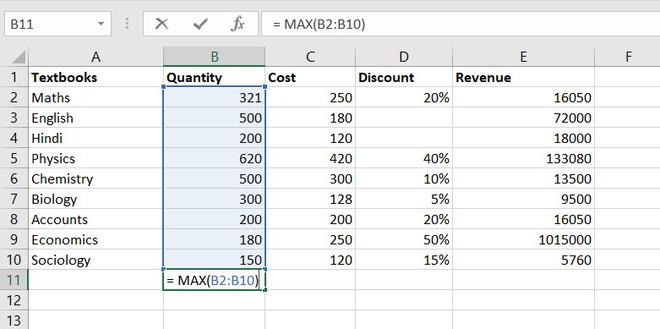
The maximum quantity of textbooks is Physics,620 in numbers.
10. MIN function
The MIN function will return the smallest numeric value within a given set of data or an array.
Formula for MIN function = MIN (number1, [number2], ...)
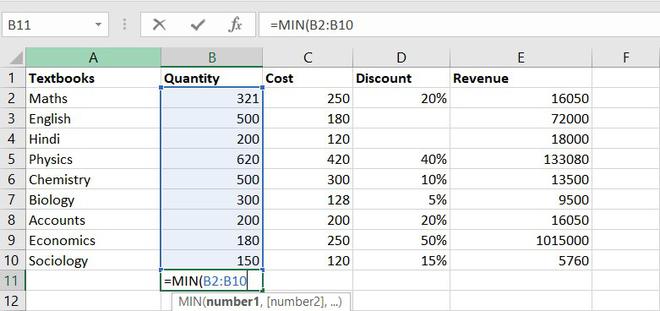
The minimum number of the book available in the store =150(Sociology)
11. LARGE function
The LARGE function is similar to the MAX function but the only difference is it returns the nth largest value within a given set of data or an array.
Formula for LARGE function = LARGE (array, k)
Let’s find the most expensive textbook using a large function, where k = 1
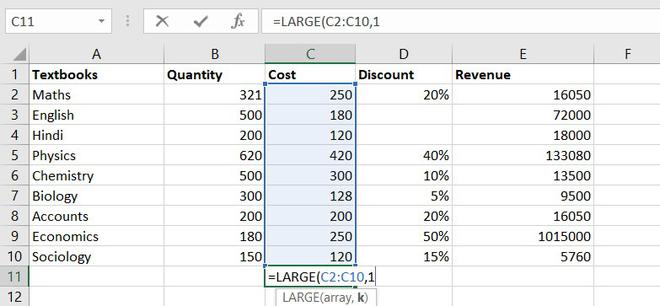
Example of statistical function.
The most expensive textbook is Rs. 420.
12. SMALL function
The SMALL function is similar to the MIN function, but the only difference is it return nth smallest value within a given set of data or an array.
Formula for SMALL function = SMALL (array, k)
Similarly, using the SMALL function we can find the second least expensive book.
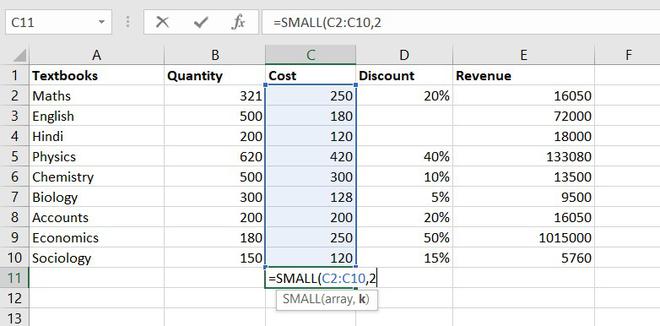
Example of statistical function.
Thus, Rs. 120 is the least cost price.
Conclusion
So these are some statistical functions of Excel. We have learned some of the most simple functions like COUNT functions to complex ones like the CORRELATION function. So far we learn, we understand how much these functions are useful for analyzing any data. You can explore more functions and learn more things of your own.
2.1.2. Эмпирическая функция распределения
Это статистический аналог функции распределения из теорвера. Данная функция определяется, как отношение:
, где – количество вариант СТРОГО МЕНЬШИХ, чем ,
при этом «икс» «пробегает» все значения от «минус» до «плюс» бесконечности.
Построим эмпирическую функцию распределения для нашей задачи. Чтобы было нагляднее, отложу варианты и их количество на числовой оси: 
На интервале – по той причине, что левее ЛЮБОЙ точки этого интервала вариант нет. Кроме того, функция равна нулю ещё и в точке . Почему? Потому, что значение определяет количество вариант (см. определение), которые СТРОГО меньше двух, а это количество равно нулю.
На промежутке – и опять обратите внимание, что значение не учитывает рабочих 3-го разряда, т.к. речь идёт о вариантах, которые СТРОГО меньше трёх (по определению).
На промежутке – и далее процесс продолжается по принципу накопления частот:
– если , то ;
– если , то ;
– и, наконец, если , то – и в самом деле, для ЛЮБОГО «икс» из интервала ВСЕ частоты расположены СТРОГО левее этого значения «икс» (см. чертёж выше).
Накопленные относительные частоты удобно заносить в отдельный столбец таблицы, при этом алгоритм вычислений очень прост: сначала сносим слева частоту (красная стрелка), и каждое следующее значение получаем как сумму предыдущего и относительной частоты из текущего левого столбца (зелёные обозначения): 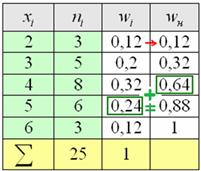
Вот ещё, кстати, один довод за вертикальную ориентацию данных – справа по надобности можно приписывать дополнительные столбцы.
Построенную функцию принято записывать в кусочном виде:
а её график представляет собой ступенчатую фигуру: 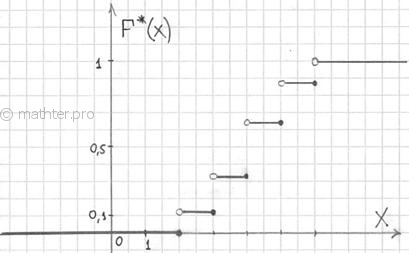
Эмпирическая функция распределения не убывает и принимает значения лишь из промежутка , и если у вас вдруг получится что-то не так, то ищите ошибку.
Теперь смотрим видео, о том, как построить эту функцию в Экселе (Ютуб).
И, конечно, вспомним основной метод математической статистики. Эмпирическая функция распределения строится по выборке и приближает теоретическую функцию распределения . Легко догадаться, что последняя появляется в результате исследования всей генеральной совокупности, но если рабочих в цехе ещё пересчитать можно, то звёзды на небе – уже вряд ли. Вот поэтому и важнА функция эмпирическая, и ещё важнее, чтобы выборка была репрезентативна, дабы приближение было хорошим.
Миниатюрное задание для закрепления материала:
Пример 5
Дано статистическое распределение совокупности: 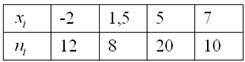
Составить эмпирическую функцию распределения, выполнить чертёж
Решаем самостоятельно – все числа уже в Экселе! Свериться с образцом можно в конце книги. По поводу красоты чертежа сильно не запаривайтесь, главное, чтобы было правильно – этого обычно достаточно для зачёта.
Из таблицы n=40, т.е.
n=4+10+6+8+7+5=40
Вычислим функцию распределения выборки 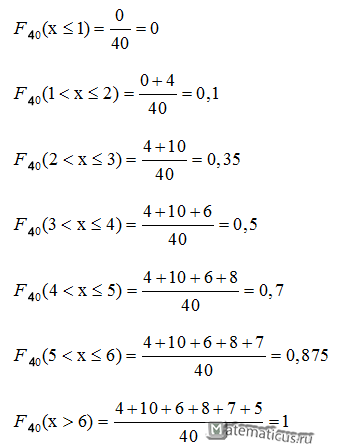
Эмпирическая функция распределения имеет вид

Построим график кусочно-постоянной эмпирической функции распределения
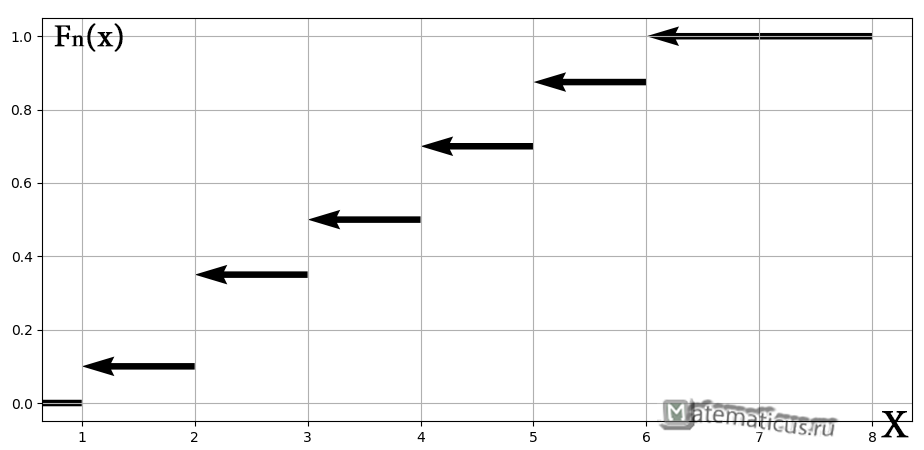
таким образом, по данным выборки можно приближенно построить функцию для неизвестной функции выборки.
2 комментария
У вас опечатка, где вы написали n=30, n=4+10+6+8+7+5=30 и F_30, так как n=40.
Построить эмпирическое распределение результатов тестирования в баллах для следующей выборки: 69, 85, 78, 85, 83, 81, 95, 88, 97, 92, 74, 83, 89, 77, 93.
В ячейку А1 введите слова Результаты, в диапазон А2:А16 – результаты тестирования.
Выберите ширину интервала 5 баллов. Тогда при крайних результатах 69 и 97 баллов, получится 7 интервалов. В ячейку С1 введите название интервалов Границы. В диапазон С2:С8 введите граничные значения интервалов: 70, 75, 80, 85, 90, 95, 100.
Введите заголовки создаваемой таблицы: в ячейку D1 – Абсолютные частоты, в ячейку Е1 – Относительные частоты, в F1 – Накопленные частоты.
Заполните столбец абсолютных частот. Для этого выделите для них блок ячеек D2:D8, вызовите Мастер функций, категория – Статистические, функция – Частота, в поле Массив данных введите диапазон данных тестирования А2:А16, в поле Массив интервалов введите диапазон интервалов С2:С8, нажмите комбинацию клавиш Ctrl+Shift+Enter. В столбце D2:D8 появится массив абсолютных частот.
В ячейке D9 найдите общее количество результатов тестирования, с помощью Автосумма.
Заполните столбец относительных частот. В ячейку Е2 введите формулу =$D2/$D$9 .
Протягиванием скопируйте полученное значение в диапазон Е3:Е8. Получим массив относительных частот.
Заполните столбец накопленных частот. В ячейку F2 скопируйте значение относительной частоты из ячейки Е2. В ячейку F3 введите формулу =F2+E3. Протягиванием скопируйте полученное значение в диапазон F4:F8. Получим массив накопленных частот.
В результате получим таблицу, представленную на рисунке 1.
Пусть Nх — число наблюдений, при которых значение признака Х меньше Х. При объеме выборки, равном П, относительная частота события Х XK.
Сама же функция F*(X) служит для оценки теоретической функции распределения F(X) генеральной совокупности.
Пример 3. Построить эмпирическую функцию по заданному распределению выборки:

Решение. Находим объем выборки: П = 10 + 15 + 25 = 50. Наименьшая варианта равна 2, поэтому F*(X) = 0 при Х ≤ 2. Значение Х 6. Напишем формулу искомой эмпирической функции:
4. Рассмотрим любой из критериев оценки качеств педагога-профессионала, например, «успешное решение задач обучения и воспитания». Ответ на этот вопрос анкеты типа «да», «нет» достаточно груб. Чтобы уменьшить относительную ошибку такого измерения, необходимо увеличить число возможных ответов на конкретный критериальный вопрос. В табл. 1 представлены возможные варианты ответов.
Обозначим этот параметр через х. Тогда в процессе ответа на вопрос величина х примет дискретное значение х, принадлежащее определенному интервалу значений. Поставим в соответствие каждому из ответов определенное числовое значение параметра х (см. табл. 1).
Рассмотренные в лабораторной работе 2 распределения вероятностей СВ
опираются на знание закона распределения СВ. Для практических задач такое
знание – редкость. Здесь закон распределения обычно неизвестен, или известен с
точностью до некоторых неизвестных параметров. В частности, невозможно
рассчитать точное значение соответствующих вероятностей, так как нельзя
определить количество общих и благоприятных исходов. Поэтому вводится статистическое
определение вероятности. По этому определению вероятность равна отношению
числа испытаний, в которых событие произошло, к общему числу произведенных
испытаний. Такая вероятность называется статистической частотой.
Связь
между эмпирической функцией распределения и функцией распределения
(теоретической функцией распределения) такая же, как связь между частотой события
и его вероятностью.
Для
построения выборочной функции распределения весь диапазон изменения случайной
величины X (выборки)
разбивают на ряд интервалов (карманов) одинаковой ширины. Число интервалов
обычно выбирают не менее 3 и не более 15. Затем определяют число значений
случайной величины X, попавших
в каждый интервал (абсолютная частота, частота интервалов).
Частота интервалов – число, показывающее сколько раз значения,
относящиеся к каждому интервалу группировки, встречаются в выборке. Поделив эти
числа на общее количество наблюдений (n), находят относительную частоту (частость) попадания
случайной величины X в заданные
интервалы.
По
найденным относительным частотам строят гистограммы выборочных функций
распределения. Гистограмма распределения частот – это графическое
представление выборки, где по оси абсцисс (ОХ) отложены величины интервалов, а
по оси ординат (ОУ) – величины частот, попадающих в данный классовый интервал.
При увеличении до бесконечности размера выборки выборочные функции
распределения превращаются в теоретические: гистограмма превращается в график
плотности распределения.
Накопленная частота интервалов – это число, полученное
последовательным суммированием частот в направлении от первого интервала к
последнему, до того интервала
включительно, для которого определяется накопленная частота.
В Excel для построения выборочных функций распределения
используются специальная функция ЧАСТОТА
и процедура Гистограмма из пакета анализа.
Функция ЧАСТОТА (массив_данных,
двоичный_массив) вычисляет частоты появления случайной величины в интервалах
значений и выводит их как массив цифр, где
•
массив_данных
— это массив или ссылка на
множество данных, для которых
вычисляются частоты;
•
двоичный_массив
— это массив интервалов, по
которым группируются значения выборки.
Процедура
Гистограмма из Пакета анализа выводит
результаты выборочного распределения в виде таблицы и графика. Параметры диалогового окна Гистограмма:
•
Входной диапазон — диапазон исследуемых данных
(выборка);
•
Интервал карманов — диапазон ячеек или набор граничных
значений, определяющих выбранные интервалы (карманы). Эти значения должны быть
введены в возрастающем порядке. Если
диапазон карманов не был введен, то набор интервалов, равномерно распределенных между минимальным и
максимальным значениями данных, будет создан
автоматически.
•
выходной диапазон предназначен для ввода ссылки на левую верхнюю ячейку выходного диапазона.
•
переключатель
Интегральный процент позволяет установить режим включения в
гистограмму графика интегральных
процентов.
•
переключатель
Вывод графика позволяет установить режим автоматического создания встроенной диаграммы на листе, содержащем
выходной диапазон.
Пример 1. Построить эмпирическое распределение веса
студентов в килограммах для следующей
выборки: 64, 57, 63, 62, 58, 61, 63, 70, 60, 61, 65, 62, 62, 40, 64, 61, 59, 59, 63, 61.
Решение
1. В ячейку А1 введите слово Наблюдения,
а в диапазон А2:А21 — значения веса
студентов (см. рис. 1).
2.
В
ячейку В1 введите названия интервалов Вес, кг. В диапазон В2:В8 введите
граничные значения интервалов (40, 45,
50, 55, 60, 65, 70).
3.
Введите
заголовки создаваемой таблицы: в ячейки С1 — Абсолютные частоты, в ячейки D1 — Относительные
частоты, в ячейки E1 — Накопленные частоты.(см. рис. 1).
4.
С
помощью функции Частота заполните столбец абсолютных частот, для этого
выделите блок ячеек С2:С8. С
панели инструментов Стандартная
вызовите Мастер функций (кнопка fx). В появившемся диалоговом окне
выберите категорию Статистические и функцию
ЧАСТОТА, после чего нажмите кнопку ОК. Указателем мыши в рабочее поле Массив_данных
введите диапазон данных наблюдений (А2:А8). В рабочее поле Двоичный_массив
мышью введите диапазон интервалов (В2:В8). Слева на клавиатуре последовательно нажмите комбинацию клавиш Ctrl+Shift+Enter. В столбце C должен появиться массив абсолютных частот (см. рис.1).
5.
В
ячейке C9 найдите общее количество
наблюдений. Активизируйте ячейку С9, на
панели инструментов Стандартная нажмите кнопку Автосумма.
Убедитесь, что диапазон суммирования указан правильно и нажмите клавишу Enter.
6.
Заполните столбец относительных частот. В ячейку введите формулу
для вычисления относительной частоты: =C2/$C$9.
Нажмите клавишу Enter. Протягиванием (за правый
нижний угол при нажатой левой кнопке мыши) скопируйте введенную формулу в диапазон и получите массив относительных частот.
7.
Заполните
столбец накопленных частот. В ячейку D2 скопируйте значение относительной
частоты из ячейки E2. В ячейку D3 введите формулу: =E2+D3. Нажмите клавишу Enter. Протягиванием (за правый нижний угол при нажатой левой кнопке мыши) скопируйте введенную формулу
в диапазон D3:D8. Получим массив накопленных
частот.

Рис. 1. Результат вычислений из
примера 1
8.
Постройте диаграмму относительных и накопленных частот. Щелчком указателя
мыши по кнопке на панели инструментов вызовите Мастер диаграмм. В появившемся диалоговом окне выберите закладку Нестандартные
и тип диаграммы График/гистограмма. После
редактирования диаграмма будет иметь такой вид, как на рис. 2.

Рис. 2
Диаграмма относительных и накопленных частот из примера 1
Задания для самостоятельной работы
1. Для данных из примера 1 построить выборочные функции распределения, воспользовавшись процедурой Гистограмма из пакета Анализа.
2. Построить выборочные функции распределения
(относительные и накопленные частоты) для роста
в см. 20 студентов: 181, 169, 178, 178, 171, 179, 172, 181, 179, 168, 174, 167, 169, 171, 179, 181, 181,
183, 172, 176.
3. Найдите распределение по абсолютным частотам для
следующих результатов тестирования в
баллах: 79, 85, 78, 85, 83, 81, 95, 88, 97, 85 (используйте границы интервалов 70, 80, 90).
4. Рассмотрим любой из критериев оценки качеств педагога-профессионала,
например, «успешное решение задач обучения и воспитания». Ответ на этот вопрос
анкеты типа «да», «нет» достаточно груб. Чтобы уменьшить относительную ошибку
такого измерения, необходимо увеличить число возможных ответов на конкретный
критериальный вопрос. В табл. 1 представлены возможные варианты ответов.
Обозначим
этот параметр через х. Тогда в процессе ответа на вопрос величина х
примет дискретное значение х, принадлежащее определенному интервалу значений.
Поставим в соответствие каждому из ответов определенное числовое значение
параметра х (см. табл. 1).
Табл. 1 Критериальный вопрос: успешное решение задач обучения и воспитания
|
№ п/п |
Варианты ответов |
Х |
|
1 |
Абсолютно неуспешно |
0,1 |
|
2 |
Неуспешно |
0,2 |
|
3 |
Успешно в очень |
0,3 |
|
4 |
В определенной |
0,4 |
|
5 |
В среднем успешно, |
0,5 |
|
6 |
Успешно с |
0,6 |
|
7 |
Успешно, но |
0,7 |
|
8 |
Достаточно успешно |
0,8 |
|
9 |
Очень успешно |
0,9 |
|
10 |
Абсолютно успешно |
1 |
При проведении анкетирования в каждой отдельной
анкете параметр х принимает случайное значение, но только в пределах числового
интервала от 0,1 до 1.
Тогда в результате измерений мы получаем
неранжированный ряд случайных значений (см. табл. 2).
Таблица 2.
Результаты опроса ста учителей

Сгруппируйте полученную выборку, рассчитайте среднее
значение выборки, стандартное отклонение, абсолютную и относительную частоту
появления параметра, а также постройте график плотности вероятности f(x)=

где
W(x) – относительная частота наступления события;

— стандартное
отклонение;

=3,14.
Постройте график функции f(x) и сравните его с
нормальным распределением Гаусса.
Решение математических задач
средствами Excel: Практикум/ В.Я. Гельман. – СПб.: Питер, 2003 — с. 168-172
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Еще…Меньше
Возвращает нормальную функцию распределения для указанного среднего и стандартного отклонения. Эта функция очень широко применяется в статистике, в том числе при проверке гипотез.
Важно: Эта функция была заменена одной или несколькими новыми функциями, которые обеспечивают более высокую точность и имеют имена, лучше отражающие их назначение. Хотя эта функция все еще используется для обеспечения обратной совместимости, она может стать недоступной в последующих версиях Excel, поэтому мы рекомендуем использовать новые функции.
Дополнительные сведения о новом варианте этой функции см. в статье Функция НОРМ.РАСП.
Синтаксис
НОРМРАСП(x;среднее;стандартное_откл;интегральная)
Аргументы функции НОРМРАСП описаны ниже.
-
X Обязательный. Значение, для которого строится распределение.
-
Среднее Обязательный. Среднее арифметическое распределения.
-
Стандартное_откл Обязательный. Стандартное отклонение распределения.
-
Интегральная — обязательный аргумент. Логическое значение, определяющее форму функции. Если аргумент «интегральная» имеет значение ИСТИНА, функция НОРМРАСП возвращает интегральную функцию распределения; если этот аргумент имеет значение ЛОЖЬ, возвращается весовая функция распределения.
Замечания
-
Если «standard_dev» не является числом, то возвращается #VALUE! значение ошибки #ЗНАЧ!.
-
Если standard_dev ≤ 0, то нормДАТ возвращает #NUM! значение ошибки #ЗНАЧ!.
-
Если среднее = 0, стандартное_откл = 1 и интегральная = ИСТИНА, то функция НОРМРАСП возвращает стандартное нормальное распределение, т. е. НОРМСТРАСП.
-
Уравнение для плотности нормального распределения (аргумент «интегральная» содержит значение ЛОЖЬ) имеет следующий вид:

-
Если аргумент «интегральная» имеет значение ИСТИНА, формула описывает интеграл с пределами от минус бесконечности до x.
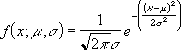
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Данные |
Описание |
|
|
42 |
Значение, для которого нужно вычислить распределение |
|
|
40 |
Среднее арифметическое распределения |
|
|
1,5 |
Стандартное отклонение распределения |
|
|
Формула |
Описание |
Результат |
|
=НОРМРАСП(A2;A3;A4;ИСТИНА) |
Интегральная функция распределения для приведенных выше условий |
0,9087888 |
|
=НОРМРАСП(A2;A3;A4;ЛОЖЬ) |
Функция плотности распределения для приведенных выше условий |
0,10934 |
Нужна дополнительная помощь?
События,
характеризующие данные, могут носить
случайный характер и появляться с разной
вероятностью.
Вероятность
события p
есть отношение числа благоприятных
исходов m
к числу всех возможных исходов n
этого
события:
p=m/n.
Например, вероятность появления туза
в наугад выбранной карте из колоды в 52
карты равна 4/52=0.0769, так как m=4,
а n=52.
Если
известно соответствие между появлениями
(величинами) x1,
x2,
…, xn
случайного события (переменной)
X
и
соответствующими вероятностями их
реализации p1,
p2,
…, pn,
то говорят, что известен закон
распределения случайной величины
F(x).
Большинство встречающихся на практике
распределений вероятностей реализовано
в Excel.
Распределения
вероятностей имеют числовые характеристики.
Функции
Excel
для вычисления числовых характеристик
распределения вероятностей. Они входят
в группу Статистические.
При вычислении функций в качестве
случайных величин используйте следующие
значения:

Математическое
ожидание
случайной величины (среднее арифметическое),
характеризующее центр распределения
вероятностей, вычисляется функцией
СРЗНАЧ. СРЗНАЧ(A1:A7)
= 9.
Дисперсия,
характеризует разброс случайной величины
относительно центра распределения
вероятностей и вычисляется функцией
ДИСПР. ДИСПР(A1:A7)
= 4.857.
Среднеквадратичное
отклонение
есть квадратный корень из дисперсии,
характеризует разброс случайной величины
в единицах случайной величины и
вычисляется функцией СТАНДОТКЛОНП.
СТАНДОТКЛОНП(A1:A7) = 2.203893.
Квантиль
случайной величины с законом распределения
F(x)
есть значение случайной величины x
при заданной вероятности p.,
т.е. есть решение уравнения F(x)=p.
Медиана
есть квантиль с вероятностью p=0.5.
Excel,
вместо квантилей содержит функции
вычисления х
для определенных уровней р:
квартили
(кварта – четверть), децили
(дециль
– десятая часть),
персентили
(персент – процент). Различают нижний
квартиль с вероятностью p=0.25
и верхний квартиль с вероятностью
p=0.75.
Децили это квантили с вероятностью 0.1,
0.2, …, 0.9.
Функцию
КВАРТИЛЬ используют, чтобы разбить
данные на группы. В качестве второго
аргумента указывают уровень (четверть),
для которого нужно вернуть решение: 0 –
минимальное значение распределения, 1
– первый, нижний квартиль, 2 – медиана,
3 – третий, верхний квартиль, 4 –
максимальное значение. Например,
КВАРТИЛЬ(A1:A7;3)
= 10, т.е. 75% всех значений меньше 10,
КВАРТИЛЬ(A1:A7;2) = 9.
Функция
ПЕРСЕНТИЛЬ вычисляет квантиль указанного
уровня вероятности и используется для
определения порога приемлемости
значений. В качестве второго аргумента
указывают уровень 0.1, 0.2, …, 0.9.
ПЕРСЕНТИЛЬ(A1:A7;0,9) = 11.8, т.е. 90% всех значений
меньше 11.8.
Excel
содержит инструмент Ранг
и персентиль,
который на основе набора данных формирует
выходную таблицу, содержащую порядковый
и процентный ранги для каждого значения
в наборе данных. См. справку по F1.
Ниже приведен пример установки надстройки
Пактет
анализа

Распределения
вероятностей, реализованные в Excel.
Каждый
закон распределения описывает процессы
разной вероятностной природы и
характеризуется специфическими
параметрами:
-
равномерное
распределение
– n
случайных чисел выпадает с одной и той
же вероятностью p=1/n;
характеризуется нижней и верхней
границей; примером является появление
чисел 1, 2, …, 6 при бросании игральной
кости (p=1/6); -
биномиальное
распределение
моделирует взаимосвязь числа успешных
испытаний m
и вероятностей успеха каждого испытания
p
при общем количестве испытаний n
— функции БИНОМРАСП и КРИТБИНОМ; -
нормальное
(гауссово) распределение
описывает процессы, в которых на
результат воздействует большое число
независимых случайных факторов, среди
которых нет сильно выделяющихся –
функции НОРМРАСП, НОРМСТРАСП, НОРМОБР,
НОРМСТОБР и НОРМАЛИЗАЦИЯ; -
распределение
Пуассона, предсказывает
число случайных событий на определенном
отрезке времени или на определенном
пространстве, позволяет аппроксимировать
биномиальное распределение – функция
ПУАССОН; -
экспоненциальное
(показательное) распределение,
моделирует временные задержки между
событиями, описывает процессы в задачах
массового обслуживания и в задачах с
«временем жизни» — ЭКСПРАСП; -
распределение
хи-квадрат,
связано с нормальным, возвращает
одностороннюю вероятность распределения
и используется для сравнения предполагаемых
и наблюдаемых значений – функция
ХИ2РАСП; -
распределение
Стьюдента,
связано с нормальным, возвращает
вероятность для t-распределения Стьюдента
и используется для проверки гипотез
при малом объеме выборки – функция
СТЬЮДРАСП; -
F-распределение
(Фишера), связано с нормальным и может
быть использовано в F-тесте, который
сравнивает степени разброса двух
множеств данных – fраспобр; -
гамма-распределение
используется для изучения случайных
величин, имеющих асимметричное
распределение, в теории очередей –
функция ГАММАРАСП; -
а
также другие распределения – функции
БЕТАРАСП, ВЕЙБУЛЛ, ОТРБИНОМРАСП,
ГИПЕРГЕОМЕТ, ЛОГНОРМРАСП и др.
Биномиальное
распределение
характеризуется
числом успешных испытаний m,
вероятностью успеха каждого испытания
p
и общим количеством испытаний n.
Классическим примером использования
биномиального распределения является
выборочный контроль качества больших
партий товара, изделий в торговле, на
производстве, когда сплошная проверка
невозможна. Из партии выбирают n
образцов и регистрируют число бракованных
m.
Бракованными могут быть 1, 2, … , n
образцов, но вероятности реального
числа бракованных будут различными.
Если контрольная вероятность брака
ниже допустимой вероятности, то можно
гарантировать достаточное качество
всей партии.
В
Excel
функция БИНОМРАСП вычисляет вероятность
отдельного значения распределения по
заданным m,
n
и р,
а функция КРИТБИНОМ – случайное число
по заданной вероятности. Обычно функция
КРИТБИНОМ используется для определения
наибольшего допустимого числа брака.
В
качестве примера построим график
плотности вероятности биномиального
распределения для n=10
(1, 2, …, 10) и p=0.2.
Введите исходные данные, как показано
на рисунке:

Далее
в ячейку В4 введите статистическую
функцию БИНОМРАСП и заполните ее
параметры как показано на рисунке:

Здесь
параметр Число_s
есть число успешных испытаний m,
Испытания
– число независимых испытаний n,
Вероятность_s
–
вероятность успеха каждого испытания
p.
Параметр Интегральный
равен 0, если требуется получить плотность
распределения (вероятность для значения
m),
и равен 1, если требуется получить
вероятность с накоплением (вероятность
того, что число успешных испытаний не
меньше значения аргумента Число_s).
Формулу
из В4 размножьте в ячейки В5:В13. Ниже
показан результат:

В
колонке В вычислены вероятности успешных
испытаний m=1,
2, …, 10. Теперь по диапазону В4:В13 постройте
график или гистограмму биномиальной
функции плотности распределения –
результат на рисунке. Поэкспериментируйте,
изменяя значение вероятности в ячейке
В1: 0.3, 0.4, 0.8, проследите за изменениями
формы графика.

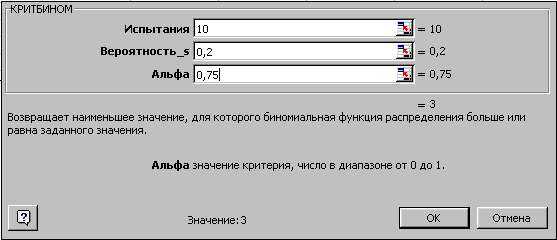
Для
иллюстрации функции КРИТБИНОМ используем
предыдущий пример – необходимо найти
число m,
для которого вероятность интегрального
распределения больше или равна 0.75.
Вызовите функцию КРИТБИНОМ и заполните
параметры. Вы должны получить значение
3. Это означает, что при вероятности
интегрального распределения >= 0.75
будет не менее трех (m>=3)
успешных испытаний.
Нормальное
распределение
характеризуется
средним арифметическим (математическим
ожиданием) m
и стандартным (среднеквадратичным)
отклонением r.
Дисперсия равна r2.
Краткое обозначение распределения
N(m,r2).
График нормального распределения
симметричен относительно центра
распределения (точки m),
чем меньше r,
тем больше вероятность появления
случайной величины. В пределы [m—r,m+r]
нормально распределенная случайная
величина попадает с вероятностью 0,683 в
пределы [m-2r,m+2r]
— с вероятностью 0,955 и т.д.

При
m=0
и r=1
нормальное распределение называется
стандартным
или нормированным – N(0,1).
Нормальное
распределение имеет очень широкий круг
приложений. В качестве примера построим
график плотности вероятностей нормального
распределения при m=15
и r=1,5
в диапазоне [m-3r,m+3r]
c
шагом 0,5. Результат показан на рисунке.

Выполните
следующие действия:
-
в
ячейку А4 введите формулу =B1-3*B2, в ячейку
А5 формулу =A4+B$3 и размножьте ее по ячейку
А22; -
в
ячейку В4 введите функцию НОРМРАСП из
группы Статистические
– параметры заполните как на рисунке; -
размножьте
формулу из ячейки В4 по ячейку В22 и по
диапазону В4:В22 постройте график; на
2-ом шаге мастера диаграмм в закладке
Ряд
введите подписи к оси х
из диапазона А4:А22.

Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #