
Excel открывает большие возможности в обработке массива цифр и строк. Сегодня мы разберем, как в excel обработать большой объем данных. В этой части мы не будем разбирать макросы. Цель этой статьи — научиться работать с самыми доступными и простыми формулами excel, которые помогут выполнить нашу работу в большинстве случаев.
Статья будет разделена на 2 части. Содержание первой части, представлена ниже. Начнем без теории. Вряд ли она вам интересна.
Содержание:
- Как в excel найти повторяющееся значение
- Как в excel быстро удалить дублирующиеся строки
- Работа со сводной таблицей в excel
- Как в excel «подтянуть» данные из другого листа или файла
- Что такое функции правсимв и левсимв и как их применять
Как в excel найти повторяющееся значение
В своде данных мы можем столкнуться с проблемой, когда нам нужно из большого количества строк быстро найти повторяющиеся строки. Ведь в одной строке может быть одно значение, а во второй, по такому же наименованию товара, дубль или другое значение.
Возьмем таблицу. В столбец Е ставим равно и затем, в поиске «Другие функции» ищем нужную нам формулу (см. рис 1)
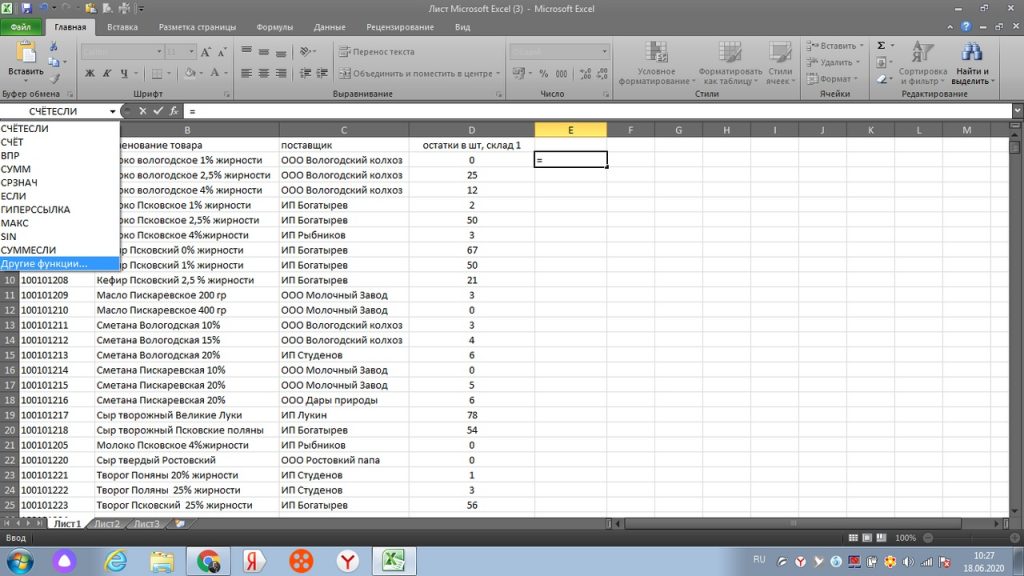
Для поиска повторяющегося значения, в данном случае, в коде товара по столбцу А, мы будем пользоваться простой формулой = СЧЕТЕСЛИ
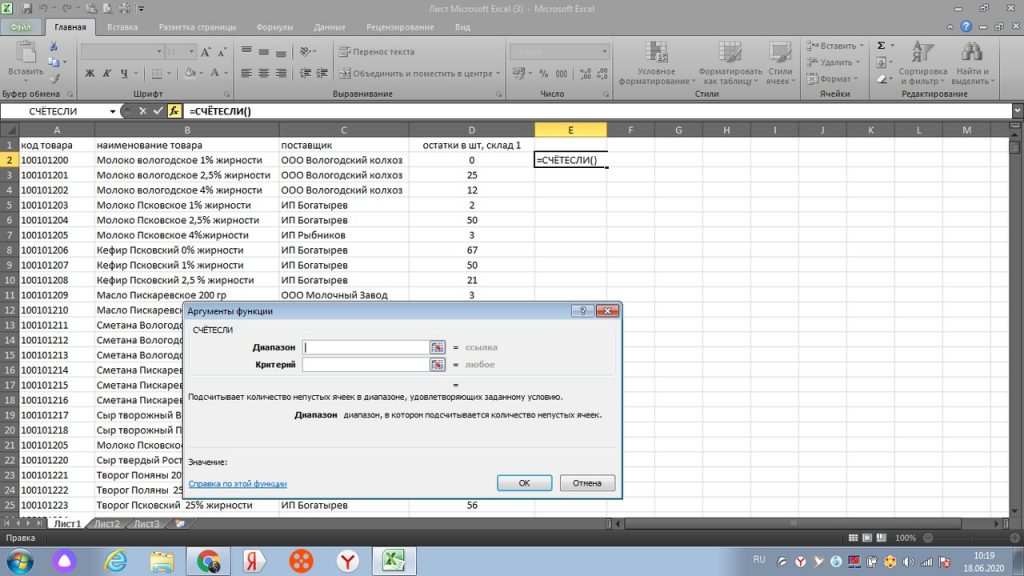
Выделяем весь столбец «А», и в диапазоне аргументов функций ( маленькое голубое окошко посреди экрана), у нас появляется А:А, то есть весь выделенный диапазон по этому столбцу. см. рис 3.
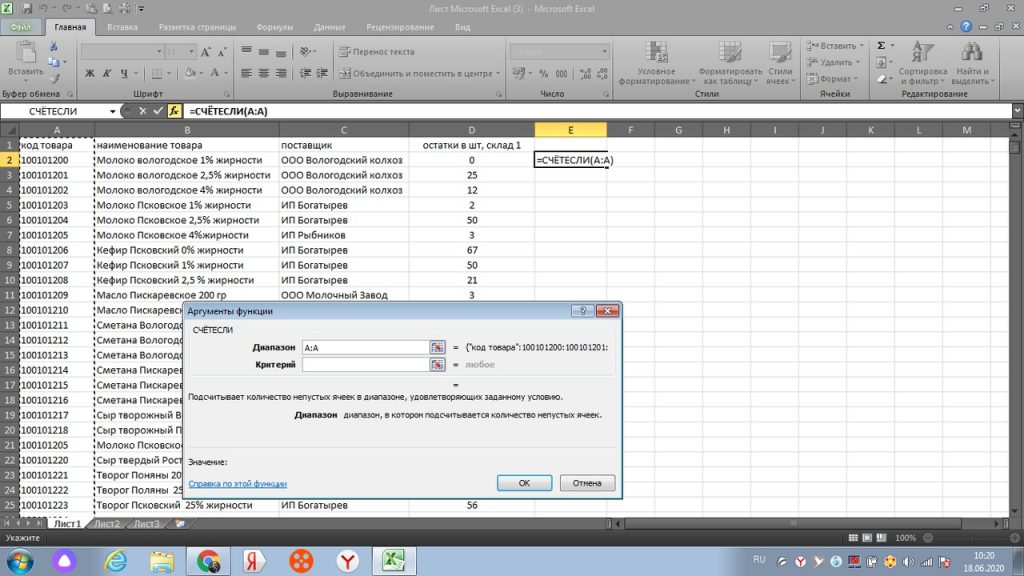
Переходим в окно «критерий», и выделяем только первую строку по коду товара. У нас она отразится, как А2. см. рис. 3.
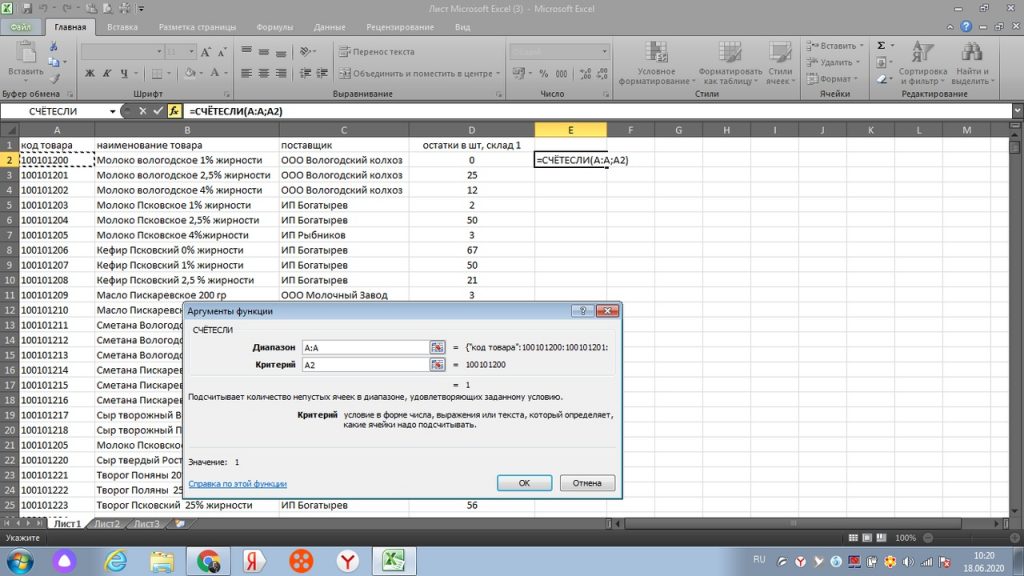
Далее, нажимаем «ок», и в столбце «Е» появляется цифра 1. Это значит, что по товару 100101200 Молоко Вологодское 1% жирности, только один такой товар, нет дублей. См. рис 5.
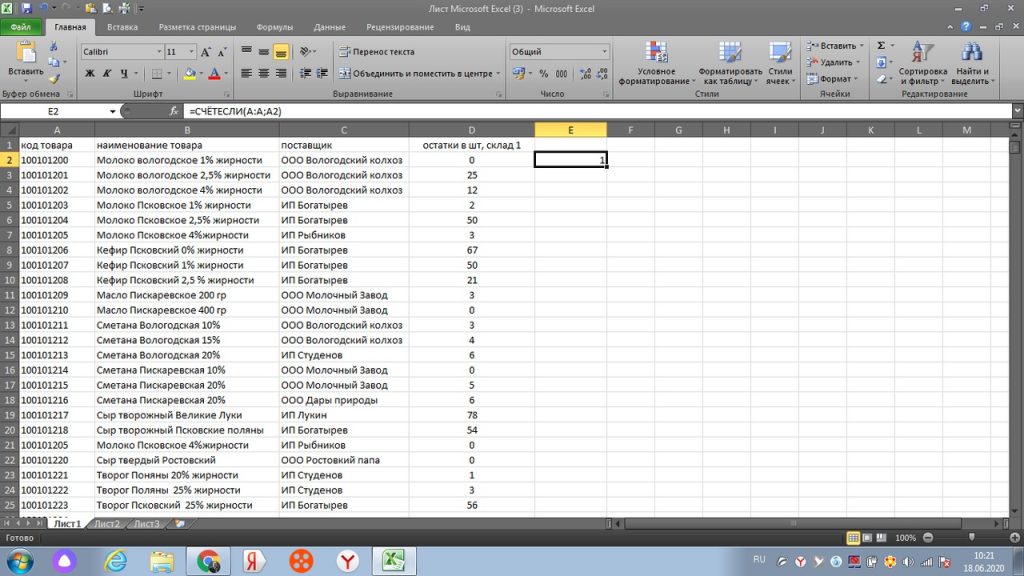
«Протягиваем» значения по столбцу «Е» вниз, и мы получаем результат, а именно, какие товары у нас имеют дубль в нашем списке, см рис 6. У нас проявилось 2 одинаковых товара, (их excel обозначил цифрой 2), которые, для наглядности вручную выделил желтым.
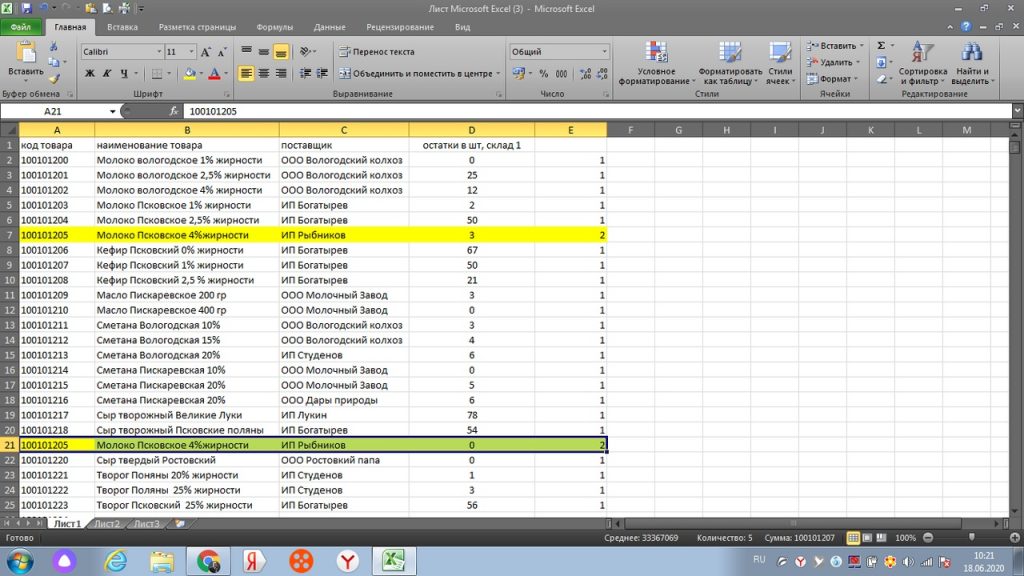
Если бы у нас было три одинаковых товара в списке, то excel, соответственно, проставил цифру 3. И так далее. Уже через простой фильтр, можно выделить, все, что больше 1 и увидеть полную картину.
Как в excel удалить дублирующиеся строки
По сути, метод, указанный выше, уже выполняет наш запрос. Однако, если Вам не нужны данные с повторяющихся строк, а требуется просто их удалить, тогда есть наиболее простой способ быстрого удаления дублей.
Мы воспользуемся функцией, которая уже встроена в панель excel. См. на панели закладку » ДАННЫЕ». Наша функция так и называется «Удалить дубликаты».
Мы выделяем область поиска, у нас это вновь столбец А. См рис 7.
(В более поздней версии excel, можно все находить через поисковое окно.)
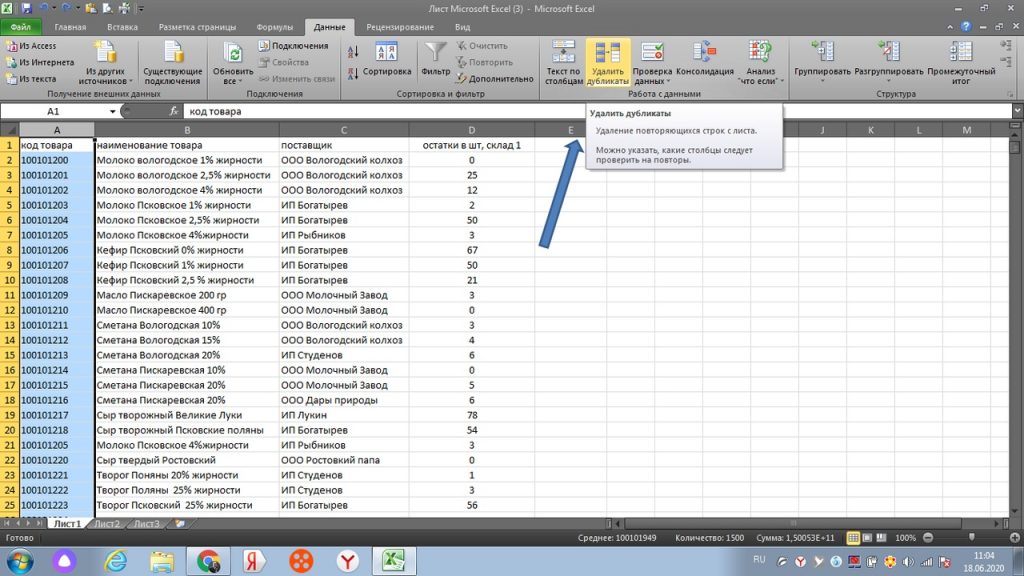
Далее нам просто нужно подтвердить удаление. Однако, для наглядности, выделил зеленым те задвоенные строки, которые у нас есть. Это строка 7 и 21. См рис 8.
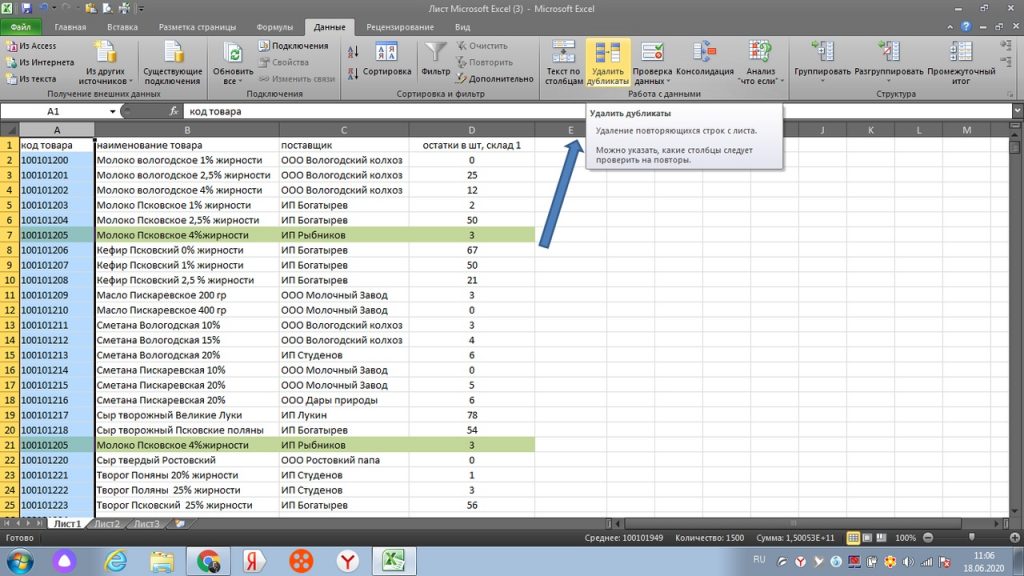
Теперь на панели жмем кнопку «удалить дубликаты». У нас появляется окошко. Здесь нам автоматически предлагает удалить всю горизонтальную строку, то есть «автоматически расширить выделенный диапазон». Жмем на кнопку «удалить дубликаты». См рис 9
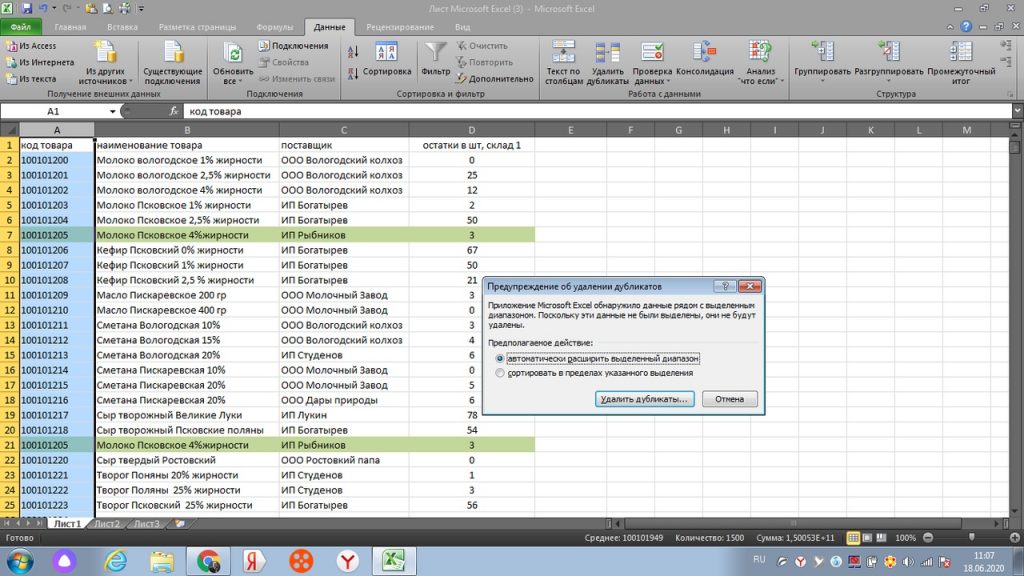
После этого мы видим, что указаны столбцы отмеченные галочками, которые будут удалены по дублирующейся горизонтальной строке. См. рис 10. Мы жмем «ок».
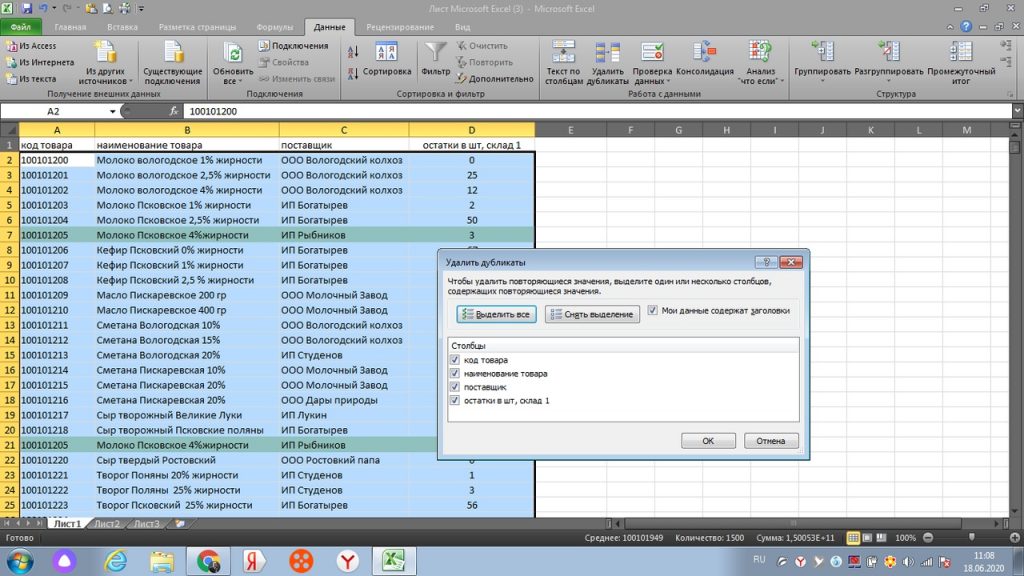
Все. Теперь мы видим окно с оповещением, что дубль в количестве 1 строки был удален. Теперь, на месте 21-ой строки по товару-дублю, появился следующий товар из нижнего списка. См. рис 11.
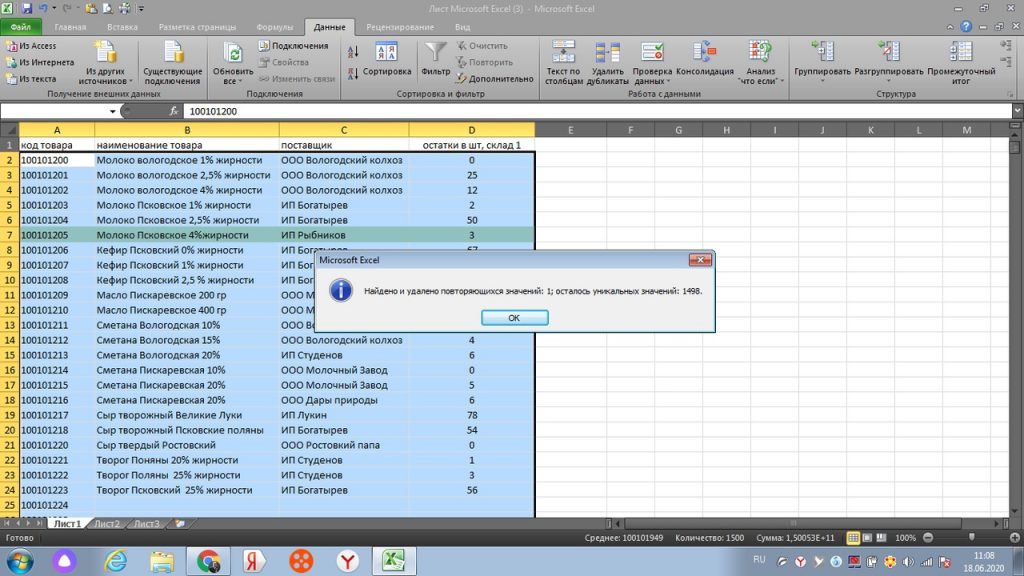
Исходя из описания, может показаться, что по времени занимает не меньше, чем в первом варианте, но на самом деле это не так. Я просто эту функцию расписал очень подробно.
Как в excel обработать большой объем данных, сводная таблица
Сводная таблица служит для объединения разрозненной информации воедино. Сегодня мы также научимся это делать. Здесь нет ничего сложного. К примеру нам требуется, сколько же у нас есть одного и того же товара, не по брендам, а по виду товара.
Смотрим нашу таблицу. В панели инструментов ищем закладку «ВСТАВКА». Под панелью инструментов, в верхнем левом углу, появляется иконка, которая так и называется «Сводная таблица». см. рис 12. (Или ищем ее в поиске новой версии excel)
Мы выделяем все столбцы или столбцы интересующих нас значений.
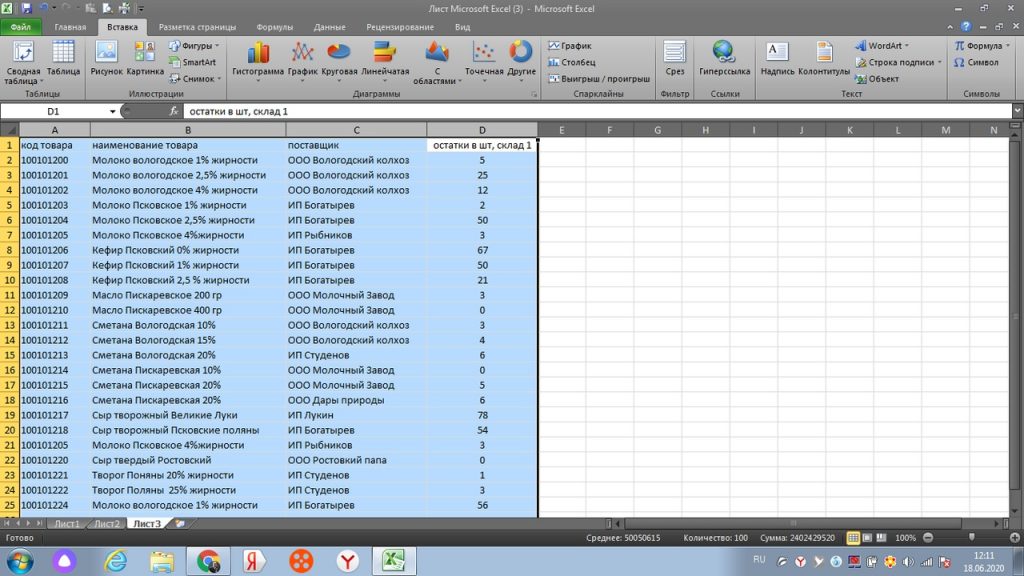
Затем нажимаем на иконку «сводная таблица». У нас выходит окошко, в котором выделен диапазон столбцов. По умолчанию, excel предлагает сводную таблицу вынести на новый лист. см. рис 13. Мы так и делаем.
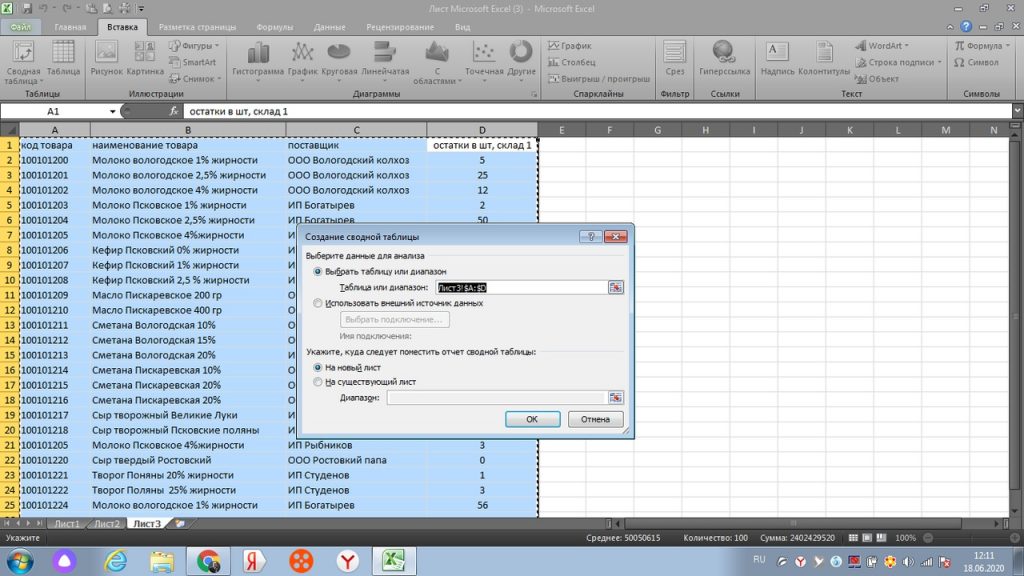
Подтверждаем команду нажав кнопку «ок». Получаем на новом листе нашей страницы excel возможность построения сводной таблицы, см рис 14.
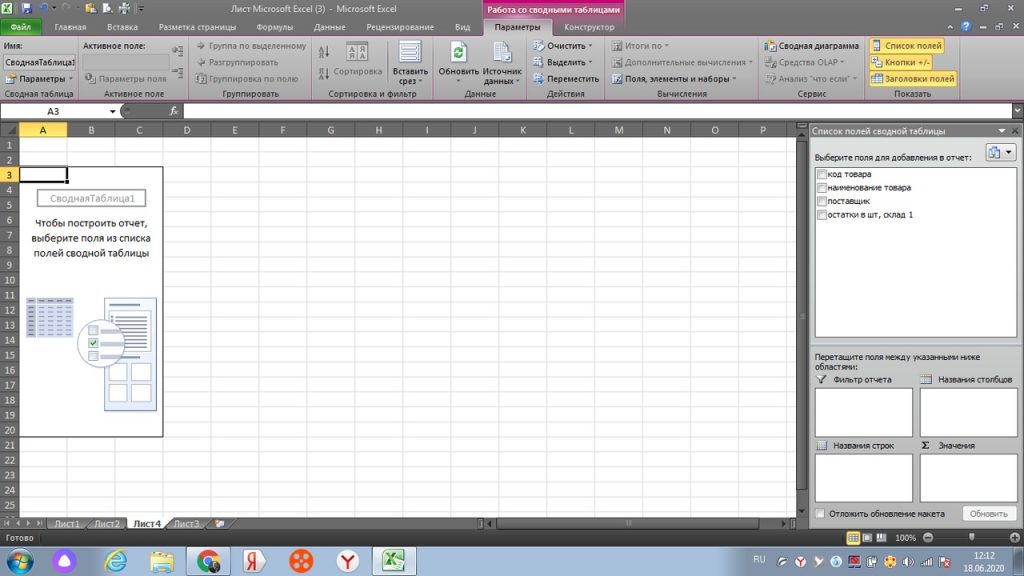
Теперь мы выбираем нужные нам значения из правого верхнего участка. Раз мы договорились, что нам нужно знать сколько у нас товара по одному наименованию, то выбираем галкой наименование товара. См. рис 15.
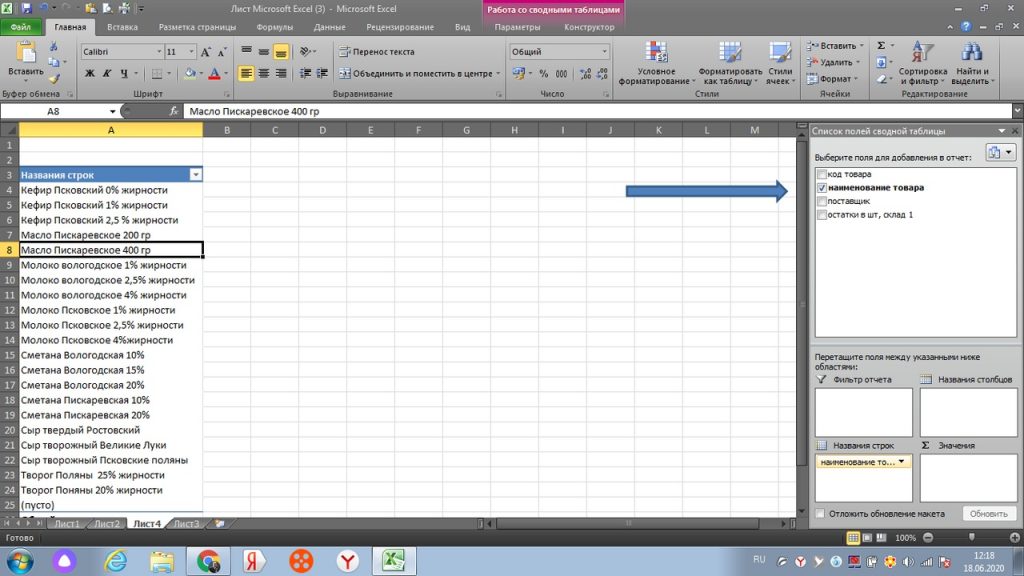
По аналогии, мы ставим галку напротив количества (остатки в шт, склад 1).
При этом, перемещаем данные с количеством не в окно «название строк», а в окно «Значения». см. рис 16
Здесь мы видим, что у нас появился дополнительный столбец, но пока не по количеству штук каждого товара, а по количеству строк. Далее мы делаем следующую операцию.
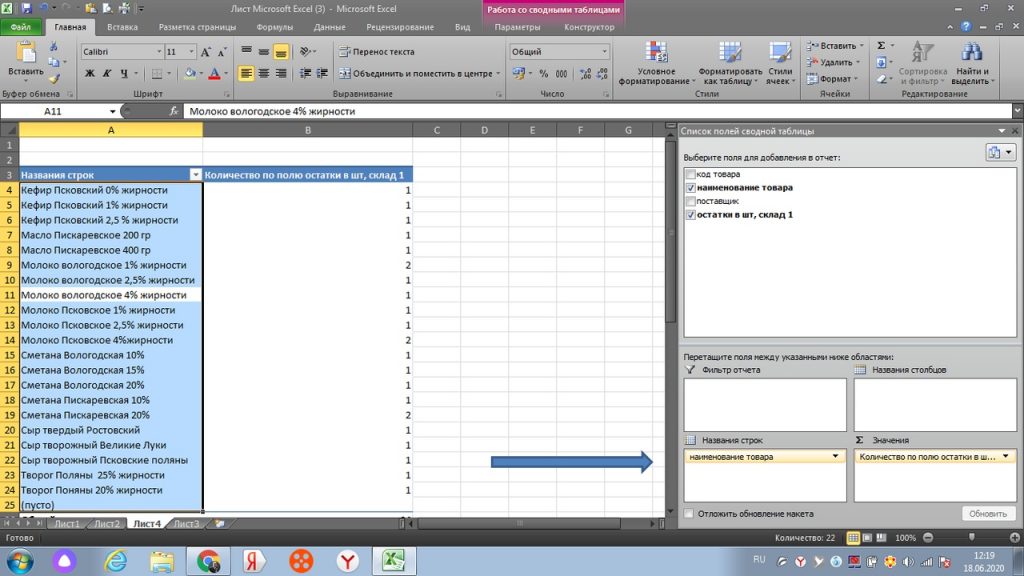
Правой клавишей мыши нажимаем на столбец с количеством. См. рис 17. У нас открывается окно, где в строке ИТОГИ ПО, мы ставим галку не по количеству (строк), как на картинке, а по сумме.
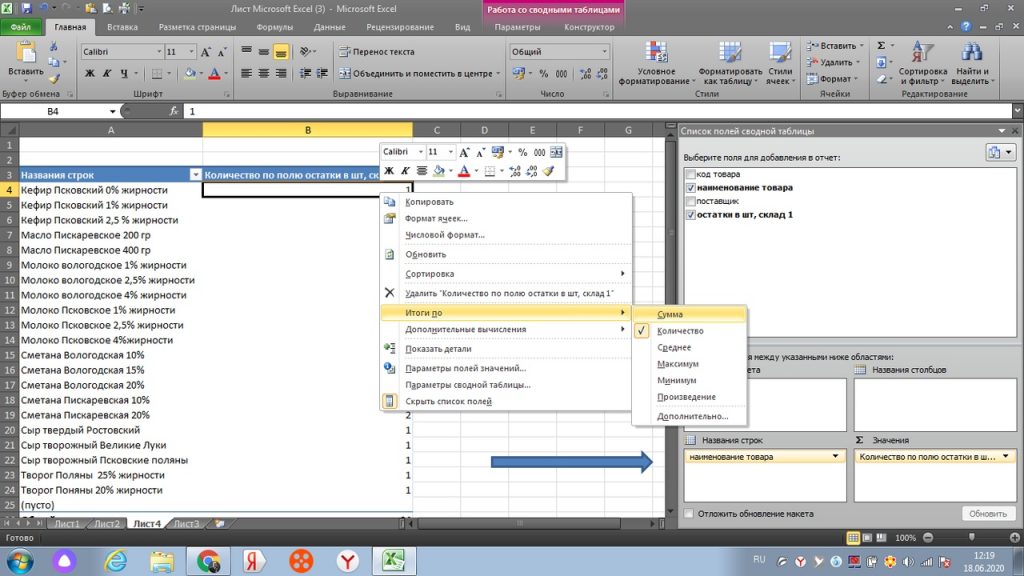
Теперь мы получаем именно сведенное количество по каждому товару. См рис 18.
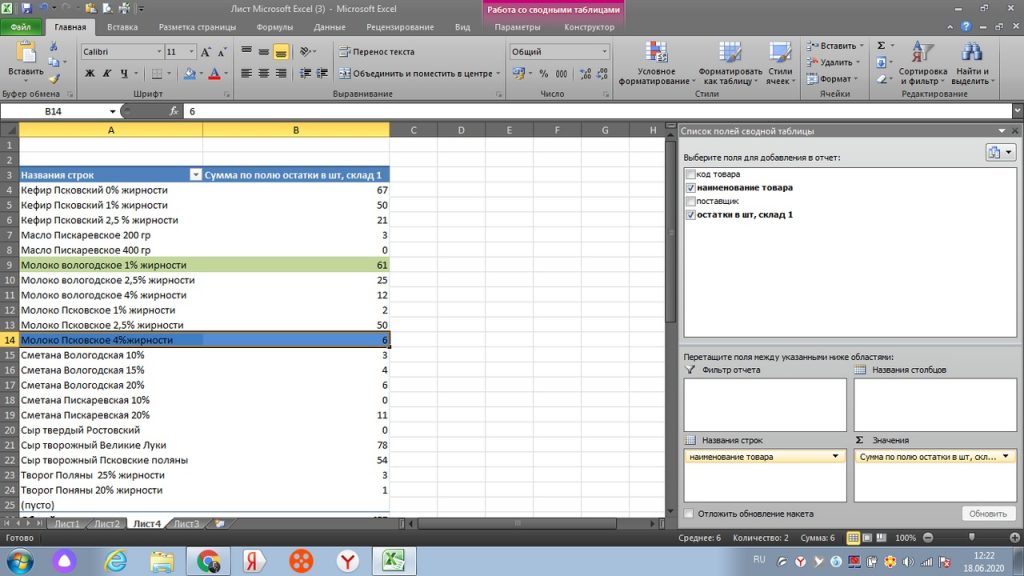
Для сравнения и наглядности, возвращаемся в исходный лист, (см. рис 19) и мы видим:
одинаковые товары по наименованию, помеченные синим цветом 3+3 = 6 штук.
одинаковые товары, помеченные зеленым 5+56 = 61 штука.
Тоже самое у нас в сводной таблице ( рис 18), 6 и 61 штука.
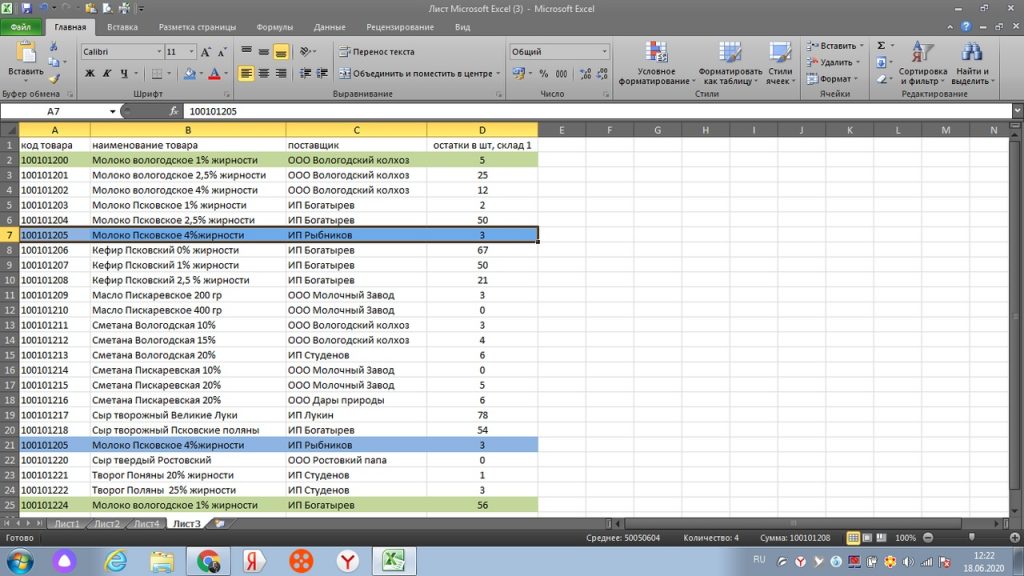
В сводную таблицу можно добавить поставщика и так далее. Можно ее сделать более сложной в плане количества учитываемый столбцов. Это уже дело необходимости и практики. Один-два раза сделаете, поймете суть. Потом, навык, как в excel обработать большой объем данных на уровне сводной таблицы, уже никогда не забудете.
Как в excel подтянуть данные из одного диапазона в другой, с помощью функции ВПР
Будет логичным, если сразу же покажу, как в excel «подтянуть» данные из другого листа или файла, в другой. Для этого есть замечательная функция ВПР. Мы разберем, как пользоваться этим на уже знакомых нам данных.
К примеру, Вам нужно свести цифры воедино с другого магазина, склада заявки на один лист Excel. Это делается по ключевому значению, которое должно быть во всех источниках данных. Это может быть уникальный код товара или его наименование.
Сразу оговорюсь по наименованию или текстовому значению, функция ВПР бескомпромиссна.
Если в наименовании товара есть пробел или точка, (любое отклонение) то для нее это будет уже другое значение.
Также необходимо, что бы все источники были в одном формате. Если мы говорим о числах, то в числовом формате.
Итак, у нас есть исходный файл, на листе 1, (см. рис 20)
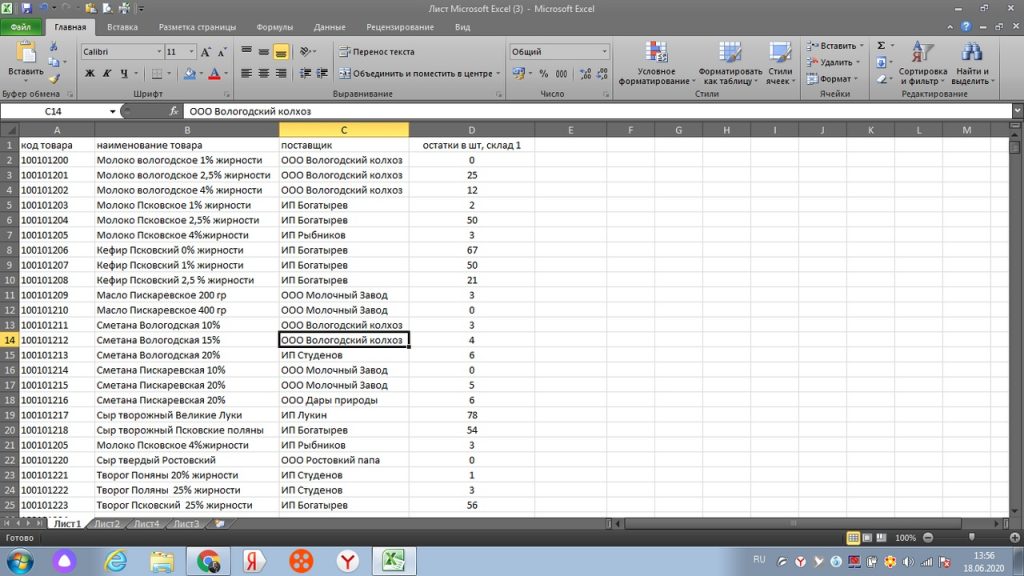
Из листа 2, (рис 21) мы будем подтягивать цифры в лист 1. Обратите внимание, что количества на листах разное. Строки также могут быть смещены в списке или перемешаны, поэтому, простым сложением одной цифры с другой нам не обойтись.
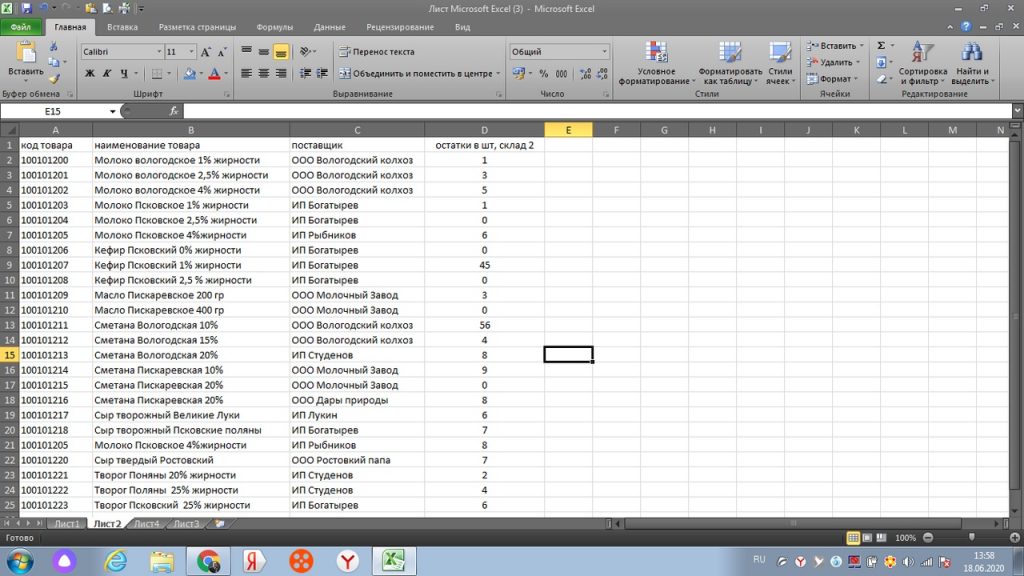
Для нас данные на листе 1 те, к которым нужно подтянуть другие значения. Также действуем через знак равно «=». В левом верхнем углу, через поиск других функций, находим ВПР, см рис 22.
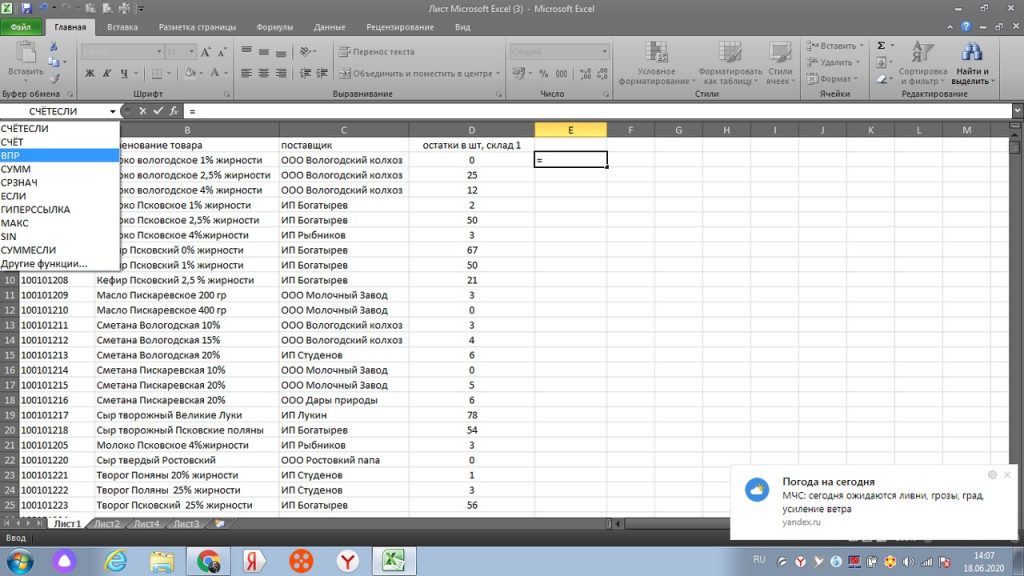
Затем, у нас открывается окно и мы выделяем весь столбец А, то есть искомое значение. Оно в новом окне выделяется, как А:А, см рис 23.
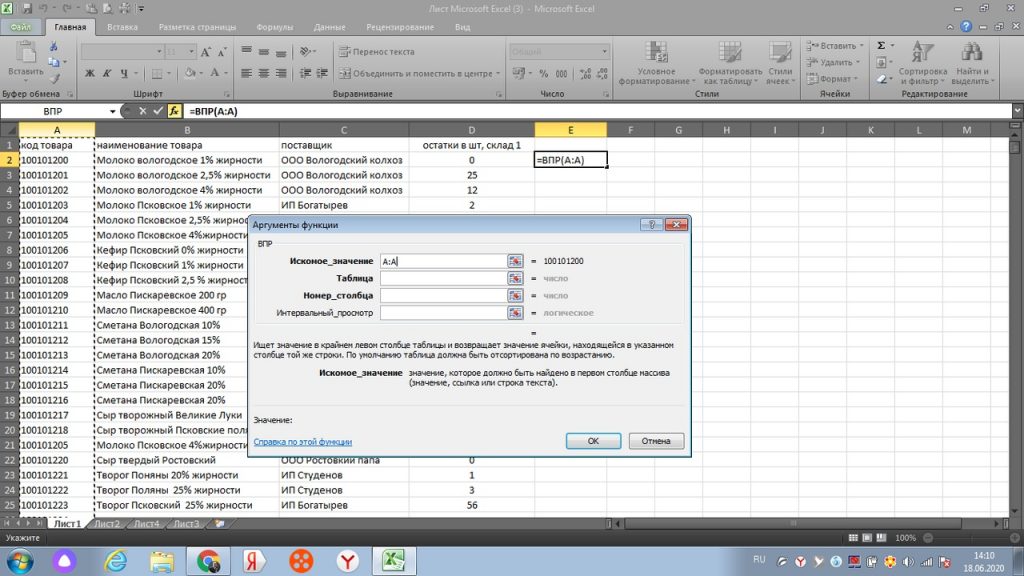
Далее, мышкой переходим в самом окошке на вторую строку «таблица», только после этого переходим на лист 2 нашего файла.
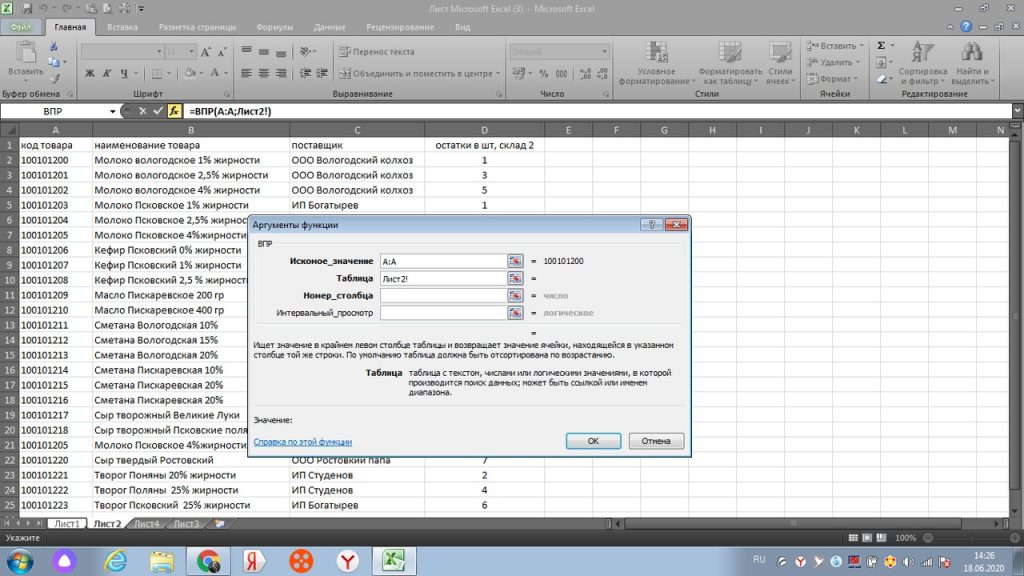
И от столбца «А» выделяем и протягиваем к столбцу с количеством. В данном случае, к столбцу «D», см рис 25.
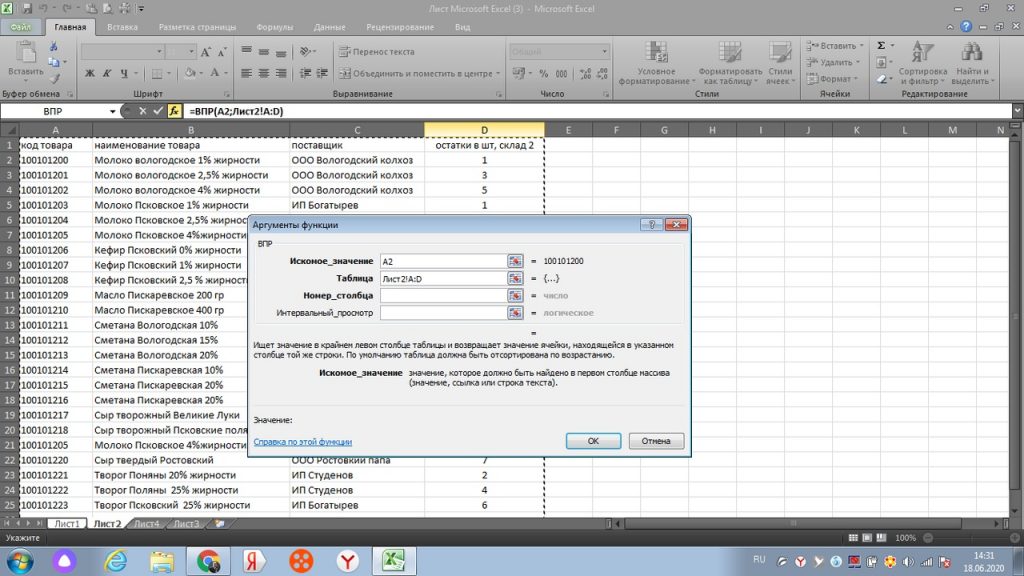
Столбец D, это четвертый столбец начиная с искомого значения, то есть с кода товара в столбце А.
Поэтому, мы ставим в третьем поле окошка «номер столбца» цифру 4. и в поле «интервальный просмотр» всего ноль. В итоге у нас получается заполненное окошко, см рис 26.
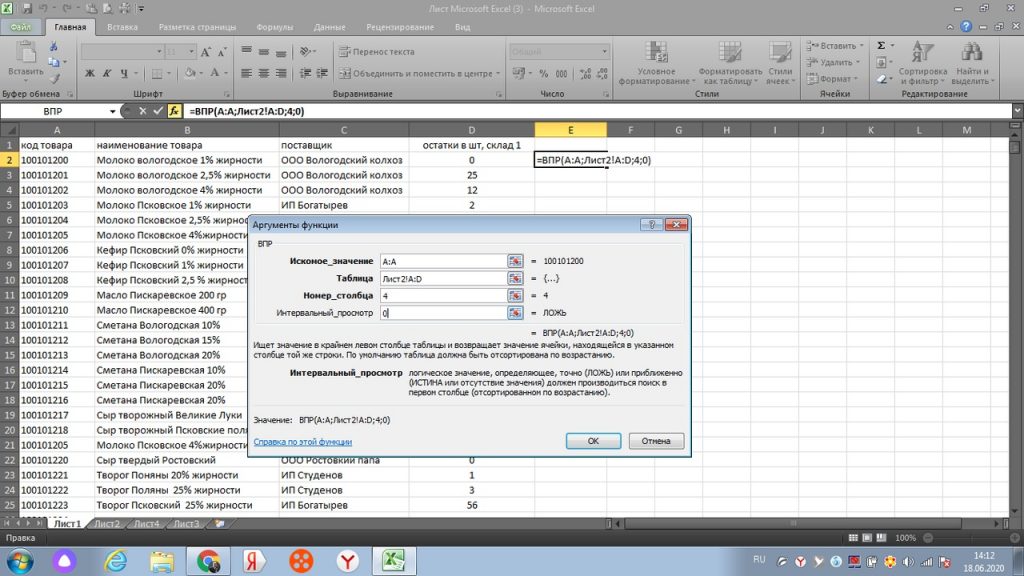
Нажимаем «ок», и получаем подтянутую цифру со второго листа, по коду товара 100101200. см. рис 27.
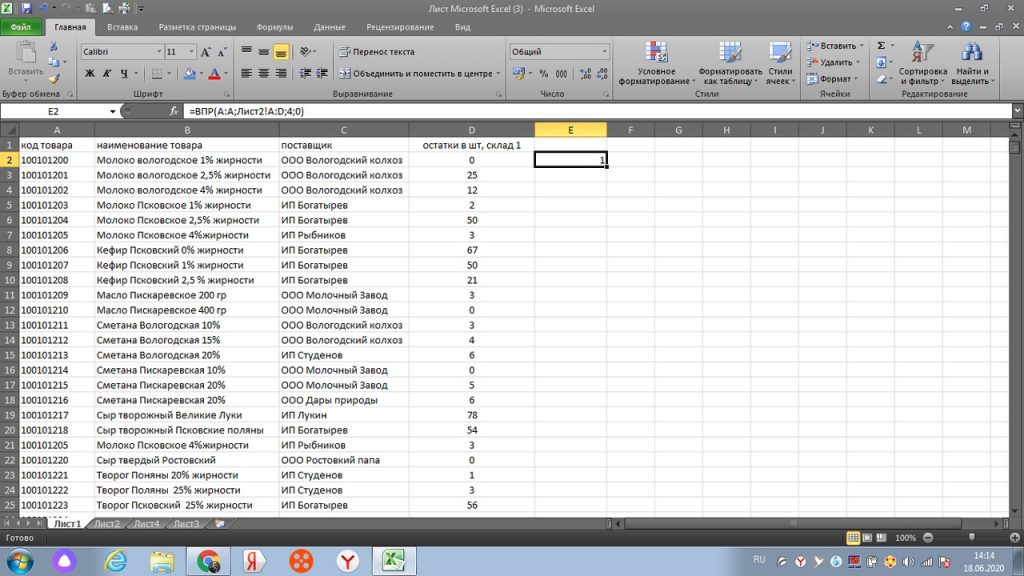
Протягиваем значение вниз, столбец D заполняется цифрами с листа 2. см. рис 28. Здесь нам остается просто сложить одни цифры с другими простой формулой сложения и протянуть вниз.
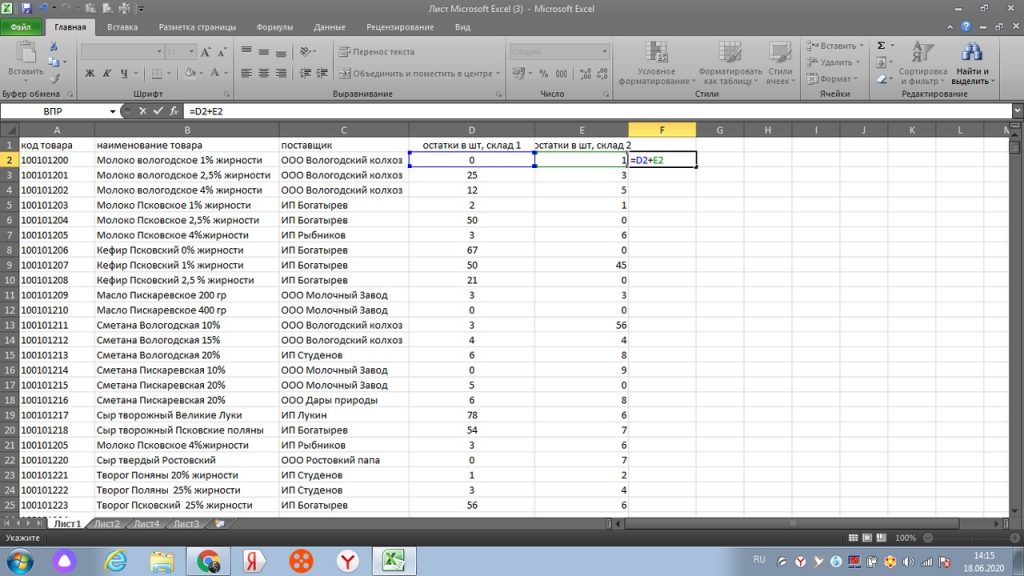
Таким образом, мы можем подтянуть значение из большого массива данных, которое вручную искать долго и не целесообразно, если есть функция ВПР.
Важный момент. Если Вы подтягиваете из другого файла, то файлы должны быть сохранены. И еще. Формулы подтянутых значений остаются. Вам нужна цифры привести в значения или не удалять и не менять значения, которые Вы подтягивали.
Как в excel обработать большой объем данных, функция правсимв и левсимв
Бывает, что необходимо для работы с функцией ВПР, привести искомые значения, и значение которые мы подтягиваем в единую форму. Как мы говорили выше, для ВПР любое отклонение, даже пробел, это уже другое значение.
Для этого, нам в помощь функция excel: правсимв и левсимв. То есть с помощью этой функции можно слева или справа нашего значения, например наименования товара, убрать лишние знаки.
Итак,, нам нужно взять только часть от полного наименования. Смотрим наш рис 29, к примеру, нам нужно только слово «молоко». Мы также в окне поиска формул ищем = левсимв.
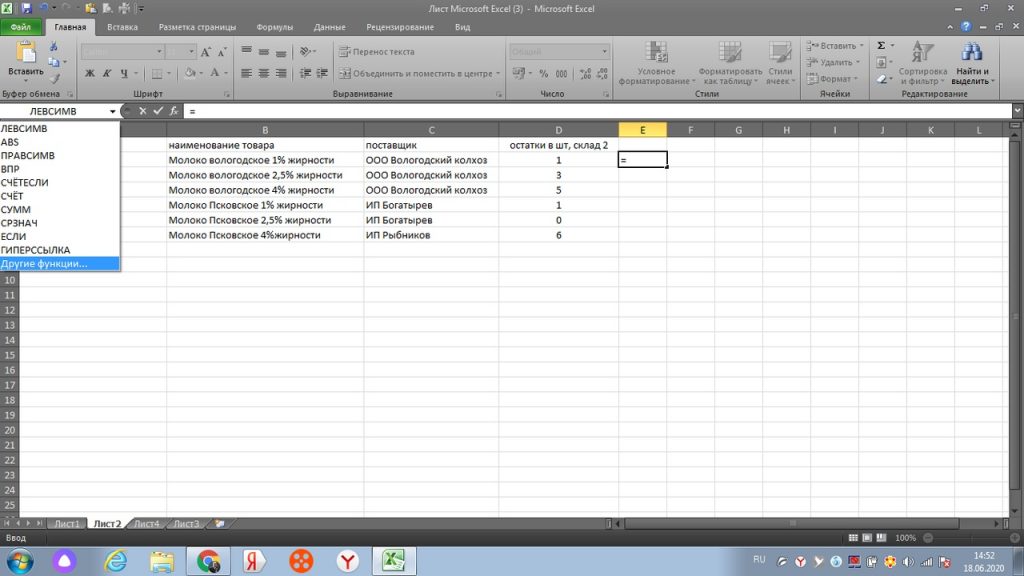
У нас появляется окошко, см рис 30.
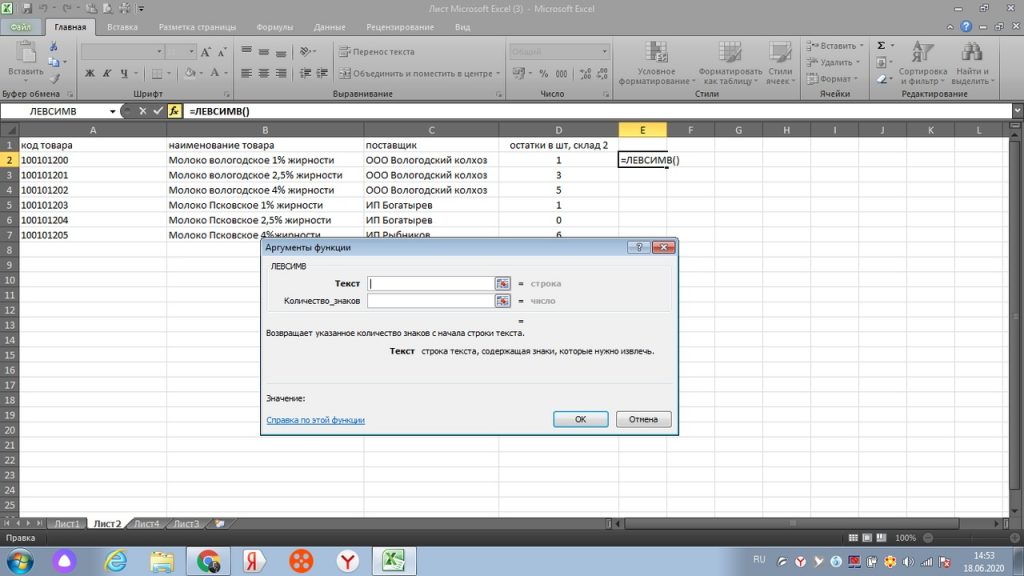
Мы выделяем интересующий нас столбец «В», в строке «текст» он появляется как В:В, см рис 31.
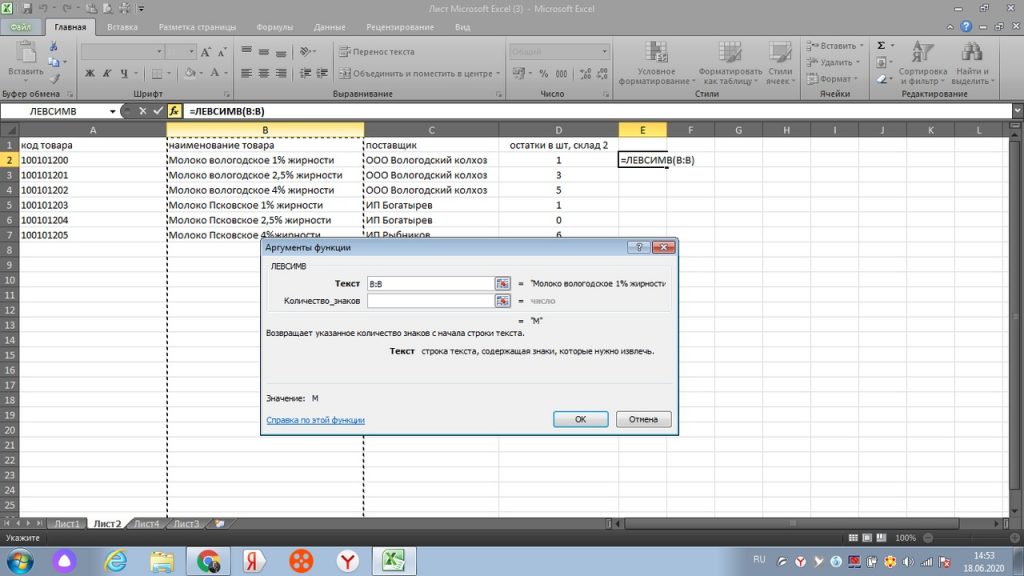
Далее, в строку «количество знаков» мы ставим ту цифру, сколько букв или символов содержит слово или слова с пробелом начиная с левой стороны. Если нам нужно только слово «молоко», то в нем, с учетом пробела 7 букв, поэтому, ставим цифру 7. См. рис 32.
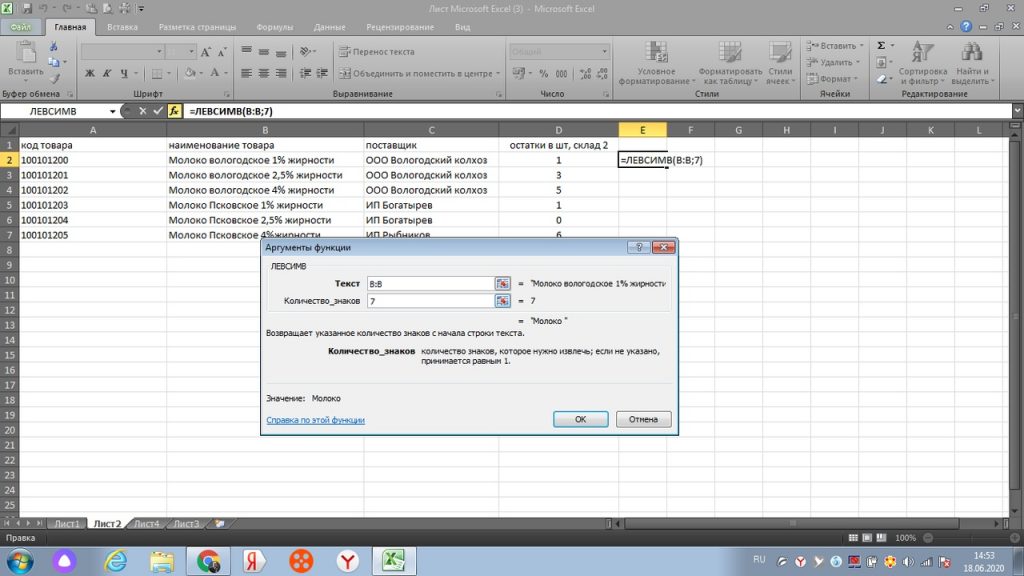
Вот и обрезалось наше наименование только в нужное нам слово, см. рис 33.
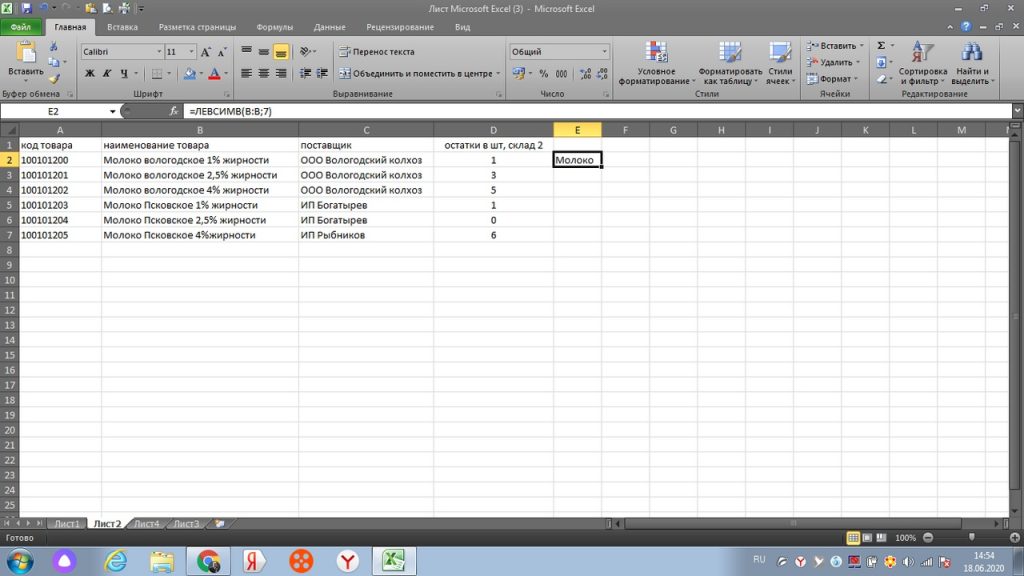
Теперь остается только «протянуть» вниз, и все значения с первыми 7-ю символами с левой стороны, будут в нашей таблице., см рис 34.
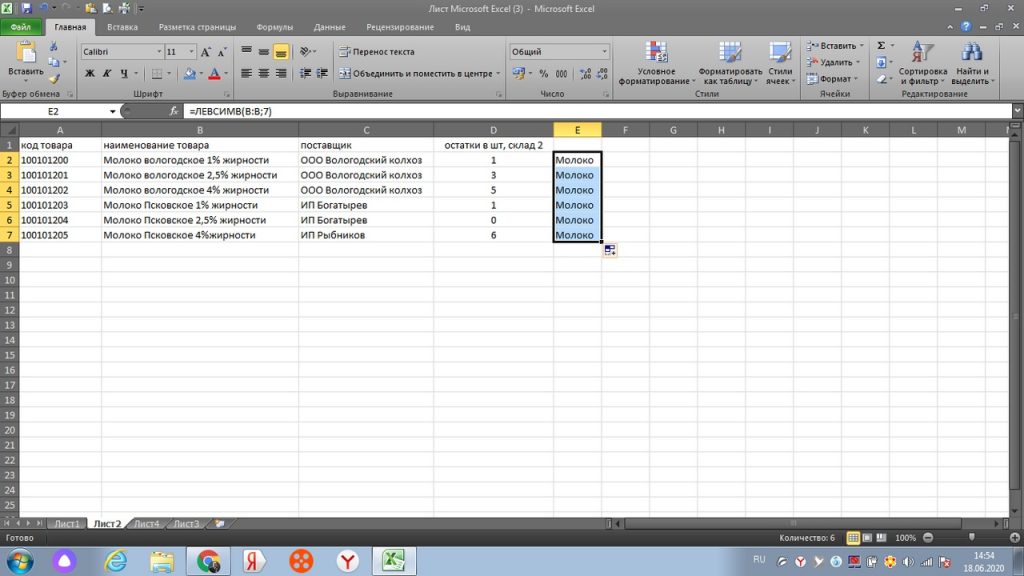
По аналогии, можно пользоваться функцией ПРАВСИМВ. Здесь все тоже самое, только символы оставляет с правой стороны. Эту функцию часто применяют на числовых значениях, когда код имеет дополнительные обозначения или отделяется, например точкой.
Заключение
Я отдельно сделал статью, как в excel вести учет и планирование товарных запасов. Ели интересно, статью можно почитать здесь.
Чтобы не утяжелять прочтение, разделю материал на две части. В следующей части пойдет речь о том, как в excel обработать большой объем данных с помощью функции СЦЕПИТЬ, построения графиков и диаграмм. Как автоматически подсветить значения верхнего или нижнего порога, и как седлать пароль на страницу или всю книгу в excel, и так далее.
Надеюсь материал был полезным, всего Вам хорошего. Успехов!
Анализ данных в Excel предполагает сама конструкция табличного процессора. Очень многие средства программы подходят для реализации этой задачи.
Excel позиционирует себя как лучший универсальный программный продукт в мире по обработке аналитической информации. От маленького предприятия до крупных корпораций, руководители тратят значительную часть своего рабочего времени для анализа жизнедеятельности их бизнеса. Рассмотрим основные аналитические инструменты в Excel и примеры применения их в практике.
Инструменты анализа Excel
Одним из самых привлекательных анализов данных является «Что-если». Он находится: «Данные»-«Работа с данными»-«Что-если».
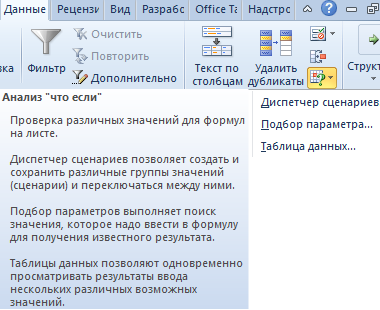
Средства анализа «Что-если»:
- «Подбор параметра». Применяется, когда пользователю известен результат формулы, но неизвестны входные данные для этого результата.
- «Таблица данных». Используется в ситуациях, когда нужно показать в виде таблицы влияние переменных значений на формулы.
- «Диспетчер сценариев». Применяется для формирования, изменения и сохранения разных наборов входных данных и итогов вычислений по группе формул.
- «Поиск решения». Это надстройка программы Excel. Помогает найти наилучшее решение определенной задачи.
Практический пример использования «Что-если» для поиска оптимальных скидок по таблице данных.
Другие инструменты для анализа данных:
Анализировать данные в Excel можно с помощью встроенных функций (математических, финансовых, логических, статистических и т.д.).
Сводные таблицы в анализе данных
Чтобы упростить просмотр, обработку и обобщение данных, в Excel применяются сводные таблицы.
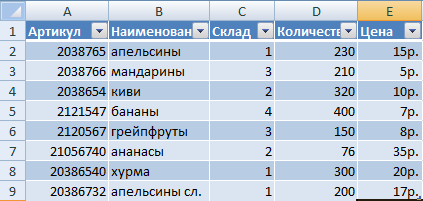
Программа будет воспринимать введенную/вводимую информацию как таблицу, а не простой набор данных, если списки со значениями отформатировать соответствующим образом:
- Перейти на вкладку «Вставка» и щелкнуть по кнопке «Таблица».
- Откроется диалоговое окно «Создание таблицы».
- Указать диапазон данных (если они уже внесены) или предполагаемый диапазон (в какие ячейки будет помещена таблица). Установить флажок напротив «Таблица с заголовками». Нажать Enter.
К указанному диапазону применится заданный по умолчанию стиль форматирования. Станет активным инструмент «Работа с таблицами» (вкладка «Конструктор»).
Составить отчет можно с помощью «Сводной таблицы».
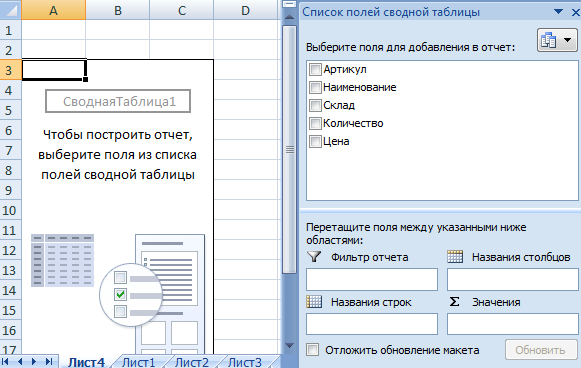
- Активизируем любую из ячеек диапазона данных. Щелкаем кнопку «Сводная таблица» («Вставка» — «Таблицы» — «Сводная таблица»).
- В диалоговом окне прописываем диапазон и место, куда поместить сводный отчет (новый лист).
- Открывается «Мастер сводных таблиц». Левая часть листа – изображение отчета, правая часть – инструменты создания сводного отчета.
- Выбираем необходимые поля из списка. Определяемся со значениями для названий строк и столбцов. В левой части листа будет «строиться» отчет.
Создание сводной таблицы – это уже способ анализа данных. Более того, пользователь выбирает нужную ему в конкретный момент информацию для отображения. Он может в дальнейшем применять другие инструменты.
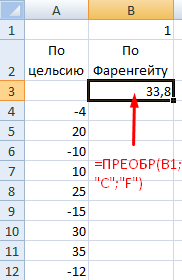
Анализ «Что-если» в Excel: «Таблица данных»
Мощное средство анализа данных. Рассмотрим организацию информации с помощью инструмента «Что-если» — «Таблица данных».
Важные условия:
- данные должны находиться в одном столбце или одной строке;
- формула ссылается на одну входную ячейку.
Процедура создания «Таблицы данных»:
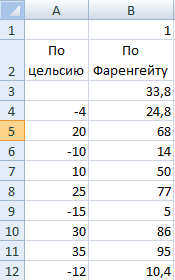
- Заносим входные значения в столбец, а формулу – в соседний столбец на одну строку выше.
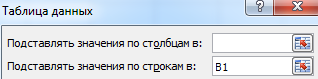
- Выделяем диапазон значений, включающий столбец с входными данными и формулой. Переходим на вкладку «Данные». Открываем инструмент «Что-если». Щелкаем кнопку «Таблица данных».
- В открывшемся диалоговом окне есть два поля. Так как мы создаем таблицу с одним входом, то вводим адрес только в поле «Подставлять значения по строкам в». Если входные значения располагаются в строках (а не в столбцах), то адрес будем вписывать в поле «Подставлять значения по столбцам в» и нажимаем ОК.
Анализ предприятия в Excel: примеры
Для анализа деятельности предприятия берутся данные из бухгалтерского баланса, отчета о прибылях и убытках. Каждый пользователь создает свою форму, в которой отражаются особенности фирмы, важная для принятия решений информация.
- скачать систему анализа предприятий;
- скачать аналитическую таблицу финансов;
- таблица рентабельности бизнеса;
- отчет по движению денежных средств;
- пример балльного метода в финансово-экономической аналитике.
Для примера предлагаем скачать финансовый анализ предприятий в таблицах и графиках составленные профессиональными специалистами в области финансово-экономической аналитике. Здесь используются формы бухгалтерской отчетности, формулы и таблицы для расчета и анализа платежеспособности, финансового состояния, рентабельности, деловой активности и т.д.
Если вам по работе или учёбе приходится погружаться в океан цифр и искать в них подтверждение своих гипотез, вам определённо пригодятся эти техники работы в Microsoft Excel. Как их применять — показываем с помощью гифок.

Юлия Перминова
Тренер Учебного центра Softline с 2008 года.
1. Сводные таблицы
Базовый инструмент для работы с огромным количеством неструктурированных данных, из которых можно быстро сделать выводы и не возиться с фильтрацией и сортировкой вручную. Сводные таблицы можно создать с помощью нескольких действий и быстро настроить в зависимости от того, как именно вы хотите отобразить результаты.
Полезное дополнение. Вы также можете создавать сводные диаграммы на основе сводных таблиц, которые будут автоматически обновляться при их изменении. Это полезно, если вам, например, нужно регулярно создавать отчёты по одним и тем же параметрам.
Как работать
Исходные данные могут быть любыми: данные по продажам, отгрузкам, доставкам и так далее.
- Откройте файл с таблицей, данные которой надо проанализировать.
- Выделите диапазон данных для анализа.
- Перейдите на вкладку «Вставка» → «Таблица» → «Сводная таблица» (для macOS на вкладке «Данные» в группе «Анализ»).
- Должно появиться диалоговое окно «Создание сводной таблицы».
- Настройте отображение данных, которые есть у вас в таблице.
Перед нами таблица с неструктурированными данными. Мы можем их систематизировать и настроить отображение тех данных, которые есть у нас в таблице. «Сумму заказов» отправляем в «Значения», а «Продавцов», «Дату продажи» — в «Строки». По данным разных продавцов за разные годы тут же посчитались суммы. При необходимости можно развернуть каждый год, квартал или месяц — получим более детальную информацию за конкретный период.
Набор опций будет зависеть от количества столбцов. Например, у нас пять столбцов. Их нужно просто правильно расположить и выбрать, что мы хотим показать. Скажем, сумму.
Можно её детализировать, например, по странам. Переносим «Страны».
Можно посмотреть результаты по продавцам. Меняем «Страну» на «Продавцов». По продавцам результаты будут такие.
2. 3D-карты
Этот способ визуализации данных с географической привязкой позволяет анализировать данные, находить закономерности, имеющие региональное происхождение.
Полезное дополнение. Координаты нигде прописывать не нужно — достаточно лишь корректно указать географическое название в таблице.
Как работать
- Откройте файл с таблицей, данные которой нужно визуализировать. Например, с информацией по разным городам и странам.
- Подготовьте данные для отображения на карте: «Главная» → «Форматировать как таблицу».
- Выделите диапазон данных для анализа.
- На вкладке «Вставка» есть кнопка 3D-карта.
Точки на карте — это наши города. Но просто города нам не очень интересны — интересно увидеть информацию, привязанную к этим городам. Например, суммы, которые можно отобразить через высоту столбика. При наведении курсора на столбик показывается сумма.
Также достаточно информативной является круговая диаграмма по годам. Размер круга задаётся суммой.
3. Лист прогнозов
Зачастую в бизнес-процессах наблюдаются сезонные закономерности, которые необходимо учитывать при планировании. Лист прогноза — наиболее точный инструмент для прогнозирования в Excel, чем все функции, которые были до этого и есть сейчас. Его можно использовать для планирования деятельности коммерческих, финансовых, маркетинговых и других служб.
Полезное дополнение. Для расчёта прогноза потребуются данные за более ранние периоды. Точность прогнозирования зависит от количества данных по периодам — лучше не меньше, чем за год. Вам требуются одинаковые интервалы между точками данных (например, месяц или равное количество дней).
Как работать
- Откройте таблицу с данными за период и соответствующими ему показателями, например, от года.
- Выделите два ряда данных.
- На вкладке «Данные» в группе нажмите кнопку «Лист прогноза».
- В окне «Создание листа прогноза» выберите график или гистограмму для визуального представления прогноза.
- Выберите дату окончания прогноза.
В примере ниже у нас есть данные за 2011, 2012 и 2013 годы. Важно указывать не числа, а именно временные периоды (то есть не 5 марта 2013 года, а март 2013-го).
Для прогноза на 2014 год вам потребуются два ряда данных: даты и соответствующие им значения показателей. Выделяем оба ряда данных.
На вкладке «Данные» в группе «Прогноз» нажимаем на «Лист прогноза». В появившемся окне «Создание листа прогноза» выбираем формат представления прогноза — график или гистограмму. В поле «Завершение прогноза» выбираем дату окончания, а затем нажимаем кнопку «Создать». Оранжевая линия — это и есть прогноз.
4. Быстрый анализ
Эта функциональность, пожалуй, первый шаг к тому, что можно назвать бизнес-анализом. Приятно, что эта функциональность реализована наиболее дружественным по отношению к пользователю способом: желаемый результат достигается буквально в несколько кликов. Ничего не нужно считать, не надо записывать никаких формул. Достаточно выделить нужный диапазон и выбрать, какой результат вы хотите получить.
Полезное дополнение. Мгновенно можно создавать различные типы диаграмм или спарклайны (микрографики прямо в ячейке).
Как работать
- Откройте таблицу с данными для анализа.
- Выделите нужный для анализа диапазон.
- При выделении диапазона внизу всегда появляется кнопка «Быстрый анализ». Она сразу предлагает совершить с данными несколько возможных действий. Например, найти итоги. Мы можем узнать суммы, они проставляются внизу.
В быстром анализе также есть несколько вариантов форматирования. Посмотреть, какие значения больше, а какие меньше, можно в самих ячейках гистограммы.
Также можно проставить в ячейках разноцветные значки: зелёные — наибольшие значения, красные — наименьшие.
Надеемся, что эти приёмы помогут ускорить работу с анализом данных в Microsoft Excel и быстрее покорить вершины этого сложного, но такого полезного с точки зрения работы с цифрами приложения.
Читайте также:
- 10 быстрых трюков с Excel →
- 20 секретов Excel, которые помогут упростить работу →
- 10 шаблонов Excel, которые будут полезны в повседневной жизни →
| Содержание |
|---|
| Описание примеров |
| Применение метода |
| Суммирование по одному ключевому полю |
| Суммирование по нескольким критериям |
| Поиск по одному критерию |
| Поиск по нескольким критериям |
| Выборка по одному критерию |
| Выборка вариантов |
| Заключение |
Одним из самых популярных методов использования электронных таблиц является обработка данных, полученных из учетных систем. Современные базы данных, используемые учетными системами в качестве хранилища информации, способны накапливать и обрабатывать в собственных структурах десятки, а иногда сотни тысяч информационных записей в день. Средства анализа в системах управления базами данных реализуются либо на программном уровне, либо через специальные интерфейсы и языки запросов. Электронные таблицы позволяют эффективно обработать данные без знания языков программирования и других технических средств.
Методы переноса данных в Excel могут быть различны:
- Копирование-вставка результатов запросов
- Использование стандартных процедур импорта (например, Microsoft Query) для формирования данных на рабочих листах
- Использование программных средств для доступа к базам данных с последующим переносом информации в диапазоны ячеек
- Непосредственный доступ к данным без копирования информации на рабочие листы
- Подключение к OLAP-кубам
Данные, полученные из учетных систем, обычно характеризуются большим объемом – количество строк может составлять десятки тысяч, количество столбцов при этом часто невелико, так как языки запросов к базам данным сами имеют ограничение на одновременно выводимое количество полей.
Обработка этих данных в Excel может вестись различными методами. Выделим основные способы работы:
- Обработка данных стандартными средствами интерфейса Excel
- Анализ данных при помощи сводных таблиц и диаграмм
- Консолидация данных при помощи формул рабочего листа
- Выборка данных и заполнение шаблонов для получения отчета
- Программная обработка данных
Правильность выбора способа работы с данными зависит от конкретной задачи. У каждого метода есть свои преимущества и недостатки.
В данной статье будут рассмотрены способы консолидации и выборки данных при помощи стандартных формул Excel.
Описание примеров
Примеры к статье построены на основе демонстрационной базы данных, которую можно скачать с сайта Microsoft
http://www.microsoft.com/download/en/details.aspx?displaylang=en&id=19704
Выгруженный из этой базы данных набор записей сформирован при помощи Microsoft Query.
Данные не несут специальной смысловой нагрузки и используются только в качества произвольного набора записей, имеющих несколько ключевых полей.

Файл nwdata_sums.xls используется для версий Excel 2000-2003
Файл nwdata_sums.xlsx имеет некоторые отличия и используется для версий Excel 2007-2010.
Первый лист data содержит исходные данные, остальные – примеры различных формул для обработки информации.
Ячейки, окрашенные в серый цвет, содержат служебные формулы. Ячейки желтого цвета содержат ключевые значения, которые могут быть изменены.
Применение метода
Очевидно, самым простым и удобным методом обработки больших объемов данных с точки зрения пользователя являются сводные таблицы. Этот интерфейс специально создавался для подобного рода задач, способен работать с различными источниками данных, поддерживает интерфейсные методы фильтрации, группировки, сортировки, а также автоматической агрегации данных различными способами.
Проблема при консолидации данных при помощи сводных таблиц появляются, если предполагается дальнейшая работа с этими агрегированными данными. Например, сравнить или дополнить данные из двух разных сводных таблиц (как вариант: объемы продаж и прайс листы). В таком случае обычно прибегают к методу копирования значений из сводных таблиц в промежуточные диапазоны с дальнейшим применением формул поиска (VLOOKUP/HLOOKUP). Очевидно, что проблема возникает при обновлении исходных данных (например, при добавлении новых строк) – требуется заново копировать результаты консолидации из сводной таблицы. Другим, с нашей точки зрения, не совсем корректным методом решения является применение функций поиска непосредственно к диапазонам, которые занимают сводные таблицы. Это может привести к неверному поиску при обновлении не только данных, но и внешнего вида сводной таблицы.
Еще один классический пример непригодности применения сводной таблицы – это требование формирования отчета в заранее предопределенном виде («начальство требует в такой форме и никак иначе»). Возможностей настройки сводной таблицы зачастую недостаточно для предоставления произвольной формы. В данном случае пользователи также обычно используют копирование результатов агрегирования в качестве значений.
Самым правильным методом обработки данных в приведенных случаях, с нашей точки зрения, является применение функций рабочего листа для консолидации данных. Этот метод требует иногда больших затрат времени на создание формул, но зато в дальнейшем при изменении исходных данных отчеты будут обновляться автоматически. Файлы примеров показывают различные варианты применения функция рабочего листа для обработки данных.
Суммирование по одному ключевому полю
Таблицы с формулами на листе SUM показывают вариант решения задачи консолидации данных по одному ключевому значению.

Две верхние таблицы на листе демонстрируют возможности стандартной функции SUMIF, которая как раз и предназначена для суммирования с проверкой одного критерия.
SUM!B5
=SUMIF(data!$H:$H;A5;data!$M:$M)
SUM!B11
=SUMIF(data!$Z:$Z;A11;data!$M:$M)
Нижние таблицы показывают возможности другой редко используемой функции DSUM
SUM!B19
=DSUM(data!$A$1:$AJ$2156;"Quantity";D18:D19)
Первый параметр определяет рабочий диапазон данных. Причем верхняя строка диапазона должна содержать заголовки полей. Второй параметр указывает наименование поля (столбца) для суммирования. Третий параметр ссылается на диапазон условий суммирования. Этот диапазон должен состоять как минимум из двух строк, верхняя строка – поле критерия, вторая и последующие — условия.
В другом варианте указания условий именем поля в этом диапазоне можно пренебречь, задав его прямо в тексте условия:
SUM!B28
=DSUM(data!$A$1:$AJ$2156;"Quantity";D27:D28)
SUM!D28
Здесь data!Z2 означает ссылку на текущую строку данных, а не на конкретную ячейку, так как используется относительная ссылка. К сожалению, нельзя указать в третьем параметры ссылку на одну ячейку – строка заголовка полей все равно требуется, хотя и может быть пустой.
В принципе, функции типа DSUM являются устаревшим методом работы с данными, в подавляющем большинстве случаев лучше использовать SUMIF, SUMPRODUCT или формулы обработки массивов. Но иногда их применение может дать хороший результат, например, при совместном использовании с интерфейсной возможностью «расширенный фильтр» – в обоих случаях используется одинаковое описание условий через дополнительные диапазоны.
Суммирование по нескольким критериям
Таблицы с формулами на листе SUM2 показывают вариант суммирования по нескольким критериям.

Первый вариант решения использует дополнительно подготовленный столбец обработанных исходных данных. В реальных задачах логичнее добавлять такой столбец с формулами непосредственно на лист данных.
SUM!D5
=SUMIF(A:A;B5 & ";" & C5;data!M:M)
Операция «&» используется для соединения строк. Можно также вместо этого оператора использовать функцию CONCATENATE. Промежуточный символ «;» (или любой другой служебный символ) необходим для обеспечения уникальности сцепленных строковых значений.
Пример: Есть, если два поля с перечнем слов. Пары слов «СТОЛ»-«ОСЬ» и «СТО»-«ЛОСЬ» дают одинаковый ключ «СТОЛОСЬ». Что соответственно даст неверный результат при консолидации данных. При использовании служебного символа комбинации ключей будут уникальны «СТОЛ;ОСЬ» и «СТО;ЛОСЬ», что обеспечит корректность вычислений.
Использовать подобную методику создания уникального ключа можно не только для строковых, но и для числовых целочисленных полей.
Второй пример – это популярный вариант использования функции SUMPRODUCT с проверкой условий в виде логического выражения:
SUM!D13
=SUMPRODUCT((data!$H$2:$H$3000=B13)*(data!$Z$2:$Z$3000=C13)*data!$M$2:$M$3000)
Обрабатываются все ячейки диапазона (data!$M$2:$M$3000), но для тех ячеек, где условия не выполняются, в суммирование попадает нулевое значение (логическая константа FALSE приводится к числу «0»). Такое использование этой функции близко по смыслу к формулам обработки массива, но не требует ввода через Ctrl+Shift+Enter.
Третий пример аналогичен, описанному использованию функций DSUM для листа SUM, но в нем для диапазона условий использовано несколько полей.
SUM!D21
=DSUM(data!$A$1:$AJ$2156;"Quantity";F20:G21)
Четвертый пример – это использование функций обработки массивов.
SUM!D32
{=SUM(IF(data!$H$2:$H$3000=B32;IF(data!$Z$2:$Z$3000=C32;data!$M$2:$M$3000)))}
Обработка массивов является самым гибким вариантом проверки условий. Но имеет очень сложную запись, трудно воспринимается пользователем и работает медленнее стандартных функций.
Пятый пример содержится только в файле формата Excel 2007 (xlsx). Он показывает возможности новой стандартной функции
SUMIFS
SUM!D40
=SUMIFS(data!$M$2:$M$3000;data!$H$2:$H$3000;B40;data!$Z$2:$Z$3000;C40)
Поиск по одному критерию
Таблицы с формулами на листе SEARCH предназначены для поиска по ключевому полю с выборкой другого поля в качестве результата.

Первый вариант – это использование популярной функции VLOOKUP.
SEARCH!B5
=VLOOKUP(A5;data!$H$1:$M$3000;6;0)
Во втором вариант использовать VLOOKUP нельзя, так как результирующее поле находится слева от искомого. В данном случае используется сочетание функций MATCH+OFFSET.
SEARCH!C13
=MATCH(A13;data!$Z$1:$Z$3000;0)
SEARCH!B13
=OFFSET(data!$M$1;C13-1;0)
Первая функция ищет нужную строку, вторая возвращает нужное значение через вычисляемую адресацию.
Поиск по нескольким критериям
Таблицы с формулами на листе SEARCH2 предназначены для поиска по нескольким ключевым полям.

В первом варианте используется техника использования служебного столбца, описанная в примере к листу SUM2:
SEARCH2!Е5
=VLOOKUP(C5 & ";" & D5;$A$1:$B$3000;2;0)
Второй вариант работы сложнее. Используется обработка массива, который образуется при помощи функций вычисляемой адресации:
SEARCH2!Е 12
{=OFFSET(data!$M$1;MATCH(C13 & ";" & D13; data!$H$1:$H$3000 & ";" & data!$Z$1:$Z$3000;0)-1;0)}
Четвертый и пятый параметр в функции OFFSET используется для образования массива и определяет его размерность в строках и столбцах.
Выборка по одному критерию
Таблица на листе SELECT показывает вариант фильтрации данных через формулы.

Предварительно определяется количество строк в выборке:
SELECT!С4
=COUNTIF(data!$H:$H;$A$5)
Служебный столбец содержит формулы для определения номеров строк для фильтра. Первая строка ищется через простую функцию:
SELECT!С5
=MATCH($A$5;data!$H$1:$H$3000;0)
Вторая и последующие строки ищутся в вычисляемом диапазоне с отступом от предыдущей найденной строки:
SELECT!С6
=MATCH($A$5;OFFSET(data!$H$1;C5;0; ROWS(data!$H$1:$H$3000)-C5;1);0)+C5
Результат выдается через функцию вычисляемой адресации:
SELECT!B6
=IF(ISNA(C6);"";OFFSET(data!$M$1;C6-1;0))
Вместо функции проверки наличия ошибки ISNA можно сравнивать текущую строку с максимальным количеством, так как это сделано в столбце A.
Для организации выборок при помощи формул необходимо знать максимально возможное количество строк в фильтре, чтобы создать в них формулы.
Выборка вариантов
Самый сложный вариант выборки по ключевому полю представлен на листе SELECT2. Формулы сами определяют все доступные ключевые значения второго критерия.

Первый служебный столбец содержит сцепленные строки ключевых полей. Второй столбец проверяет соответствие первому ключу и оставляет значение второго ключевого поля:
SELECT2!B2
=IF(LEFT(A2;LEN($D$5)) & ";" = $D$5 & ";"; data!Z2;"")
Третий служебный столбец проверяет значение второго ключа на уникальность:
SELECT2!C2
=IF(B2="";0;IF(ISNA(MATCH(B2;B$1:B1;0));COUNTIF(C$1:C1;">0")+1;0))
Результирующий столбец второго ключа ProductName ищет уникальные значения в служебном столбце C:
SELECT2!E5
=IF(ISNA(MATCH(ROWS($5:5);$C$1:$C$3000;0));"";OFFSET($B$1;MATCH(ROWS($5:5);$C$1:$C$3000;0)-1;0))
Столбец Quantity просто суммирует данные по двум критериям, используя технику, описанную на листе SUM2.
SELECT2!F5
=IF(E5="";"";SUMPRODUCT((data!$H$2:$H$3000=D5)*(data!$Z$2:$Z$3000=E5)*data!$M$2:$M$3000))
Заключение
Использование функций рабочего листа для консолидации и выборки данных является эффективным методом построения отчетов с обновляемым источником исходных данных. Недостатками этого метода являются повышенные требования к пользователю в части создания сложных формул, а также низкая производительность в сравнении, например, со сводными таблицами. Последний недостаток зависит от объема исходных данных, сложности формул консолидации и технических возможностей компьютера. В критических случаях рекомендуется использовать ручной режим пересчета формул рабочей книги Excel.
Смотри также
» Работа с ненормализированными данными
В приложении к статье файл с простой задачей суммирования диапазона по различным условиям. Как ни странно, подобные задачи…
» Простые формулы
В приложенном файле несколько примеров использования простых функций Excel нестандартным способом.
» Обработка больших объемов данных. Часть 3. Сводные таблицы
Третья статья, посвященная обработке больших объемов данных с помощью Excel, описывает преимущества использования сводных таблиц….
» Обработка больших объемов данных. Часть 2. Интерфейс
В статье систематизируются простые приемы обработки больших объемов данных при помощи стандартных методов интерфейса Excel. Информация…
» Суммирование несвязанных диапазонов
При обработке больших таблиц иногда возникает потребность получить итоговые значения на основе данных, расположенных в диапазонах…
Excel содержит огромное количество самых разнообразных функций, однако не все они нужны при анализе данных. В этой статье вы узнаете о 10 наиболее популярных функций, которые будут нужны при работе с информацией. Эти функции позволяют выполнить большинство задач, которые появляются при анализе данных.
1. ВПР
Эта функция является одной из самых популярных и часто используемых в Excel. Если вам необходимо найти данные в одном столбце в таблице и получить значение из другого столбца таблицы, то эта функция вам поможет. Ее синтаксис:
ВПР (искомое значение; таблица; номер столбца; интервальный просмотр)
— Искомое значение — это то значение, которое мы будем искать в таблице с данными
— Таблица — диапазон данных, в первом столбце которого мы будем искать искомое значение
—
Номер столбца — этот параметр обозначает, на какое количество столбцов
надо сдвинуться вправо в таблице для получения результата
—
Интервальный просмотр — Может принимать параметр 0 или ЛОЖЬ, что
обозначает что совпадение между искомым значением и значением в первом
столбце таблицы должен быть точным; либо 1 или ИСТИНА, соответственно
совпадение должно быть неточным. Настоятельно рекомендую использовать
только параметр ЛОЖЬ, иначе можно получать непредсказуемые результаты.

В примере выше мы ищем по фамилии Петров имя в таблице с базой данных по ФИО. В функции ВПР(E2;A1:C6;2;0) первый параметр (E2) — ссылка на ячейку с фамилией, по которой мы будем искать имя; второй параметр A1:C6 — ссылка на таблицу, в первом столбце которой мы ищем указанное в первом параметре значение; третий параметр «2» — из какого столбца справа извлекать значение; четвертый параметр «0» — точный поиск.
Если хотите изучить более подробно, как работает функция ВПР, прочитайте нашу статью «Функция ВПР в Excel».
2. ГПР
Функция ГПР выполняет туже задачу, что и ВПР, только она просматривает первую строку в поиске искомого значения и для получения результата сдвигается на указанное количество строк вниз.

Синтаксис функции следующий:
ГПР(искомое значение;таблица;номер строки;интервальный просмотр)
— Искомое значение — значение, которое мы ищем в строке.
— Таблица- диапазон данных на листе, где в первой строке мы ищем искомое значение и сдвигаемся на необходимое количество строк.
— Номер строки- числовое значение, указывающее на сколько строк вниз надо сместиться.
— Интервальный просмотр — ставьте всегда 0, тогда Эксель будет искать точное совпадение, что нам и нужно в большинстве случаев.
В примере выше мы ищем выручку за сентябрь в помесячном отчете по выручке. В формуле ГПР(A5;B1:M2;2;0) первый параметр (А5) — ссылка на месяц, по которому мы хотим получить выручку; второй параметр (B1:M2) — ссылка на таблицу, где в первой строке указаны месяцы, среди которых нам нужно найти выбранный; третий параметр «2» — из какой строки ниже мы будем получать данные; четвертый параметр «0» — ищем точное совпадение.
Если вы хотите более подробно изучить, как пользоваться функцией ГПР — прочитайте статью на нашем сайте «Функция ГПР в Excel».
3. ЕСЛИ
Функция ЕСЛИ является очень популярной в Excel. Она позволяет автоматически выполнять какое-либо действие, в зависимости от поставленного условия.

Функция ЕСЛИ выполняет проверку логического выражения и если выражение истинно, то поставляется одно значение и альтернативное, если ложь. Синтаксис следующий:
ЕСЛИ(логическое выражение; значение если истина; значение если ложь)
— Логическое выражение — выражение, которое по итогу своего вычисления должно вырнуться значение ИСТИНА или ЛОЖЬ.
— Значение, если истина — устанавливаем указанное значение, если логическое выражение вернуло ИСТИНА
— Значение, если ложь — устанавливает указанное значение, если логическое выражение вернуло ЛОЖЬ.
В примере выше мы хотим определить, получили ли мы за месяц выручку больше 500 рублей или нет. В формуле ЕСЛИ(B2>500;»Да»;»Нет») первый параметр (B2>500) проверяет, выручка за месяц больше 500 рублей или нет; второй параметр («Да») — функция вернет Да, если выручка больше 500 рублей и соответственно Нет (третий параметр), если выручка меньше.
Обратите внимание, что значения при истине или лжи могут быть не только текстовые, числовые, но также и функции(в том числе и ЕСЛИ), что позволяет реализовать достаточно сложные логические конструкции.
4. ЕСЛИОШИБКА
При работе с формулами в Excel, можно время от времени сталкиваться с различными ошибками. Так в примере ниже функция ВПР вернула ошибку #Н/Д из-за того, что в базе данных по ФИО нет искомой нами фамилии (более подробно об ошибке #Н/Д вы можете прочитать в этой статье: «Как исправить ошибку #Н/Д в Excel»)
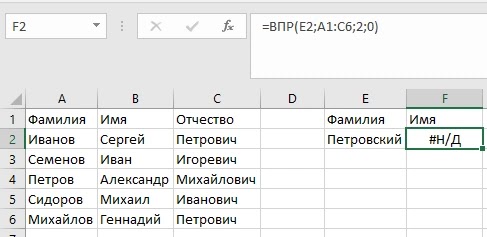
Для обработки таких ситуаций отлично подойдет функция ЕСЛИОШИБКА. Ее синтаксис следующий:
ЕСЛИОШИБКА(значение; значение если ошибка)
— Значение, результат которого проверяется на ошибку.
— Значение, если ошибка — В случае, если в результате работы функции получаем ошибку, то выводится не ошибка, а данное значение.
В случае с нашим примером выше, мы можем предположить, что фамилия может быть некорректной, соответственно ЕСЛИОШИБКА вернет нам предупреждение, что бы мы проверили написание фамилии.
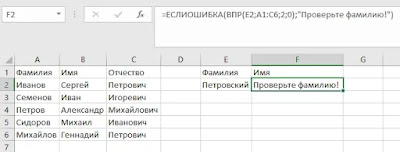
В примере выше, мы проверяем результат работы функции ВПР(E2;A1:C6;2;0) и в случае, если вернется ошибка, то выдаем сообщение «Проверьте фамилию!».
5. СУММЕСЛИМН
Функция СУММЕСЛИМН позволяет суммировать значения по определенным условиям. Условий может быть несколько. В Excel также есть функция СУММЕСЛИ, которая позволяет суммировать по одному критерию. Призываю вас использовать более универсальную формулу.

У функции СУММЕСЛИМН следующий синтаксис:
СУММЕСЛИМН(Диапазон суммирования; Диапазон условия 1; Условие 1;…)
— Диапазон суммирования — область листа Эксель, из которой мы суммируем данные
— Диапазон условия 1 — Диапазон ячеек, которые мы проверяем на соответствие условию
— Условие 1 — Условие, которое проверяется на соответствие в Диапазоне 1.
Обратите внимание, что диапазонов условий и соответственно условий может быть столько, сколько вам нужно.
Для примера выше мы хотим получит выручку, которую принес нам Петров в городе Москва. Формула имеет вид СУММЕСЛИМН(C2:C13;A2:A13;E2;B2:B13;F2), где C2:C13 — диапазон со значениями выручки, которые необходимо просуммировать; А2:А13 — диапазон с фамилиями, которые мы будем проверять; Е2 — ссылка на конкретную фамилию; B2:B13 — ссылка на диапазон с городами; F2 — ссылка на конкретный город.
Более подробно о функциях СУММЕСЛИМН и СУММЕСЛИ рассказано в статье «СУММЕСЛИ и СУММЕСЛИМН в Excel».
6. СЧЁТЕСЛИМН
СЧЁТЕСЛИМН очень похожа на функцию СУММЕСЛИМН, только в отличии от нее, она не суммируется значения, а только считает количество ячеек, которые соответствуют определенным условиям. Как и в случае с СУММЕСЛИМН, у СЧЁТЕСЛИМН есть упрощенная форма СЧЁТЕСЛИ, который считает количество ячеек только по одному критерию, но лучше используйте более общий вариант.

Синтаксис у функции следующий:
СЧЁТЕСЛИМН(диапазон условия 1; условие 1;…)
— Диапазон условия 1 — Диапазон ячеек, которые проверяются на соответствие определенному условию.
— Условие 1 — Условие, которое определяет какие ячейки надо учитывать при подсчете.
Обратите внимания, что диапазонов условий и соответственно условий может быть несколько.
В примере выше, мы считаем сколько в таблице ячеек, в которых фамилия — Петров, а город — Москва. В формуле СЧЁТЕСЛИМН(A2:A13;E2;B2:B13;F2) диапазон A2:A13 — диапазон фамилий, которые мы проверяем, Е2 — та фамилия, которую мы ищем в диапазоне; B2:B13 — диапазон городов и соответственно F2 — город, который мы учитываем при подсчете ячеек. Получившееся число 3 — это количество строк в таблице, где фамилия равна Иванов, а город равен Москва.
7. СЖПРОБЕЛЫ
При работе с данными в Excel, мы можем получать их из разных источников, что может привести к тому, что получаемые значения имеют «мусорную» информацию, очень часто это лишние пробелы, которые надо удалить. Можно удалять вручную, но это долго и муторно. На выручку нам приходит функция СЖПРОБЕЛЫ, которая удаляет лишние пробелы, в случае если их больше одного подряд. Синтаксис у функции очень простой:
СЖПРОБЕЛЫ(текст)
— Текст — тот текст, из которого надо убрать лишние пробелы.

Как видно из примера выше, функция успешно удалила лишние пробелы из исходной строки.
8. ЛЕВСИМВ и ПРАВСИМВ
Функции ЛЕВСИМВ и ПРАВСИМВ возвращают определенное количество знаков с начала (ЛЕВСИМВ) либо с конца (ПРАВСИМВ) строки. Эти функции нужны для получения части строки. Синтаксис у функций однотипный:
ЛЕВСИМВ(текст; количество знаков)
ПРАВСИМВ(текст; количество знаков)
— Текст — то строковое выражение, из которого мы хотим получить часть.
— Количество знаков — число символов, которое мы хотим получить.

В примере выше мы из текста «Пример текста» извлекаем 6 символов слева и получаем текст «Пример».
9. СЦЕПИТЬ
Функция СПЕПИТЬ позволяет объединить значения из нескольких ячеек. Синтаксис у функции достаточно простой:
СЦЕПИТЬ(текст1; текст2;…)
— Текст 1 — Текст, который надо соединить в одну строку
— Текст 2 — Текст, который надо соединить в одну строку
Обратите внимание, что вы можете объединить до 255 текстовых значений.

В примере выше мы объединяем фамилию и имя. В функции СЦЕПИТЬ(A2;» «;B2), первый параметр(А2) — ссылка на ячейку с фамилией; второй параметр (» «) — пробел, что бы итоговый текст смотрелся нормально; третий параметр(В2) — ссылка на ячейку с именем.
10.ЗНАЧЕН
Часто данные, которые мы получаем из внешних источников, имеют текстовый формат и мы не можем производить с ними математических действий (складывать, вычитать и т.п.). Нам требуется сначала преобразовать текст в число, для этого используйте функцию ЗНАЧЕН. Синтаксис у функции следующий:
ЗНАЧЕН(текст)
— Текст — число, представленное в текстовом формате

Как видно в примере выше, у нас есть число 12522, которое представлено в виде текста, при помощи функции ЗНАЧЕН мы преобразовали его в число 12 522, с которым в дальнейшем можем работать, как с любыми другими числами.
Спасибо, что дочитали статью. Я постарался выбрать 10 наиболее полезных функций в Excel, которые нужны при анализе данных. Жду ваши комментарии.