
Чтобы просмотреть более подробные сведения о функции, щелкните ее название в первом столбце.
Примечание: Маркер версии обозначает версию Excel, в которой она впервые появилась. В более ранних версиях эта функция отсутствует. Например, маркер версии 2013 означает, что данная функция доступна в выпуске Excel 2013 и всех последующих версиях.
|
Функция |
Описание |
|
СРОТКЛ |
Возвращает среднее арифметическое абсолютных значений отклонений точек данных от среднего. |
|
СРЗНАЧ |
Возвращает среднее арифметическое аргументов. |
|
СРЗНАЧА |
Возвращает среднее арифметическое аргументов, включая числа, текст и логические значения. |
|
СРЗНАЧЕСЛИ |
Возвращает среднее значение (среднее арифметическое) всех ячеек в диапазоне, которые удовлетворяют заданному условию. |
|
СРЗНАЧЕСЛИМН |
Возвращает среднее значение (среднее арифметическое) всех ячеек, которые удовлетворяют нескольким условиям. |
|
БЕТА.РАСП |
Возвращает интегральную функцию бета-распределения. |
|
БЕТА.ОБР |
Возвращает обратную интегральную функцию указанного бета-распределения. |
|
БИНОМ.РАСП |
Возвращает отдельное значение вероятности биномиального распределения. |
|
БИНОМ.РАСП.ДИАП |
Возвращает вероятность пробного результата с помощью биномиального распределения. |
|
БИНОМ.ОБР |
Возвращает наименьшее значение, для которого интегральное биномиальное распределение меньше заданного значения или равно ему. |
|
ХИ2.РАСП |
Возвращает интегральную функцию плотности бета-вероятности. |
|
ХИ2.РАСП.ПХ |
Возвращает одностороннюю вероятность распределения хи-квадрат. |
|
ХИ2.ОБР |
Возвращает интегральную функцию плотности бета-вероятности. |
|
ХИ2.ОБР.ПХ |
Возвращает обратное значение односторонней вероятности распределения хи-квадрат. |
|
ХИ2.ТЕСТ |
Возвращает тест на независимость. |
|
ДОВЕРИТ.НОРМ |
Возвращает доверительный интервал для среднего значения по генеральной совокупности. |
|
ДОВЕРИТ.СТЬЮДЕНТ |
Возвращает доверительный интервал для среднего генеральной совокупности, используя t-распределение Стьюдента. |
|
КОРРЕЛ |
Возвращает коэффициент корреляции между двумя множествами данных. |
|
СЧЁТ |
Подсчитывает количество чисел в списке аргументов. |
|
СЧЁТЗ |
Подсчитывает количество значений в списке аргументов. |
|
СЧИТАТЬПУСТОТЫ |
Подсчитывает количество пустых ячеек в диапазоне. |
|
СЧЁТЕСЛИ |
Подсчитывает количество ячеек в диапазоне, удовлетворяющих заданному условию. |
|
СЧЁТЕСЛИМН |
Подсчитывает количество ячеек внутри диапазона, удовлетворяющих нескольким условиям. |
|
КОВАРИАЦИЯ.Г |
Возвращает ковариацию, среднее произведений парных отклонений. |
|
КОВАРИАЦИЯ.В |
Возвращает ковариацию выборки — среднее попарных произведений отклонений для всех точек данных в двух наборах данных. |
|
КВАДРОТКЛ |
Возвращает сумму квадратов отклонений. |
|
ЭКСП.РАСП |
Возвращает экспоненциальное распределение. |
|
F.РАСП |
Возвращает F-распределение вероятности. |
|
F.РАСП.ПХ |
Возвращает F-распределение вероятности. |
|
F.ОБР |
Возвращает обратное значение для F-распределения вероятности. |
|
F.ОБР.ПХ |
Возвращает обратное значение для F-распределения вероятности. |
|
F.ТЕСТ |
Возвращает результат F-теста. |
|
ФИШЕР |
Возвращает преобразование Фишера. |
|
ФИШЕРОБР |
Возвращает обратное преобразование Фишера. |
|
ПРЕДСКАЗ |
Возвращает значение линейного тренда. Примечание: В Excel 2016 эта функция заменена на ПРЕДСКАЗ.ЛИНЕЙН из нового набора функций прогнозирования. Однако она по-прежнему доступна для совместимости с предыдущими версиями. |
|
ПРЕДСКАЗ.ETS |
Возвращает будущее значение на основе существующих (ретроспективных) данных с использованием версии AAA алгоритма экспоненциального сглаживания (ETS). |
|
ПРЕДСКАЗ.ЕTS.ДОВИНТЕРВАЛ |
Возвращает доверительный интервал для прогнозной величины на указанную дату. |
|
ПРЕДСКАЗ.ETS.СЕЗОННОСТЬ |
Возвращает длину повторяющегося фрагмента, обнаруженного программой Excel в заданном временном ряду. |
|
ПРЕДСКАЗ.ETS.СТАТ |
Возвращает статистическое значение, являющееся результатом прогнозирования временного ряда. |
|
ПРЕДСКАЗ.ЛИНЕЙН |
Возвращает будущее значение на основе существующих значений. |
|
ЧАСТОТА |
Возвращает распределение частот в виде вертикального массива. |
|
ГАММА |
Возвращает значение функции гамма |
|
ГАММА.РАСП |
Возвращает гамма-распределение. |
|
ГАММА.ОБР |
Возвращает обратное значение интегрального гамма-распределения. |
|
ГАММАНЛОГ |
Возвращает натуральный логарифм гамма-функции, Γ(x). |
|
ГАММАНЛОГ.ТОЧН |
Возвращает натуральный логарифм гамма-функции, Γ(x). |
|
ГАУСС |
Возвращает значение на 0,5 меньше стандартного нормального распределения. |
|
СРГЕОМ |
Возвращает среднее геометрическое. |
|
РОСТ |
Возвращает значения в соответствии с экспоненциальным трендом. |
|
СРГАРМ |
Возвращает среднее гармоническое. |
|
ГИПЕРГЕОМ.РАСП |
Возвращает гипергеометрическое распределение. |
|
ОТРЕЗОК |
Возвращает отрезок, отсекаемый на оси линией линейной регрессии. |
|
ЭКСЦЕСС |
Возвращает эксцесс множества данных. |
|
НАИБОЛЬШИЙ |
Возвращает k-ое наибольшее значение в множестве данных. |
|
ЛИНЕЙН |
Возвращает параметры линейного тренда. |
|
ЛГРФПРИБЛ |
Возвращает параметры экспоненциального тренда. |
|
ЛОГНОРМ.РАСП |
Возвращает интегральное логарифмическое нормальное распределение. |
|
ЛОГНОРМ.ОБР |
Возвращает обратное значение интегрального логарифмического нормального распределения. |
|
МАКС |
Возвращает наибольшее значение в списке аргументов. |
|
МАКСА |
Возвращает наибольшее значение в списке аргументов, включая числа, текст и логические значения. |
|
МАКСЕСЛИ |
Возвращает максимальное значение из заданных определенными условиями или критериями ячеек. |
|
МЕДИАНА |
Возвращает медиану заданных чисел. |
|
МИН |
Возвращает наименьшее значение в списке аргументов. |
|
МИНЕСЛИ |
Возвращает минимальное значение из заданных определенными условиями или критериями ячеек. |
|
МИНА |
Возвращает наименьшее значение в списке аргументов, включая числа, текст и логические значения. |
|
МОДА.НСК |
Возвращает вертикальный массив наиболее часто встречающихся или повторяющихся значений в массиве или диапазоне данных. |
|
МОДА.ОДН |
Возвращает значение моды набора данных. |
|
ОТРБИНОМ.РАСП |
Возвращает отрицательное биномиальное распределение. |
|
НОРМ.РАСП |
Возвращает нормальное интегральное распределение. |
|
НОРМ.ОБР |
Возвращает обратное значение нормального интегрального распределения. |
|
НОРМ.СТ.РАСП |
Возвращает стандартное нормальное интегральное распределение. |
|
НОРМ.СТ.ОБР |
Возвращает обратное значение стандартного нормального интегрального распределения. |
|
ПИРСОН |
Возвращает коэффициент корреляции Пирсона. |
|
ПРОЦЕНТИЛЬ.ИСКЛ |
Возвращает k-ю процентиль для значений диапазона, где k — число от 0 и 1 (не включая эти числа). |
|
ПРОЦЕНТИЛЬ.ВКЛ |
Возвращает k-ю процентиль для значений диапазона. |
|
ПРОЦЕНТРАНГ.ИСКЛ |
Возвращает ранг значения в наборе данных как процентную долю набора (от 0 до 1, исключая границы). |
|
ПРОЦЕНТРАНГ.ВКЛ |
Возвращает процентную норму значения в наборе данных. |
|
ПЕРЕСТ |
Возвращает количество перестановок для заданного числа объектов. |
|
ПЕРЕСТА |
Возвращает количество перестановок для заданного числа объектов (с повторами), которые можно выбрать из общего числа объектов. |
|
ФИ |
Возвращает значение функции плотности для стандартного нормального распределения. |
|
ПУАССОН.РАСП |
Возвращает распределение Пуассона. |
|
ВЕРОЯТНОСТЬ |
Возвращает вероятность того, что значение из диапазона находится внутри заданных пределов. |
|
КВАРТИЛЬ.ИСКЛ |
Возвращает квартиль набора данных на основе значений процентили из диапазона от 0 до 1, исключая границы. |
|
КВАРТИЛЬ.ВКЛ |
Возвращает квартиль набора данных. |
|
РАНГ.СР |
Возвращает ранг числа в списке чисел. |
|
РАНГ.РВ |
Возвращает ранг числа в списке чисел. |
|
КВПИРСОН |
Возвращает квадрат коэффициента корреляции Пирсона. |
|
СКОС |
Возвращает асимметрию распределения. |
|
СКОС.Г |
Возвращает асимметрию распределения на основе заполнения: характеристика степени асимметрии распределения относительно его среднего. |
|
НАКЛОН |
Возвращает наклон линии линейной регрессии. |
|
НАИМЕНЬШИЙ |
Возвращает k-ое наименьшее значение в множестве данных. |
|
НОРМАЛИЗАЦИЯ |
Возвращает нормализованное значение. |
|
СТАНДОТКЛОН.Г |
Вычисляет стандартное отклонение по генеральной совокупности. |
|
СТАНДОТКЛОН.В |
Оценивает стандартное отклонение по выборке. |
|
СТАНДОТКЛОНА |
Оценивает стандартное отклонение по выборке, включая числа, текст и логические значения. |
|
СТАНДОТКЛОНПА |
Вычисляет стандартное отклонение по генеральной совокупности, включая числа, текст и логические значения. |
|
СТОШYX |
Возвращает стандартную ошибку предсказанных значений y для каждого значения x в регрессии. |
|
СТЬЮДРАСП |
Возвращает процентные точки (вероятность) для t-распределения Стьюдента. |
|
СТЬЮДЕНТ.РАСП.2Х |
Возвращает процентные точки (вероятность) для t-распределения Стьюдента. |
|
СТЬЮДЕНТ.РАСП.ПХ |
Возвращает t-распределение Стьюдента. |
|
СТЬЮДЕНТ.ОБР |
Возвращает значение t для t-распределения Стьюдента как функцию вероятности и степеней свободы. |
|
СТЬЮДЕНТ.ОБР.2Х |
Возвращает обратное t-распределение Стьюдента. |
|
СТЬЮДЕНТ.ТЕСТ |
Возвращает вероятность, соответствующую проверке по критерию Стьюдента. |
|
ТЕНДЕНЦИЯ |
Возвращает значения в соответствии с линейным трендом. |
|
УРЕЗСРЕДНЕЕ |
Возвращает среднее внутренности множества данных. |
|
ДИСП.Г |
Вычисляет дисперсию по генеральной совокупности. |
|
ДИСП.В |
Оценивает дисперсию по выборке. |
|
ДИСПА |
Оценивает дисперсию по выборке, включая числа, текст и логические значения. |
|
ДИСПРА |
Вычисляет дисперсию для генеральной совокупности, включая числа, текст и логические значения. |
|
ВЕЙБУЛЛ.РАСП |
Возвращает распределение Вейбулла. |
|
Z.ТЕСТ |
Возвращает одностороннее значение вероятности z-теста. |


Важно: Вычисляемые результаты формул и некоторые функции листа Excel могут несколько отличаться на компьютерах под управлением Windows с архитектурой x86 или x86-64 и компьютерах под управлением Windows RT с архитектурой ARM. Подробнее об этих различиях.
Статьи по теме
Excel (по категориям)
Excel (по алфавиту)
Содержание
- Статистические функции
- МАКС
- МИН
- СРЗНАЧ
- СРЗНАЧЕСЛИ
- МОДА.ОДН
- МЕДИАНА
- СТАНДОТКЛОН
- НАИБОЛЬШИЙ
- НАИМЕНЬШИЙ
- РАНГ.СР
- Вопросы и ответы

Статистическая обработка данных – это сбор, упорядочивание, обобщение и анализ информации с возможностью определения тенденции и прогноза по изучаемому явлению. В Excel есть огромное количество инструментов, которые помогают проводить исследования в данной области. Последние версии этой программы в плане возможностей практически ничем не уступают специализированным приложениям в области статистики. Главными инструментами для выполнения расчетов и анализа являются функции. Давайте изучим общие особенности работы с ними, а также подробнее остановимся на отдельных наиболее полезных инструментах.
Статистические функции
Как и любые другие функции в Экселе, статистические функции оперируют аргументами, которые могут иметь вид постоянных чисел, ссылок на ячейки или массивы.
Выражения можно вводить вручную в определенную ячейку или в строку формул, если хорошо знать синтаксис конкретного из них. Но намного удобнее воспользоваться специальным окном аргументов, которое содержит подсказки и уже готовые поля для ввода данных. Перейти в окно аргумента статистических выражений можно через «Мастер функций» или с помощью кнопок «Библиотеки функций» на ленте.
Запустить Мастер функций можно тремя способами:
- Кликнуть по пиктограмме «Вставить функцию» слева от строки формул.
- Находясь во вкладке «Формулы», кликнуть на ленте по кнопке «Вставить функцию» в блоке инструментов «Библиотека функций».
- Набрать на клавиатуре сочетание клавиш Shift+F3.
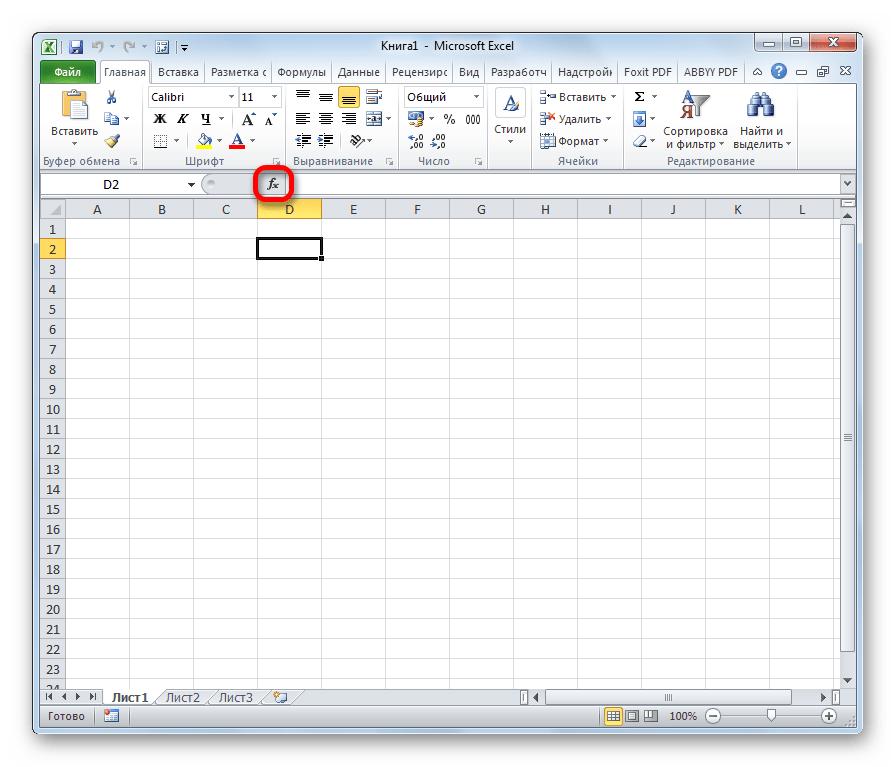

При выполнении любого из вышеперечисленных вариантов откроется окно «Мастера функций».
Затем нужно кликнуть по полю «Категория» и выбрать значение «Статистические».

После этого откроется список статистических выражений. Всего их насчитывается более сотни. Чтобы перейти в окно аргументов любого из них, нужно просто выделить его и нажать на кнопку «OK».

Для того, чтобы перейти к нужным нам элементам через ленту, перемещаемся во вкладку «Формулы». В группе инструментов на ленте «Библиотека функций» кликаем по кнопке «Другие функции». В открывшемся списке выбираем категорию «Статистические». Откроется перечень доступных элементов нужной нам направленности. Для перехода в окно аргументов достаточно кликнуть по одному из них.


Урок: Мастер функций в Excel
МАКС
Оператор МАКС предназначен для определения максимального числа из выборки. Он имеет следующий синтаксис:
=МАКС(число1;число2;…)

В поля аргументов нужно ввести диапазоны ячеек, в которых находится числовой ряд. Наибольшее число из него эта формула выводит в ту ячейку, в которой находится сама.
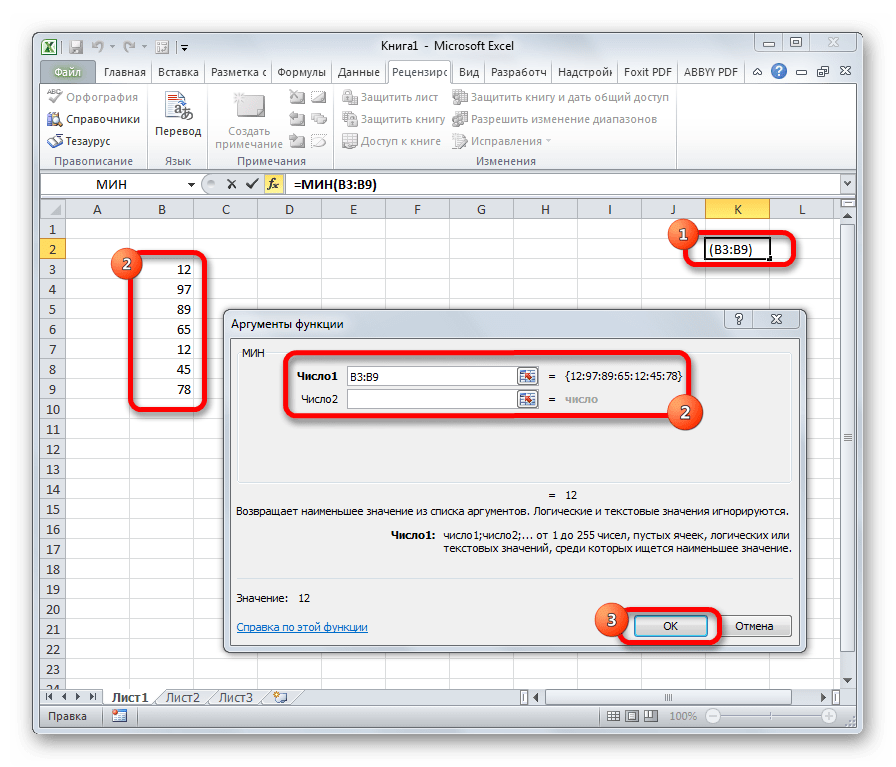
МИН
По названию функции МИН понятно, что её задачи прямо противоположны предыдущей формуле – она ищет из множества чисел наименьшее и выводит его в заданную ячейку. Имеет такой синтаксис:
=МИН(число1;число2;…)
СРЗНАЧ
Функция СРЗНАЧ ищет число в указанном диапазоне, которое ближе всего находится к среднему арифметическому значению. Результат этого расчета выводится в отдельную ячейку, в которой и содержится формула. Шаблон у неё следующий:
=СРЗНАЧ(число1;число2;…)
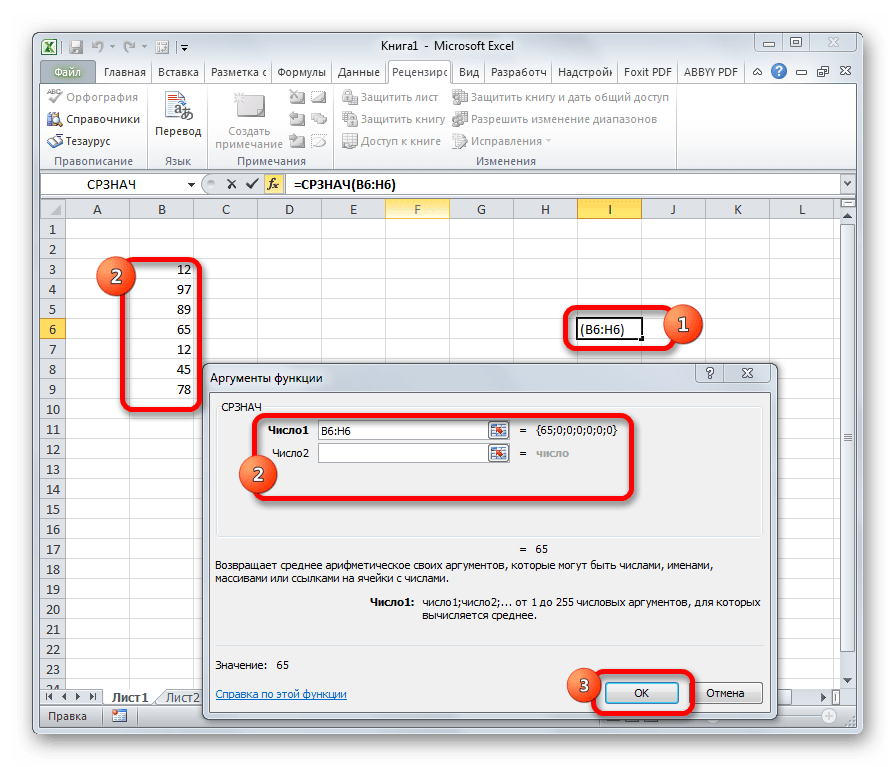
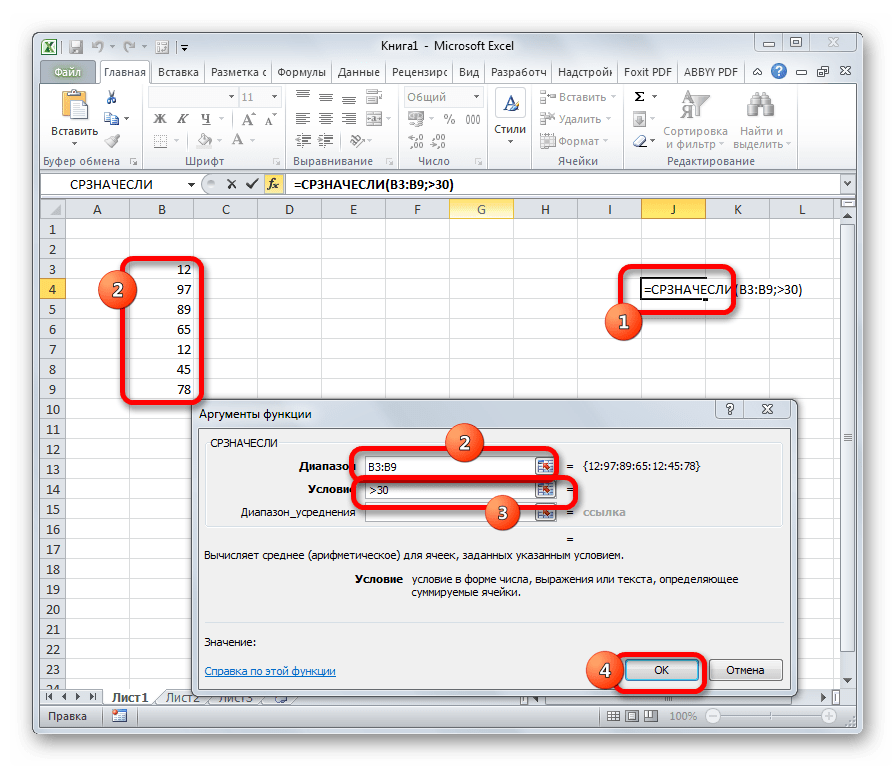
СРЗНАЧЕСЛИ
Функция СРЗНАЧЕСЛИ имеет те же задачи, что и предыдущая, но в ней существует возможность задать дополнительное условие. Например, больше, меньше, не равно определенному числу. Оно задается в отдельном поле для аргумента. Кроме того, в качестве необязательного аргумента может быть добавлен диапазон усреднения. Синтаксис следующий:
=СРЗНАЧЕСЛИ(число1;число2;…;условие;[диапазон_усреднения])
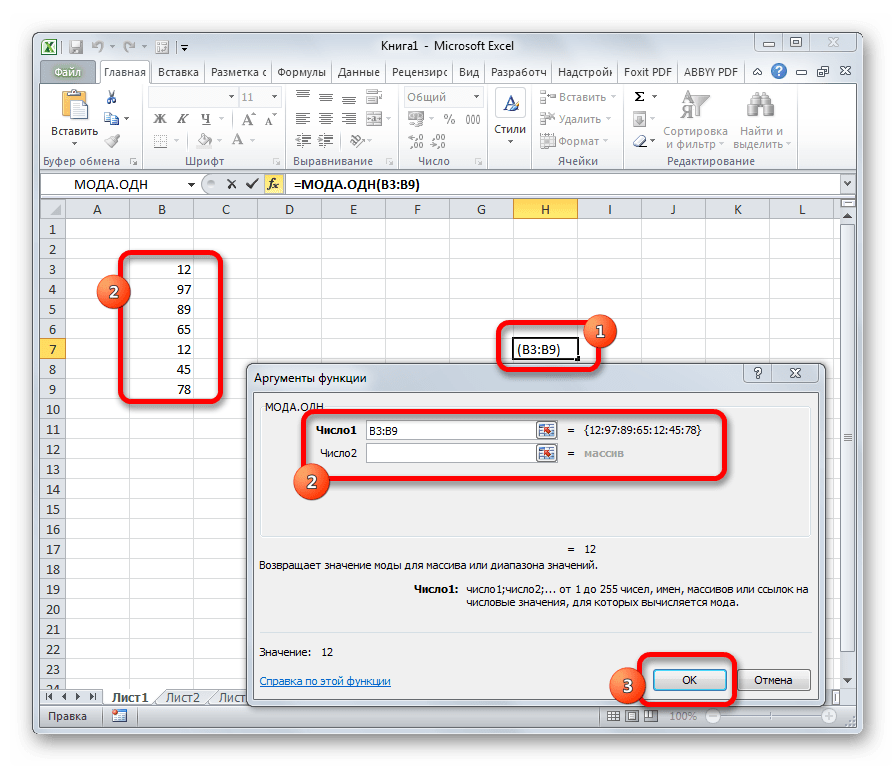
МОДА.ОДН
Формула МОДА.ОДН выводит в ячейку то число из набора, которое встречается чаще всего. В старых версиях Эксель существовала функция МОДА, но в более поздних она была разбита на две: МОДА.ОДН (для отдельных чисел) и МОДА.НСК(для массивов). Впрочем, старый вариант тоже остался в отдельной группе, в которой собраны элементы из прошлых версий программы для обеспечения совместимости документов.
=МОДА.ОДН(число1;число2;…)
=МОДА.НСК(число1;число2;…)
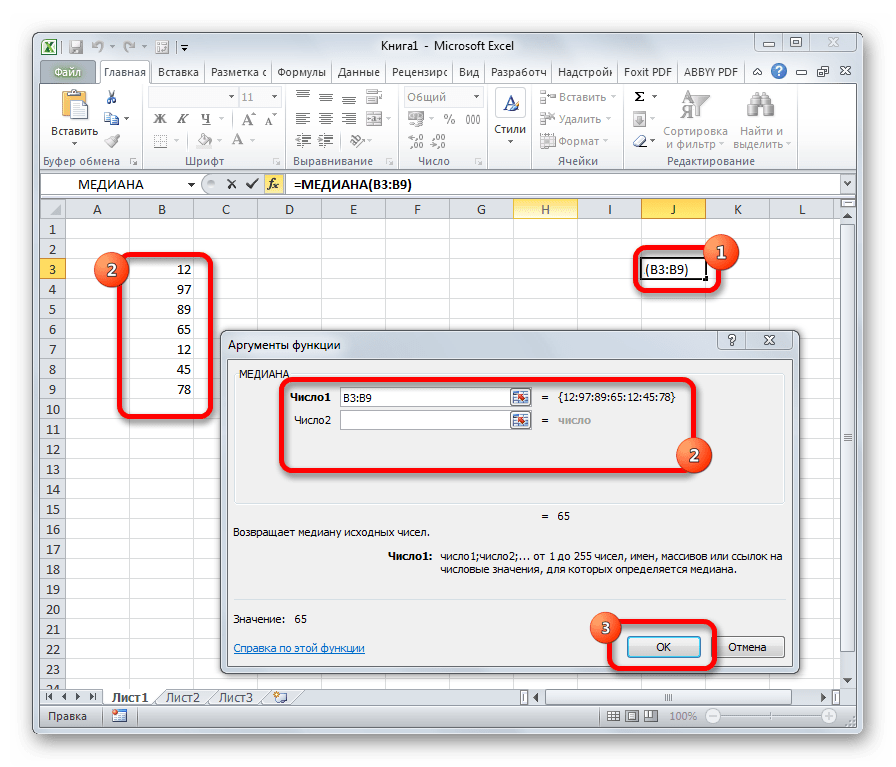
МЕДИАНА
Оператор МЕДИАНА определяет среднее значение в диапазоне чисел. То есть, устанавливает не среднее арифметическое, а просто среднюю величину между наибольшим и наименьшим числом области значений. Синтаксис выглядит так:
=МЕДИАНА(число1;число2;…)
СТАНДОТКЛОН
Формула СТАНДОТКЛОН так же, как и МОДА является пережитком старых версий программы. Сейчас используются современные её подвиды – СТАНДОТКЛОН.В и СТАНДОТКЛОН.Г. Первая из них предназначена для вычисления стандартного отклонения выборки, а вторая – генеральной совокупности. Данные функции используются также для расчета среднего квадратичного отклонения. Синтаксис их следующий:
=СТАНДОТКЛОН.В(число1;число2;…)
=СТАНДОТКЛОН.Г(число1;число2;…)
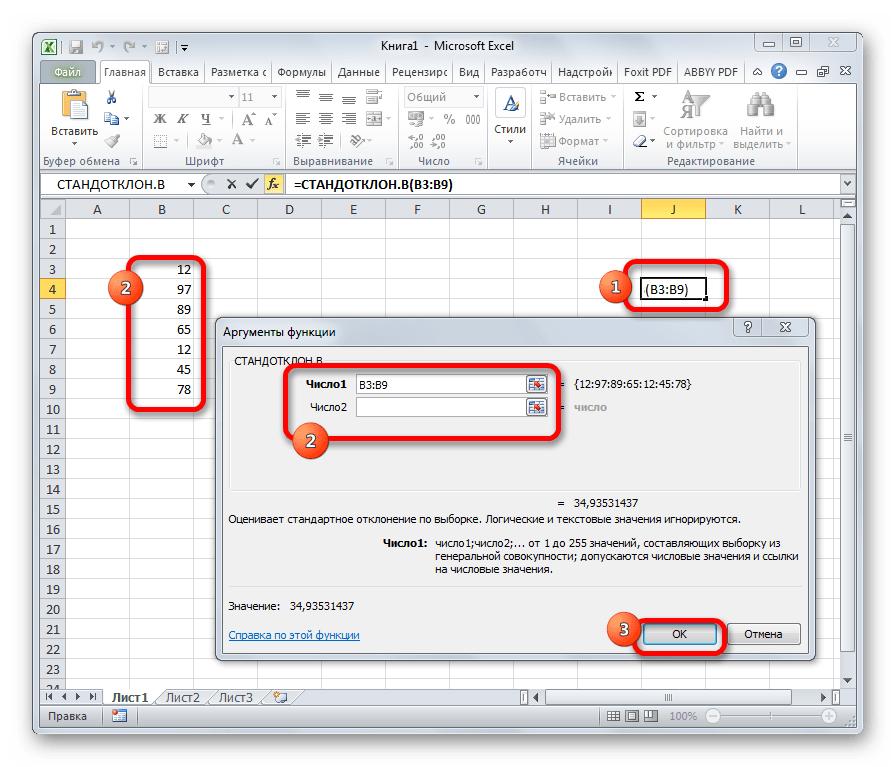
Урок: Формула среднего квадратичного отклонения в Excel
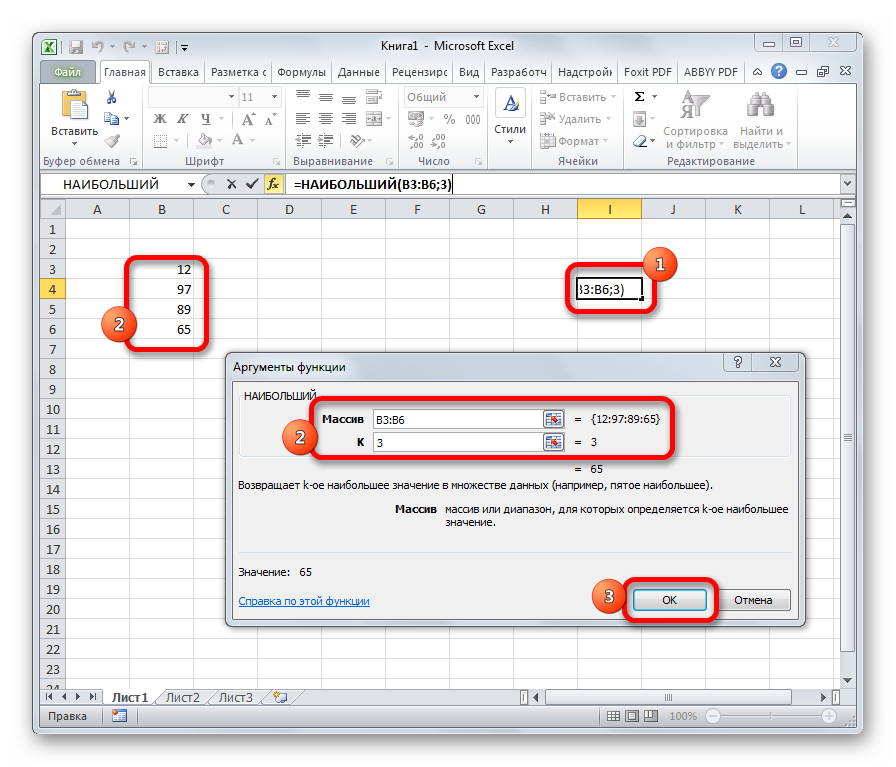
НАИБОЛЬШИЙ
Данный оператор показывает в выбранной ячейке указанное в порядке убывания число из совокупности. То есть, если мы имеем совокупность 12,97,89,65, а аргументом позиции укажем 3, то функция в ячейку вернет третье по величине число. В данном случае, это 65. Синтаксис оператора такой:
=НАИБОЛЬШИЙ(массив;k)
В данном случае, k — это порядковый номер величины.
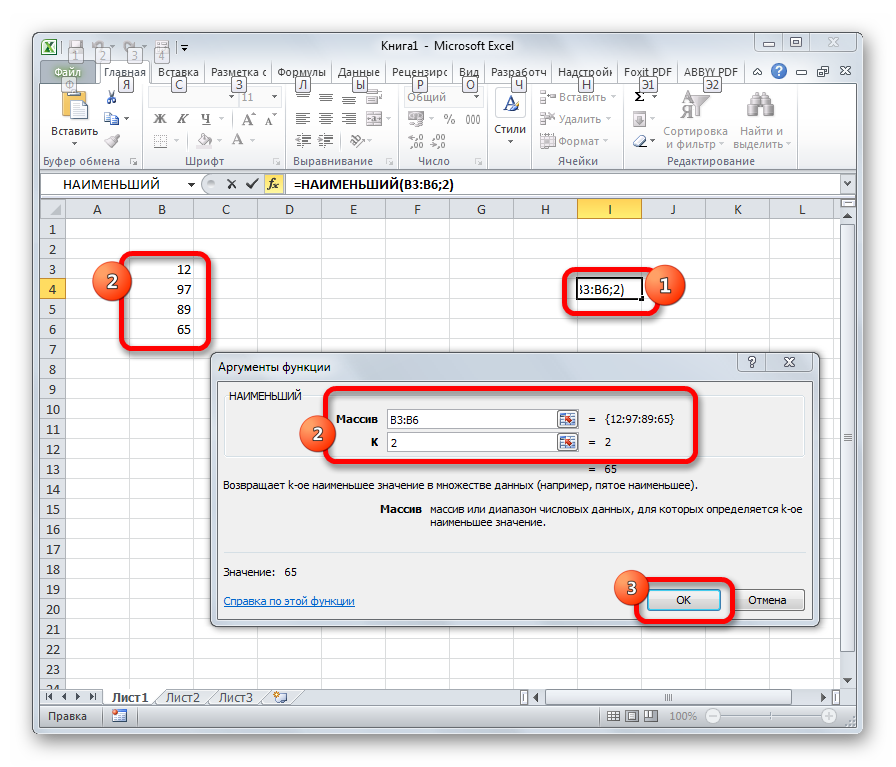
НАИМЕНЬШИЙ
Данная функция является зеркальным отражением предыдущего оператора. В ней также вторым аргументом является порядковый номер числа. Вот только в данном случае порядок считается от меньшего. Синтаксис такой:
=НАИМЕНЬШИЙ(массив;k)
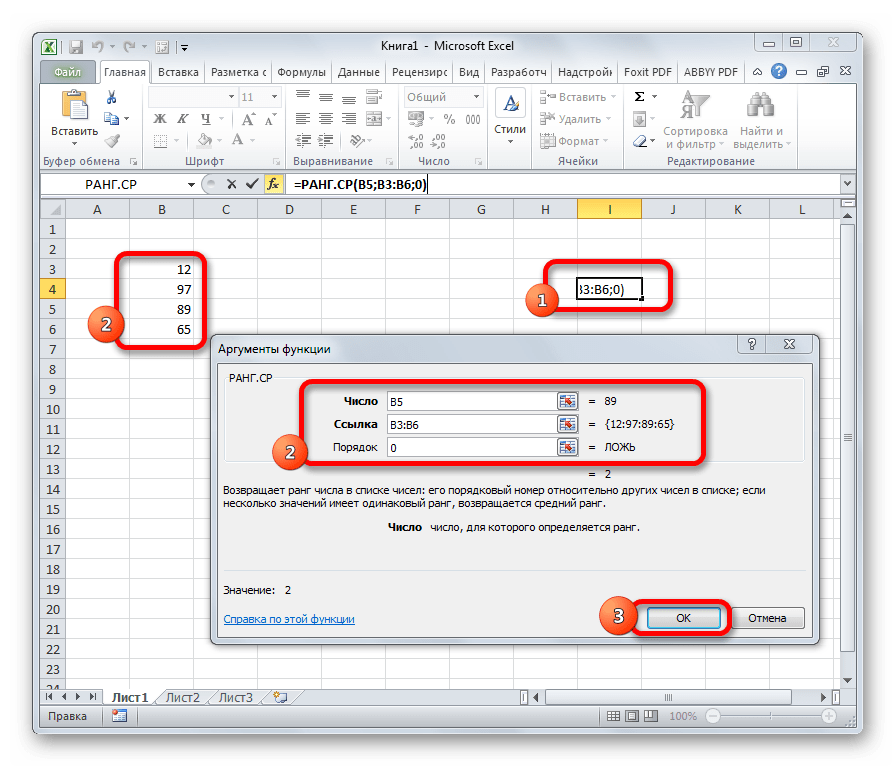
РАНГ.СР
Эта функция имеет действие, обратное предыдущим. В указанную ячейку она выдает порядковый номер конкретного числа в выборке по условию, которое указано в отдельном аргументе. Это может быть порядок по возрастанию или по убыванию. Последний установлен по умолчанию, если поле «Порядок» оставить пустым или поставить туда цифру 0. Синтаксис этого выражения выглядит следующим образом:
=РАНГ.СР(число;массив;порядок)
Выше были описаны только самые популярные и востребованные статистические функции в Экселе. На самом деле их в разы больше. Тем не менее, основной принцип действий у них похожий: обработка массива данных и возврат в указанную ячейку результата вычислительных действий.
Инфоурок
›
Другое
›Презентации›Статистический анализ данных в MS Excel
Скачать материал

Скачать материал




- Сейчас обучается 264 человека из 64 регионов




Описание презентации по отдельным слайдам:
-

1 слайд
Статистический анализ данных в MS Excel
1. Обзор и характеристика основных статистических функций, входящих в MS Excel.
2. Работа с пакетом анализа данных в MS Excel.
Литература:
1. Г.И. Просветов Анализ данных с помощью Excel. Задачи и решения. М: 2009
2. А.Ю. Козлов, В.С. Мхитарян, В.Ф. Шишов Статистический анализ данных в MS Excel М: 2012 -
2 слайд
Понятие анализа данных
Анализ данных – область математики и информатики, занимающая построением и исследованием наиболее общих математических методов и вычислительных алгоритмов извлечения знаний из экспериментальных данных.
Анализ данных – это процесс исследования, фильтрации, преобразования и моделирования данных с целью извлечения полезной информации и принятия решения. -
3 слайд
Статистические функции MS Excel
Все статистические функции, входящие в MS Excel можно разбить на восемь подразделов:
1.Предварительная обработка данных;
2.Определение характеристик положения;
3.Определение корреляции, ковариации;
4.Определение характеристик рассеивания
5.Интервальное оценивание (определение вероятности попадания дискретной случайной величины в интервал);
6.Определения параметров распределения непрерывной случайной величины;
7.Определение параметров распределения дискретной случайной величины;
8.Построение уравнения регрессии и прогнозирования. -
4 слайд
Предварительная обработка данных
Подсчет количества значений (СЧЕТ).
Определение экстремальных значений совокупности данных (МАКС, МИН)
Подсчет частот из массива данных, попадающих в заданные интервалы (ЧАСТОТА)
Оценка относительного положения точки (ПРОЦЕНТРАНГ)
Определение величины, соответствующей ее относительному положению (ПЕРСЕНТИЛЬ)
Определение числа перестановок (ПЕРЕСТ)
Определение ранга чисел в списке чисел (РАНГ) -
5 слайд
Предварительная обработка данных
Массив данных
СЧЕТ
МАКС
ЧАСТОТА
ПРОЦЕНТРАНГ
ПЕРСЕНТИЛЬ
РАНГ -
6 слайд
Определение характеристик положения
Определение среднего (СРЗНАЧ, СРГЕОМ)
Определение моды в интервале данных или массиве (МОДА)
Определение медианы (МЕДИАНА)
Определение квартилей (КВАРТИЛЬ) -
7 слайд
Определение характеристик положения
Массив данных
СРГЕОМ
СРЗНАЧ
МОДА
МЕДИАНА
КВАРТИЛЬ -
8 слайд
Определение характеристик рассеивания
Определение среднего линейного отклонения (СРОТКЛ)
Определение суммы квадратов отклонения (ДИСП)
Вычисление стандартного (среднего квадратического) отклонения (СТАНДОТКЛОН)
Определения асимметрии распределения (СКОС)
Определения эксцесса (ЭКСЦЕСС) -
9 слайд
Определение характеристик рассеивания
Массив данных
СРОТКЛ
КВАДРОТКЛ
ДИСП
СТАНДОТКЛОН
СКОС
ЭКСЦЕСС -
10 слайд
Зависимость случайных величин
Определение ковариации (КОВАР)
Определение коэффициента корреляции (КОРРЕЛ) -
11 слайд
Зависимость случайных величин
Массив данных
КОВАР
КОРРЕЛ -
12 слайд
Интервальное оценивание
Определение доверительного интервала для среднего (ДОВЕРИТ)
Определение вероятности попадания дискретной случайной величины в интервал (ВЕРОЯТНОСТЬ) -
13 слайд
Интервальное оценивание
Массив данных
ДОВЕРИТ
ВЕРОЯТНОСТЬ -
14 слайд
Определение параметров распределения непрерывных случайных величин
Определение значения функции распределения и функции плотности нормального распределения (НОРМРАСПР)
Определение аргумента по значению функции распределения (НОРМОБР)
Определение вероятности статистики z при проверке гипотизы о равенстве статистической оценки математического ожидания заданному значению (ZТЕСТ)
Определение значений функций распределения отличных от нормальных (ЛОГНОРМРАСП, СТЬЮДРАСП…)
Проверка гипотезы о равенстве дисперсий (ФТЕСТ) -
15 слайд
Определение параметров распределения непрерывных случайных величин
НОРМРАСП
НОРМОБР
Массив данных
ZТЕСТ
ФТЕСТ -
16 слайд
Построение уравнения регрессии и прогнозирование
Определение параметров линейной регрессии (ЛИНЕЙН)
Определение значений результативного признака по линейному уравнению регрессии (ТЕНДЕНЦИЯ)
Определение значения уравнения регрессии вида y=b0+b1x в заданной точке (ПРЕДСКАЗ) -
17 слайд
Построение уравнения регрессии и прогнозирование
ЛИНЕЙН
ТЕНДЕНЦИЯ
Массив данных
ПРЕДСКАЗ -
18 слайд
Работа с пакетом анализа данных в MS Excel.
-
19 слайд
Работа с пакетом анализа данных в MS Excel.
В пакет анализа данных входят следующие инструменты:
1.Генерация случайных чисел
2.Выборка
3.Гистограмма
4.Описательная статистика
5.Скользящее среднее
6.Экспоненциальное сглаживание
7.Ковариционный анализ
8.Корреляционный анализ
9.Двухвыборочный F-тест для дисперсий
10. Двухвыборочныйz-тест для средних
11.Парный двухвыборочный t-тест для средних
12. Двухвыборочный t-тест с одинаковыми дисперсиями
13. Двухвыборочный t-тест с разными дисперсиями
14. Дисперсионный анализ
15. Регрессия
16.Ранг и персентиль
17. Анализ Фурье -
20 слайд
Генерация случайных чисел
Окно инструмента Генерация случайных чисел содержит следующие основные параметры:
-Число переменных При помощи этого параметра можно получать многомерную выборку (количество столбцов)
-Число случайных чисел Определяется число точек данных (число реализаций), которое вы хотите генерировать для каждой переменной
-Случайное рассеивание Вводится произвольное значение, для которого необходимо генерировать случайные числа. Применяется для повторной генерации (повторное получение той же совокупности) -
21 слайд
Выборка
В пакете Анализ данных инструмент Выборка используется для создания выборки из генеральной совокупности, рассматривая входной диапазон как генеральную совокупность -
22 слайд
Гистограмма
Гистограмма применяется для графического изображения интервального вариационного ряда -
23 слайд
Описательная статистика
Описательная статистика использует совокупность методов, позволяющих делать научно обоснованные выводы о числовых параметрах распределения генеральной совокупности по случайной выборке из нее


.Определен...")

Опре...")



Определение коэфф...")













Найдите материал к любому уроку, указав свой предмет (категорию), класс, учебник и тему:
6 212 259 материалов в базе
- Выберите категорию:
- Выберите учебник и тему
- Выберите класс:
-
Тип материала:
-
Все материалы
-
Статьи
-
Научные работы
-
Видеоуроки
-
Презентации
-
Конспекты
-
Тесты
-
Рабочие программы
-
Другие методич. материалы
-
Найти материалы
Другие материалы
- 27.12.2020
- 4749
- 2
- 27.12.2020
- 4952
- 11
- 27.12.2020
- 5787
- 13
- 27.12.2020
- 5023
- 9
- 27.12.2020
- 4058
- 1
- 27.12.2020
- 3884
- 0
- 27.12.2020
- 3907
- 1
- 27.12.2020
- 3300
- 4
Вам будут интересны эти курсы:
-
Курс повышения квалификации «Основы туризма и гостеприимства»
-
Курс повышения квалификации «Организация научно-исследовательской работы студентов в соответствии с требованиями ФГОС»
-
Курс повышения квалификации «Формирование компетенций межкультурной коммуникации в условиях реализации ФГОС»
-
Курс повышения квалификации «Экономика предприятия: оценка эффективности деятельности»
-
Курс профессиональной переподготовки «Клиническая психология: теория и методика преподавания в образовательной организации»
-
Курс повышения квалификации «Введение в сетевые технологии»
-
Курс профессиональной переподготовки «Логистика: теория и методика преподавания в образовательной организации»
-
Курс повышения квалификации «Применение MS Word, Excel в финансовых расчетах»
-
Курс повышения квалификации «Основы менеджмента в туризме»
-
Курс повышения квалификации «Психодинамический подход в консультировании»
-
Курс профессиональной переподготовки «Корпоративная культура как фактор эффективности современной организации»
-
Курс профессиональной переподготовки «Деятельность по хранению музейных предметов и музейных коллекций в музеях всех видов»
-
Курс профессиональной переподготовки «Организация системы менеджмента транспортных услуг в туризме»
-
Курс профессиональной переподготовки «Техническая диагностика и контроль технического состояния автотранспортных средств»
-
Настоящий материал опубликован пользователем Гущина Мадина Ивановна. Инфоурок является
информационным посредником и предоставляет пользователям возможность размещать на сайте
методические материалы. Всю ответственность за опубликованные материалы, содержащиеся в них
сведения, а также за соблюдение авторских прав несут пользователи, загрузившие материал на сайтЕсли Вы считаете, что материал нарушает авторские права либо по каким-то другим причинам должен быть удален с
сайта, Вы можете оставить жалобу на материал.Удалить материал
-

- На сайте: 2 года и 3 месяца
- Подписчики: 0
- Всего просмотров: 47180
-
Всего материалов:
217
To begin with, statistical function in Excel let’s first understand what is statistics and why we need it? So, statistics is a branch of sciences that can give a property to a sample. It deals with collecting, organizing, analyzing, and presenting the data. One of the great mathematicians Karl Pearson, also the father of modern statistics quoted that, “statistics is the grammar of science”.
We used statistics in every industry, including business, marketing, governance, engineering, health, etc. So in short statistics a quantitative tool to understand the world in a better way. For example, the government studies the demography of his/her country before making any policy and the demography can only study with the help of statistics. We can take another example for making a movie or any campaign it is very important to understand your audience and there too we used statistics as our tool.
Ways to approach statistical function in Excel:
In Excel, we have a range of statical functions, we can perform basic mead, median mode to more complex statistical distribution, and probability test. In order to understand statistical Functions we will divide them into two sets:
- Basic statistical Function
- Intermediate Statistical Function.
Statistical Function in Excel
Excel is the best tool to apply statistical functions. As discussed above we first discuss the basic statistical function, and then we will study intermediate statistical function. Throughout the article, we will take data and by using it we will understand the statistical function.
So, let’s take random data of a book store that sells textbooks for classes 11th and 12th.
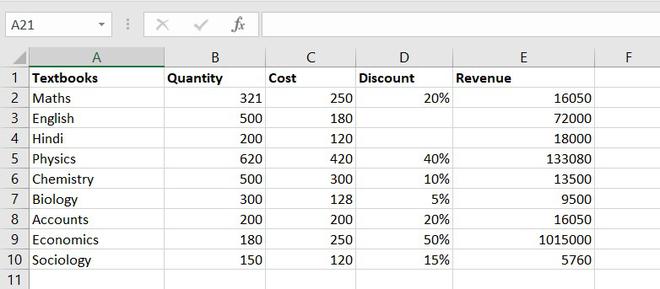
Example of statistical function.
Basic statistical Function
These are some most common and useful functions. These include the COUNT function, COUNTA function, COUNTBLANK function, COUNTIFS function. Let’s discuss one by one:
1. COUNT function
The COUNT function is used to count the number of cells containing a number. Always remember one thing that it will only count the number.
Formula for COUNT function = COUNT(value1, [value2], …)
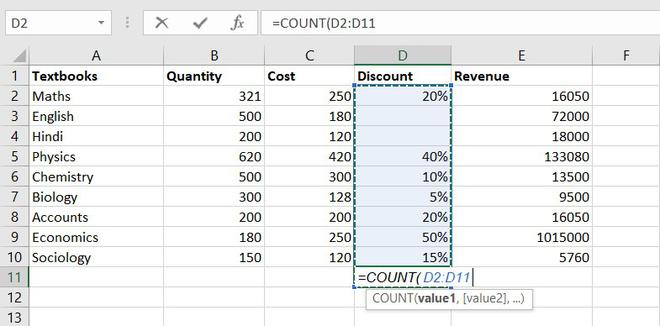
Example of statistical function.
Thus, there are 7 textbooks that have a discount out of 9 books.
2. COUNTA function
This function will count everything, it will count the number of the cell containing any kind of information, including numbers, error values, empty text.
Formula for COUNTA function = COUNTA(value1, [value2], …)
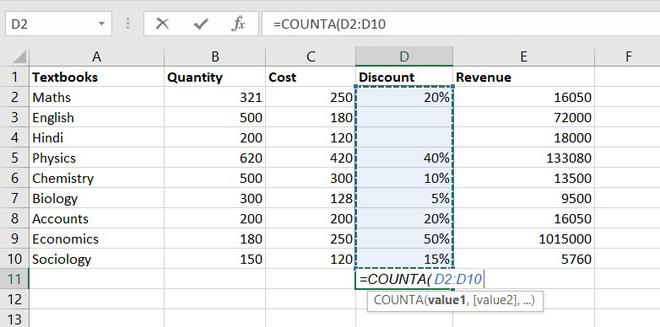
Example of statistical function.
So, there are a total of 9 subjects that being sold in the store
3. COUNTBLANK function
COUNTBLANK function, as the term, suggest it will only count blank or empty cells.
Formula for COUNTBlANK function = COUNTBLANK(range)
![]()
Example of statistical function.
There are 2 subjects that don’t have any discount.
4. COUNTIFS function
COUNTIFS function is the most used function in Excel. The function will work on one or more than one condition in a given range and counts the cell that meets the condition.
Formula for COUNTIFS function = COUNTIFS (range1, criteria1, [range2], [criteria2], ...)
Intermediate Statistical Function
Let’s discuss some intermediate statistical functions in Excel. These functions used more often by the analyst. It includes functions like AVERAGE function, MEDIAN function, MODE function, STANDARD DEVIATION function, VARIANCE function, QUARTILES function, CORRELATION function.
1. AVERAGE value1, [value2], …)
The AVERAGE function is one of the most used intermediate functions. The function will return the arithmetic mean or an average of the cell in a given range.
Formula for AVERAGE function = AVERAGE(number1, [number2], …)
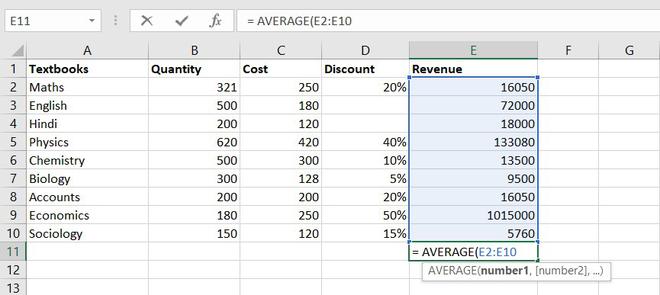
Example of statistical function.
So the average total revenue is Rs.144326.6667
2. AVERAGEIF function
The function will return the arithmetic mean or an average of the cell in a given range that meets the given criteria.
Formula for AVERAGEIF function = AVERAGEIF(range, criteria, [average_range])
3. MEDIAN function
The MEDIAN function will return the central value of the data. Its syntax is similar to the AVERAGE function.
Formula for MEDIAN function = MEDIAN(number1, [number2], …)
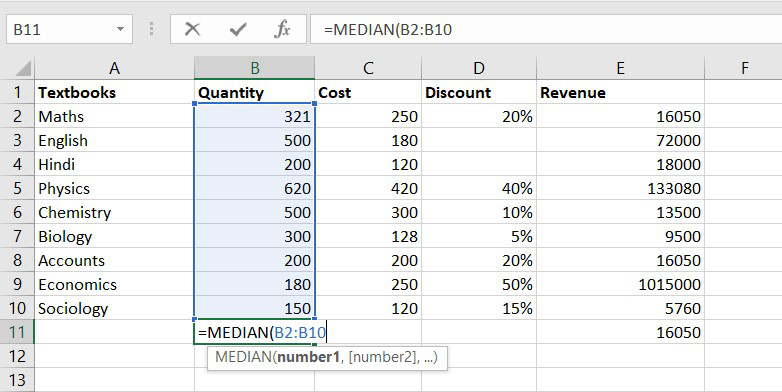
Example of statistical function.
Thus, the median quantity sold is 300.
4. MODE function
The MODE function will return the most frequent value of the cell in a given range.
Formula for MODE function = MODE.SNGL(number1,[number2],…)
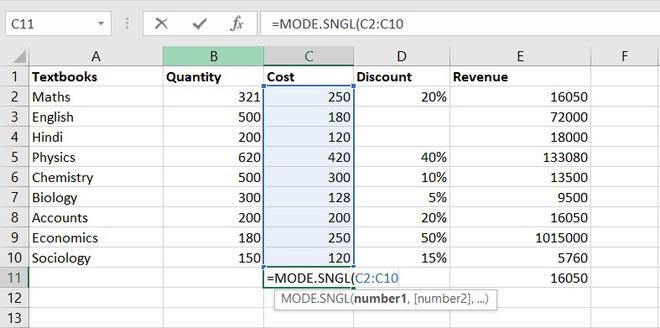
Example of statistical function.
Thus, the most frequent or repetitive cost is Rs. 250.
5. STANDARD DEVIATION
This function helps us to determine how much observed value deviated or varied from the average. This function is one of the useful functions in Excel.
Formula for STANDARD DEVIATION function = STDEV.P(number1,[number2],…)
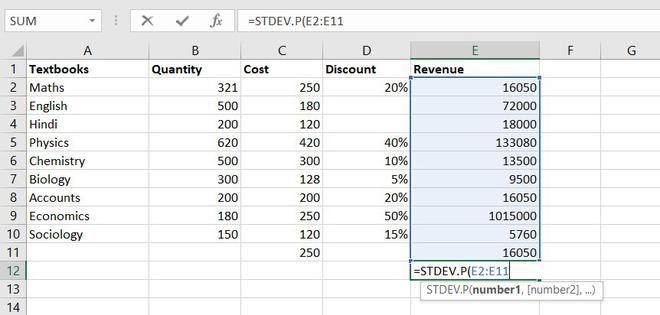
Example of statistical function.
Thus, Standard Deviation of total revenue =296917.8172
6. VARIANCE function
To understand the VARIANCE function, we first need to know what is variance? Basically, Variance will determine the degree of variation in your data set. The more data is spread it means the more is variance.
Formula for VARIANCE function = VAR(number1, [number2], …)
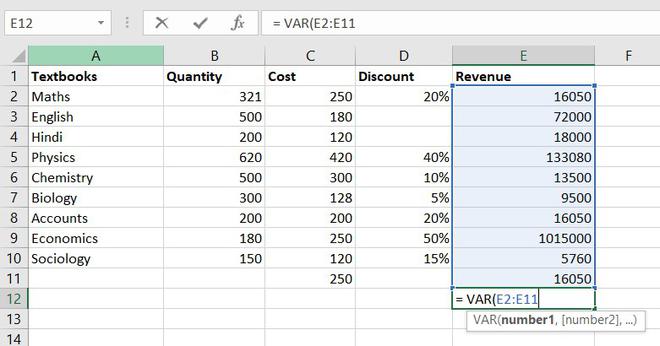
Example of statistical function.
So, the variance of Revenue= 97955766832
7. QUARTILES function
Quartile divides the data into 4 parts just like the median which divides the data into two equal parts. So, the Excel QUARTILES function returns the quartiles of the dataset. It can return the minimum value, first quartile, second quartile, third quartile, and max value. Let’s see the syntax :
Formula for QUARTILES function = QUARTILE (array, quart)
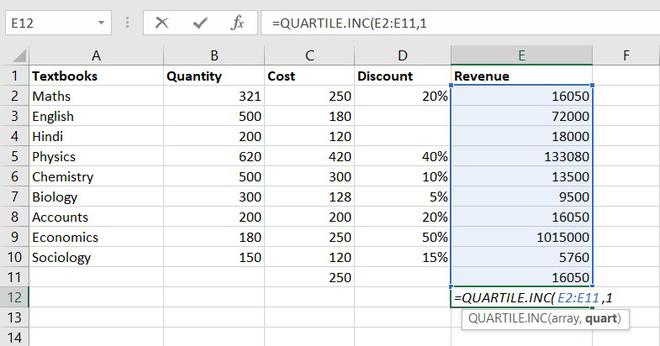
Example of statistical function.
So, the first quartile = 14137.5
8. CORRELATION function
CORRELATION function, help to find the relationship between the two variables, this function mostly used by the analyst to study the data. The range of the CORRELATION coefficient lies between -1 to +1.
Formula for CORRELATION function = CORREL(array1, array2)
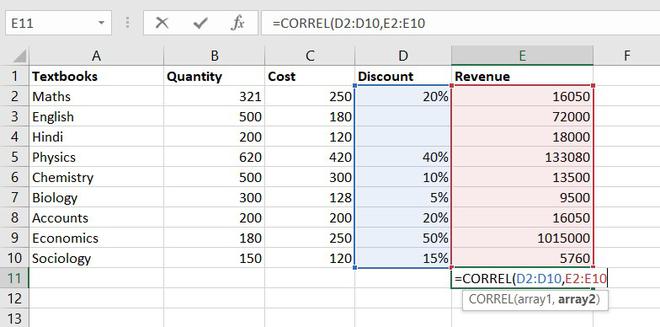
Example of statistical function.
So, the correlation coefficient between discount and revenue of store = 0.802428894. Since it is a positive number, thus we can conclude discount is positively related to revenue.
9. MAX function
The MAX function will return the largest numeric value within a given set of data or an array.
Formula for MAX function = MAX (number1, [number2], ...)
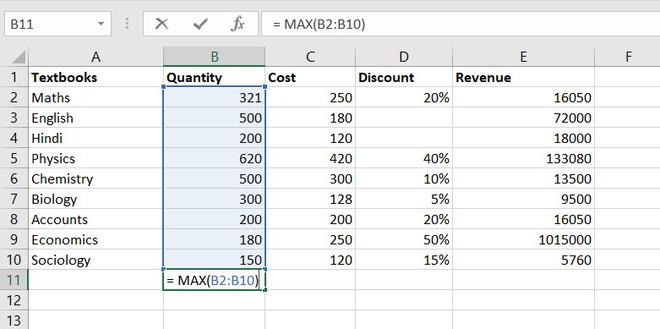
The maximum quantity of textbooks is Physics,620 in numbers.
10. MIN function
The MIN function will return the smallest numeric value within a given set of data or an array.
Formula for MIN function = MIN (number1, [number2], ...)
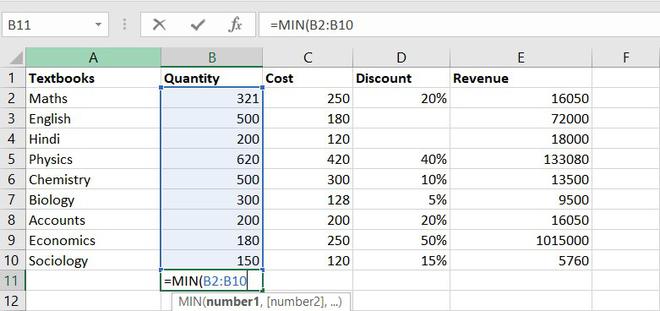
The minimum number of the book available in the store =150(Sociology)
11. LARGE function
The LARGE function is similar to the MAX function but the only difference is it returns the nth largest value within a given set of data or an array.
Formula for LARGE function = LARGE (array, k)
Let’s find the most expensive textbook using a large function, where k = 1
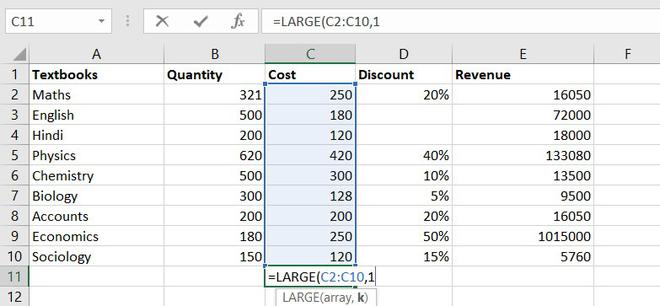
Example of statistical function.
The most expensive textbook is Rs. 420.
12. SMALL function
The SMALL function is similar to the MIN function, but the only difference is it return nth smallest value within a given set of data or an array.
Formula for SMALL function = SMALL (array, k)
Similarly, using the SMALL function we can find the second least expensive book.
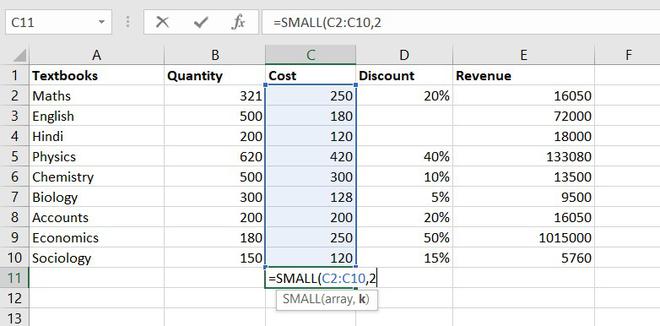
Example of statistical function.
Thus, Rs. 120 is the least cost price.
Conclusion
So these are some statistical functions of Excel. We have learned some of the most simple functions like COUNT functions to complex ones like the CORRELATION function. So far we learn, we understand how much these functions are useful for analyzing any data. You can explore more functions and learn more things of your own.
Рассмотрим инструмент Описательная статистика, входящий в надстройку Пакет Анализа. Рассчитаем показатели выборки: среднее, медиана, мода, дисперсия, стандартное отклонение и др.
Задача
описательной статистики
(descriptive statistics) заключается в том, чтобы с использованием математических инструментов свести сотни значений
выборки
к нескольким итоговым показателям, которые дают представление о
выборке
.В качестве таких статистических показателей используются:
среднее
,
медиана
,
мода
,
дисперсия, стандартное отклонение
и др.
Опишем набор числовых данных с помощью определенных показателей. Для чего нужны эти показатели? Эти показатели позволят сделать определенные
статистические выводы о распределении
, из которого была взята
выборка
. Например, если у нас есть
выборка
значений толщины трубы, которая изготавливается на определенном оборудовании, то на основании анализа этой
выборки
мы сможем сделать, с некой определенной вероятностью, заключение о состоянии процесса изготовления.
Содержание статьи:
- Надстройка Пакет анализа;
-
Среднее выборки
;
-
Медиана выборки
;
-
Мода выборки
;
-
Мода и среднее значение
;
-
Дисперсия выборки
;
-
Стандартное отклонение выборки
;
-
Стандартная ошибка
;
-
Ассиметричность
;
-
Эксцесс выборки
;
-
Уровень надежности
.
Надстройка Пакет анализа
Для вычисления статистических показателей одномерных
выборок
, используем
надстройку Пакет анализа
. Затем, все показатели рассчитанные надстройкой, вычислим с помощью встроенных функций MS EXCEL.
СОВЕТ
: Подробнее о других инструментах надстройки
Пакет анализа
и ее подключении – читайте в статье
Надстройка Пакет анализа MS EXCEL
.
Выборку
разместим на
листе
Пример
в файле примера
в диапазоне
А6:А55
(50 значений).
Примечание
: Для удобства написания формул для диапазона
А6:А55
создан
Именованный диапазон
Выборка.
В диалоговом окне
Анализ данных
выберите инструмент
Описательная статистика
.

После нажатия кнопки
ОК
будет выведено другое диалоговое окно,
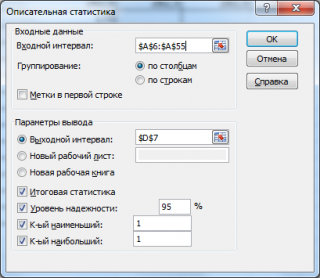
в котором нужно указать:
входной интервал
(Input Range) – это диапазон ячеек, в котором содержится массив данных. Если в указанный диапазон входит текстовый заголовок набора данных, то нужно поставить галочку в поле
Метки в первой строке (
Labels
in
first
row
).
В этом случае заголовок будет выведен в
Выходном интервале.
Пустые ячейки будут проигнорированы, поэтому нулевые значения необходимо обязательно указывать в ячейках, а не оставлять их пустыми;
выходной интервал
(Output Range). Здесь укажите адрес верхней левой ячейки диапазона, в который будут выведены статистические показатели;
Итоговая статистика (
Summary
Statistics
)
. Поставьте галочку напротив этого поля – будут выведены основные показатели выборки:
среднее, медиана, мода, стандартное отклонение
и др.;-
Также можно поставить галочки напротив полей
Уровень надежности (
Confidence
Level
for
Mean
)
,
К-й наименьший
(Kth Largest) и
К-й наибольший
(Kth Smallest).
В результате будут выведены следующие статистические показатели:
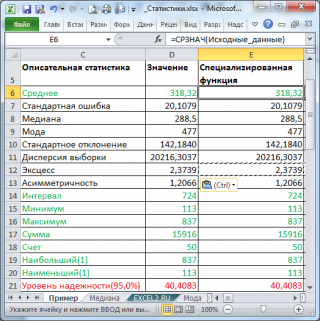
Все показатели выведены в виде значений, а не формул. Если массив данных изменился, то необходимо перезапустить расчет.
Если во
входном интервале
указать ссылку на несколько столбцов данных, то будет рассчитано соответствующее количество наборов показателей. Такой подход позволяет сравнить несколько наборов данных. При сравнении нескольких наборов данных используйте заголовки (включите их во
Входной интервал
и установите галочку в поле
Метки в первой строке
). Если наборы данных разной длины, то это не проблема — пустые ячейки будут проигнорированы.
Зеленым цветом на картинке выше и в
файле примера
выделены показатели, которые не требуют особого пояснения. Для большинства из них имеется специализированная функция:
Интервал
(Range) — разница между максимальным и минимальным значениями;
Минимум
(Minimum) – минимальное значение в диапазоне ячеек, указанном во
Входном интервале
(см.статью про функцию
МИН()
);
Максимум
(Maximum)– максимальное значение (см.статью про функцию
МАКС()
);
Сумма
(Sum) – сумма всех значений (см.статью про функцию
СУММ()
);
Счет
(Count) – количество значений во
Входном интервале
(пустые ячейки игнорируются, см.статью про функцию
СЧЁТ()
);
Наибольший
(Kth Largest) – выводится К-й наибольший. Например, 1-й наибольший – это максимальное значение (см.статью про функцию
НАИБОЛЬШИЙ()
);
Наименьший
(Kth Smallest) – выводится К-й наименьший. Например, 1-й наименьший – это минимальное значение (см.статью про функцию
НАИМЕНЬШИЙ()
).
Ниже даны подробные описания остальных показателей.
Среднее выборки
Среднее
(mean, average) или
выборочное среднее
или
среднее выборки
(sample average) представляет собой
арифметическое среднее
всех значений массива. В MS EXCEL для вычисления среднего выборки используется функция
СРЗНАЧ()
.
Выборочное среднее
является «хорошей» (несмещенной и эффективной) оценкой
математического ожидания
случайной величины (подробнее см. статью
Среднее и Математическое ожидание в MS EXCEL
).
Медиана выборки
Медиана
(Median) – это число, которое является серединой множества чисел (в данном случае выборки): половина чисел множества больше, чем
медиана
, а половина чисел меньше, чем
медиана
. Для определения
медианы
необходимо сначала
отсортировать множество чисел
. Например,
медианой
для чисел 2, 3, 3,
4
, 5, 7, 10 будет 4.
Если множество содержит четное количество чисел, то вычисляется
среднее
для двух чисел, находящихся в середине множества. Например,
медианой
для чисел 2, 3,
3
,
5
, 7, 10 будет 4, т.к. (3+5)/2.
Если имеется длинный хвост распределения, то
Медиана
лучше, чем
среднее значение
, отражает «типичное» или «центральное» значение. Например, рассмотрим несправедливое распределение зарплат в компании, в которой руководство получает существенно больше, чем основная масса сотрудников.
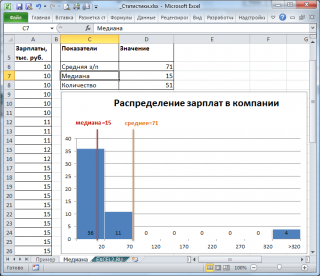
Очевидно, что средняя зарплата (71 тыс. руб.) не отражает тот факт, что 86% сотрудников получает не более 30 тыс. руб. (т.е. 86% сотрудников получает зарплату в более, чем в 2 раза меньше средней!). В то же время медиана (15 тыс. руб.) показывает, что
как минимум
у 50% сотрудников зарплата меньше или равна 15 тыс. руб.
Для определения
медианы
в MS EXCEL существует одноименная функция
МЕДИАНА()
, английский вариант — MEDIAN().
Медиану
также можно вычислить с помощью формул
=КВАРТИЛЬ.ВКЛ(Выборка;2) =ПРОЦЕНТИЛЬ.ВКЛ(Выборка;0,5).
Подробнее о
медиане
см. специальную статью
Медиана в MS EXCEL
.
СОВЕТ
: Подробнее про
квартили
см. статью, про
перцентили (процентили)
см. статью.
Мода выборки
Мода
(Mode) – это наиболее часто встречающееся (повторяющееся) значение в
выборке
. Например, в массиве (1; 1;
2
;
2
;
2
; 3; 4; 5) число 2 встречается чаще всего – 3 раза. Значит, число 2 – это
мода
. Для вычисления
моды
используется функция
МОДА()
, английский вариант MODE().
Примечание
: Если в массиве нет повторяющихся значений, то функция вернет значение ошибки #Н/Д. Это свойство использовано в статье
Есть ли повторы в списке?
Начиная с
MS EXCEL 2010
вместо функции
МОДА()
рекомендуется использовать функцию
МОДА.ОДН()
, которая является ее полным аналогом. Кроме того, в MS EXCEL 2010 появилась новая функция
МОДА.НСК()
, которая возвращает несколько наиболее часто повторяющихся значений (если количество их повторов совпадает). НСК – это сокращение от слова НеСКолько.
Например, в массиве (1; 1;
2
;
2
;
2
; 3;
4
;
4
;
4
; 5) числа 2 и 4 встречаются наиболее часто – по 3 раза. Значит, оба числа являются
модами
. Функции
МОДА.ОДН()
и
МОДА()
вернут значение 2, т.к. 2 встречается первым, среди наиболее повторяющихся значений (см.
файл примера
, лист
Мода
).
Чтобы исправить эту несправедливость и была введена функция
МОДА.НСК()
, которая выводит все
моды
. Для этого ее нужно ввести как
формулу массива
.
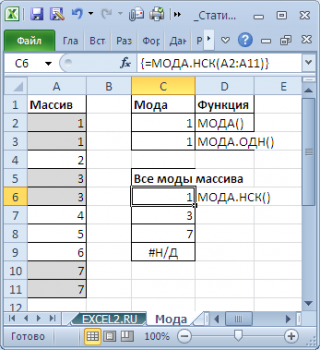
Как видно из картинки выше, функция
МОДА.НСК()
вернула все три
моды
из массива чисел в диапазоне
A2:A11
: 1; 3 и 7. Для этого, выделите диапазон
C6:C9
, в
Строку формул
введите формулу
=МОДА.НСК(A2:A11)
и нажмите
CTRL+SHIFT+ENTER
. Диапазон
C
6:
C
9
охватывает 4 ячейки, т.е. количество выделяемых ячеек должно быть больше или равно количеству
мод
. Если ячеек больше чем м
о
д, то избыточные ячейки будут заполнены значениями ошибки #Н/Д. Если
мода
только одна, то все выделенные ячейки будут заполнены значением этой
моды
.
Теперь вспомним, что мы определили
моду
для выборки, т.е. для конечного множества значений, взятых из
генеральной совокупности
. Для
непрерывных случайных величин
вполне может оказаться, что выборка состоит из массива на подобие этого (0,935; 1,211; 2,430; 3,668; 3,874; …), в котором может не оказаться повторов и функция
МОДА()
вернет ошибку.
Даже в нашем массиве с
модой
, которая была определена с помощью
надстройки Пакет анализа
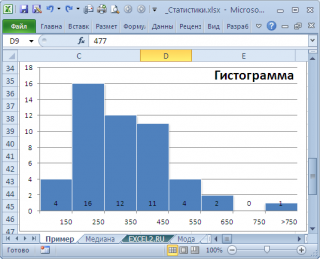
, творится, что-то не то. Действительно,
модой
нашего массива значений является число 477, т.к. оно встречается 2 раза, остальные значения не повторяются. Но, если мы посмотрим на
гистограмму распределения
, построенную для нашего массива, то увидим, что 477 не принадлежит интервалу наиболее часто встречающихся значений (от 150 до 250).
Проблема в том, что мы определили
моду
как наиболее часто встречающееся значение, а не как наиболее вероятное. Поэтому,
моду
в учебниках статистики часто определяют не для выборки (массива), а для функции распределения. Например, для
логнормального распределения
мода
(наиболее вероятное значение непрерывной случайной величины х), вычисляется как
exp
(
m
—
s
2
)
, где m и s параметры этого распределения.
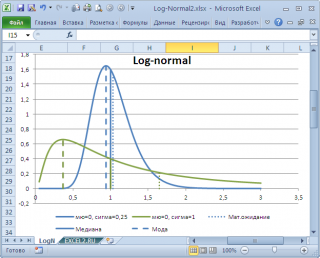
Понятно, что для нашего массива число 477, хотя и является наиболее часто повторяющимся значением, но все же является плохой оценкой для
моды
распределения, из которого взята
выборка
(наиболее вероятного значения или для которого плотность вероятности распределения максимальна).
Для того, чтобы получить оценку
моды
распределения, из
генеральной совокупности
которого взята
выборка
, можно, например, построить
гистограмму
. Оценкой для
моды
может служить интервал наиболее часто встречающихся значений (самого высокого столбца). Как было сказано выше, в нашем случае это интервал от 150 до 250.
Вывод
: Значение
моды
для
выборки
, рассчитанное с помощью функции
МОДА()
, может ввести в заблуждение, особенно для небольших выборок. Эта функция эффективна, когда случайная величина может принимать лишь несколько дискретных значений, а размер
выборки
существенно превышает количество этих значений.
Например, в рассмотренном примере о распределении заработных плат (см. раздел статьи выше, о Медиане),
модой
является число 15 (17 значений из 51, т.е. 33%). В этом случае функция
МОДА()
дает хорошую оценку «наиболее вероятного» значения зарплаты.
Примечание
: Строго говоря, в примере с зарплатой мы имеем дело скорее с
генеральной совокупностью
, чем с
выборкой
. Т.к. других зарплат в компании просто нет.
О вычислении
моды
для распределения
непрерывной случайной величины
читайте статью
Мода в MS EXCEL
.
Мода и среднее значение
Не смотря на то, что
мода
– это наиболее вероятное значение случайной величины (вероятность выбрать это значение из
Генеральной совокупности
максимальна), не следует ожидать, что
среднее значение
обязательно будет близко к
моде
.
Примечание
:
Мода
и
среднее
симметричных распределений совпадает (имеется ввиду симметричность
плотности распределения
).
Представим, что мы бросаем некий «неправильный» кубик, у которого на гранях имеются значения (1; 2; 3; 4; 6; 6), т.е. значения 5 нет, а есть вторая 6.
Модой
является 6, а среднее значение – 3,6666.
Другой пример. Для
Логнормального распределения
LnN(0;1)
мода
равна =EXP(m-s2)= EXP(0-1*1)=0,368, а
среднее значение
1,649.
Дисперсия выборки
Дисперсия выборки
или
выборочная дисперсия (
sample
variance
) характеризует разброс значений в массиве, отклонение от
среднего
.
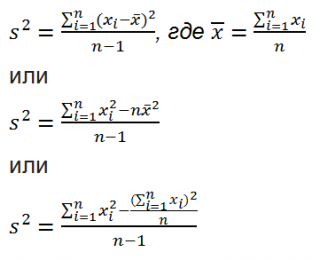
Из формулы №1 видно, что
дисперсия выборки
это сумма квадратов отклонений каждого значения в массиве
от среднего
, деленная на размер выборки минус 1.
В MS EXCEL 2007 и более ранних версиях для вычисления
дисперсии выборки
используется функция
ДИСП()
. С версии MS EXCEL 2010 рекомендуется использовать ее аналог — функцию
ДИСП.В()
.
Дисперсию
можно также вычислить непосредственно по нижеуказанным формулам (см.
файл примера
):
=КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1) =(СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/ (СЧЁТ(Выборка)-1)
– обычная формула
=СУММ((Выборка -СРЗНАЧ(Выборка))^2)/ (СЧЁТ(Выборка)-1)
–
формула массива
Дисперсия выборки
равна 0, только в том случае, если все значения равны между собой и, соответственно, равны
среднему значению
.
Чем больше величина
дисперсии
, тем больше разброс значений в массиве относительно
среднего
.
Размерность
дисперсии
соответствует квадрату единицы измерения исходных значений. Например, если значения в выборке представляют собой измерения веса детали (в кг), то размерность
дисперсии
будет кг
2
. Это бывает сложно интерпретировать, поэтому для характеристики разброса значений чаще используют величину равную квадратному корню из
дисперсии – стандартное отклонение
.
Подробнее о
дисперсии
см. статью
Дисперсия и стандартное отклонение в MS EXCEL
.
Стандартное отклонение выборки
Стандартное отклонение выборки
(Standard Deviation), как и
дисперсия
, — это мера того, насколько широко разбросаны значения в выборке
относительно их среднего
.
По определению,
стандартное отклонение
равно квадратному корню из
дисперсии
:
![]()
Стандартное отклонение
не учитывает величину значений в
выборке
, а только степень рассеивания значений вокруг их
среднего
. Чтобы проиллюстрировать это приведем пример.
Вычислим стандартное отклонение для 2-х
выборок
: (1; 5; 9) и (1001; 1005; 1009). В обоих случаях, s=4. Очевидно, что отношение величины стандартного отклонения к значениям массива у
выборок
существенно отличается.
В MS EXCEL 2007 и более ранних версиях для вычисления
Стандартного отклонения выборки
используется функция
СТАНДОТКЛОН()
. С версии MS EXCEL 2010 рекомендуется использовать ее аналог
СТАНДОТКЛОН.В()
.
Стандартное отклонение
можно также вычислить непосредственно по нижеуказанным формулам (см.
файл примера
):
=КОРЕНЬ(КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1)) =КОРЕНЬ((СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/(СЧЁТ(Выборка)-1))
Подробнее о
стандартном отклонении
см. статью
Дисперсия и стандартное отклонение в MS EXCEL
.
Стандартная ошибка
В
Пакете анализа
под термином
стандартная ошибка
имеется ввиду
Стандартная ошибка среднего
(Standard Error of the Mean, SEM).
Стандартная ошибка среднего
— это оценка
стандартного отклонения
распределения
выборочного среднего
.
Примечание
: Чтобы разобраться с понятием
Стандартная ошибка среднего
необходимо прочитать о
выборочном распределении
(см. статью
Статистики, их выборочные распределения и точечные оценки параметров распределений в MS EXCEL
) и статью про
Центральную предельную теорему
.
Стандартное отклонение распределения выборочного среднего
вычисляется по формуле σ/√n, где n — объём
выборки, σ — стандартное отклонение исходного
распределения, из которого взята
выборка
. Т.к. обычно
стандартное отклонение
исходного распределения неизвестно, то в расчетах вместо
σ
используют ее оценку
s
—
стандартное отклонение выборки
. А соответствующая величина s/√n имеет специальное название —
Стандартная ошибка среднего.
Именно эта величина вычисляется в
Пакете анализа.
В MS EXCEL
стандартную ошибку среднего
можно также вычислить по формуле
=СТАНДОТКЛОН.В(Выборка)/ КОРЕНЬ(СЧЁТ(Выборка))
Асимметричность
Асимметричность
или
коэффициент асимметрии
(skewness) характеризует степень несимметричности распределения (
плотности распределения
) относительно его
среднего
.
Положительное значение
коэффициента асимметрии
указывает, что размер правого «хвоста» распределения больше, чем левого (относительно среднего). Отрицательная асимметрия, наоборот, указывает на то, что левый хвост распределения больше правого.
Коэффициент асимметрии
идеально симметричного распределения или выборки равно 0.

Примечание
:
Асимметрия выборки
может отличаться расчетного значения асимметрии теоретического распределения. Например,
Нормальное распределение
является симметричным распределением (
плотность его распределения
симметрична относительно
среднего
) и, поэтому имеет асимметрию равную 0. Понятно, что при этом значения в
выборке
из соответствующей
генеральной совокупности
не обязательно должны располагаться совершенно симметрично относительно
среднего
. Поэтому,
асимметрия выборки
, являющейся оценкой
асимметрии распределения
, может отличаться от 0.
Функция
СКОС()
, английский вариант SKEW(), возвращает коэффициент
асимметрии выборки
, являющейся оценкой
асимметрии
соответствующего распределения, и определяется следующим образом:
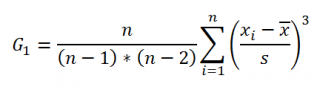
где n – размер
выборки
, s –
стандартное отклонение выборки
.
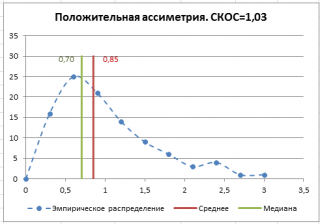
В
файле примера на листе СКОС
приведен расчет коэффициента
асимметрии
на примере случайной выборки из
распределения Вейбулла
, которое имеет значительную положительную
асимметрию
при параметрах распределения W(1,5; 1).
Эксцесс выборки
Эксцесс
показывает относительный вес «хвостов» распределения относительно его центральной части.
Для того чтобы определить, что относится к хвостам распределения, а что к его центральной части, можно использовать границы μ +/-
σ
.
Примечание
: Не смотря на старания профессиональных статистиков, в литературе еще попадается определение
Эксцесса
как меры «остроконечности» (peakedness) или сглаженности распределения. Но, на самом деле, значение
Эксцесса
ничего не говорит о форме пика распределения.
Согласно определения,
Эксцесс
равен четвертому
стандартизированному моменту:
![]()
Для
нормального распределения
четвертый момент равен 3*σ
4
, следовательно,
Эксцесс
равен 3. Многие компьютерные программы используют для расчетов не сам
Эксцесс
, а так называемый Kurtosis excess, который меньше на 3. Т.е. для
нормального распределения
Kurtosis excess равен 0. Необходимо быть внимательным, т.к. часто не очевидно, какая формула лежит в основе расчетов.
Примечание
: Еще большую путаницу вносит перевод этих терминов на русский язык. Термин Kurtosis происходит от греческого слова «изогнутый», «имеющий арку». Так сложилось, что на русский язык оба термина Kurtosis и Kurtosis excess переводятся как
Эксцесс
(от англ. excess — «излишек»). Например, функция MS EXCEL
ЭКСЦЕСС()
на самом деле вычисляет Kurtosis excess.
Функция
ЭКСЦЕСС()
, английский вариант KURT(), вычисляет на основе значений выборки несмещенную оценку
эксцесса распределения
случайной величины и определяется следующим образом:
![]()
Как видно из формулы MS EXCEL использует именно Kurtosis excess, т.е. для выборки из
нормального распределения
формула вернет близкое к 0 значение.
Если задано менее четырех точек данных, то функция
ЭКСЦЕСС()
возвращает значение ошибки #ДЕЛ/0!
Вернемся к
распределениям случайной величины
.
Эксцесс
(Kurtosis excess) для
нормального распределения
всегда равен 0, т.е. не зависит от параметров распределения μ и σ. Для большинства других распределений
Эксцесс
зависит от параметров распределения: см., например,
распределение Вейбулла
или
распределение Пуассона
, для котрого
Эксцесс
= 1/λ.
Уровень надежности
Уровень
надежности
— означает вероятность того, что
доверительный интервал
содержит истинное значение оцениваемого параметра распределения.
Вместо термина
Уровень
надежности
часто используется термин
Уровень доверия
. Про
Уровень надежности
(Confidence Level for Mean) читайте статью
Уровень значимости и уровень надежности в MS EXCEL
.
Задав значение
Уровня
надежности
в окне
надстройки Пакет анализа
, MS EXCEL вычислит половину ширины
доверительного интервала для оценки среднего (дисперсия неизвестна)
.
Тот же результат можно получить по формуле (см.
файл примера
):
=ДОВЕРИТ.СТЬЮДЕНТ(1-0,95;s;n)
s —
стандартное отклонение выборки
, n – объем
выборки
.
Подробнее см. статью про
построение доверительного интервала для оценки среднего (дисперсия неизвестна)
.
5
Лекция 2
Цель
1. Систематизировать знания о статистических
функциях в Excel, получить
представление о способах обработки
статистические данных в табличном
процессоре.
2. Ознакомиться с возможностями Пакета
анализа в Excel.
3. Привести примеры работы со списками
в Excel.
Статистические функции в ms Excel
Пусть представлены следующие статистические
данные (см. таб. 1), по которым надо
вычислить:
-
количество опрошенных;
-
количество опрошенных женщин;
-
процент женщин среди опрошенных;
-
процент мужчин среди опрошенных;
-
средний возраст опрошенных
(среднеарифметическое); -
средний возраст (медиана);
-
минимальный и максимальный
возраст опрошенных; -
количество женщин с высшим
образованием; -
средний возраст женщин с высшим
образованием;
Таблица 1
|
Данные социологического опроса |
||
|
пол |
возраст |
образование |
|
м |
41 |
высшее |
|
ж |
53 |
среднее |
|
ж |
48 |
незаконченное высшее |
|
м |
47 |
среднее специальное |
|
ж |
22 |
среднее |
|
м |
32 |
высшее |
|
ж |
39 |
среднее специальное |
|
м |
49 |
незаконченное высшее |
|
м |
52 |
незаконченное высшее |
|
м |
28 |
высшее |
|
м |
55 |
среднее |
|
ж |
41 |
среднее специальное |
|
м |
32 |
высшее |
|
м |
40 |
среднее |
|
м |
41 |
среднее |
|
ж |
32 |
высшее |
|
м |
41 |
высшее |
|
м |
20 |
высшее |
|
ж |
48 |
высшее |
|
м |
61 |
высшее |
|
нет ответа |
32 |
среднее специальное |
|
ж |
19 |
среднее специальное |
|
ж |
49 |
среднее специальное |
|
м |
22 |
среднее |
|
м |
40 |
среднее |
|
м |
60 |
высшее |
Для такого рода вычислений будем
пользоваться встроенными функциями.
Рассмотрим некоторые из них.
1) СЧЕТ(значение1; значение2;…), которая
подсчитывает количество чисел в списке
аргументов. Функция СЧЁТ используется
для получения количества числовых ячеек
в интервалах или массивах ячеек.
Аргументы: значение1; значение2; …— это
от 1 до 30 аргументов, которые могут
содержать или ссылаться на данные
различных типов, но в подсчете участвуют
только числа.
2) СЧЕТЕСЛИ(диапазон;критерий), где
диапазон – диапазон, в котором нужно
подсчитать ячейки. Критерий – критерий
в форме числа, выражения или текста,
который определяет, какие ячейки надо
подсчитывать.
3) СРЗНАЧ, которая возвращает среднее
(арифметическое) своих аргументов.
СРЗНАЧ(число1; число2; …)
Число1, число2, …– это от 1 до 30 аргументов,
для которых вычисляется среднее.
4) МЕДИАНА(число1;число2;…). Число1,
число2,…– от 1 до 30 чисел, для которых
определяется медиана. Медиана – это
число, которое является серединой
множества чисел, то есть половина чисел
имеют значения большие, чем медиана, а
половина чисел имеют значения меньшие,
чем медиана.
5) МОДА(число1;число2;…). Число1,
число2,…– от 1 до 30 чисел, для которых
определяется мода. МОДА определяет
значение, которое чаще других встречается
во множестве чисел.
6) МАКС(число1;число2; …). Число1,
число2,…– от 1 до 30 чисел, среди которых
требуется найти наибольшее.
7) МИН(число1;число2; …). Число1,
число2,…– от 1 до 30 чисел, среди которых
требуется найти наименьшее.
 если числовые значения образуют
если числовые значения образуют
полную генеральную совокупность, то
для вычисления дисперсии и стандартного
отклонения (среднего квадратического
отклонения) используются функции ДИСПР
и СТАНДОТКЛОНП.
9) функции ДИСП и СТАНДОТКЛОН
используются, если необходимо
произвести вычисления дисперсии и
стандартного отклонения по выборке.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #