
Модуль openpyxl обеспечивает довольно гибкое управление стилями, относительно простую работу с ними. Стили в электронных таблицах XLSX используются для изменения внешнего вида данных при отображении на экране. Они также используются для определения форматирования чисел.
Содержание:
- Аспекты применения стилей модулем
openpyxl. - Cтили ячеек электронной таблицы.
- Создания нового стиля на основе другого.
- Цвета для шрифтов, фона, границ.
- Применение стилей.
- Горизонтальное и вертикальное выравнивание текста.
- Оформление границ ячеек.
- Заливка ячеек цветом и цвет текста.
- Именованные стили
NamedStyle.- Создание именованного стиля.
- Встроенные в Excel стили.
Аспекты применения стилей модулем openpyxl.
Стили могут быть применены к следующим аспектам:
font: устанавливает размер шрифта, цвет, стиль подчеркивания и т. д.fill: устанавливает шаблон или градиент цвета заливки ячейки.border: устанавливает стиль границы ячейки.alignment: устанавливает выравнивание ячейки.
Ниже приведены значения по умолчанию установленные модулем openpyxl:
from openpyxl.styles import ( PatternFill, Border, Side, Alignment, Font, GradientFill ) # СТИЛЬ ШРИФТА font = Font( name='Calibri', size=11, bold=False, italic=False, vertAlign=None, underline='none', strike=False, color='FF000000' ) # ЗАЛИВКА ЯЧЕЕК fill = PatternFill(fill_type=None, fgColor='FFFFFFFF') # ГРАНИЦЫ ЯЧЕЕК border = Border( left=Side(border_style=None, color='FF000000'), right=Side(border_style=None, color='FF000000'), top=Side(border_style=None, color='FF000000'), bottom=Side(border_style=None, color='FF000000'), diagonal=Side(border_style=None, color='FF000000'), diagonal_direction=0, outline=Side(border_style=None, color='FF000000'), vertical=Side(border_style=None, color='FF000000'), horizontal=Side(border_style=None, color='FF000000') ) # ВЫРАВНИВАНИЕ В ЯЧЕЙКАХ alignment=Alignment( horizontal='general', vertical='bottom', text_rotation=0, wrap_text=False, shrink_to_fit=False, indent=0 )
Cтили ячеек электронной таблицы.
Существует два типа стилей: стили ячеек и именованные стили, также известные как шаблоны стилей.
Стили ячеек являются общими для объектов, и после того, как они были назначены, их нельзя изменить. Это предотвращает нежелательные побочные эффекты, такие как изменение стиля для большого количества ячеек при изменении только одной.
Например:
>>> from openpyxl.styles import colors >>> from openpyxl.styles import Font, Color >>> from openpyxl import Workbook >>> wb = Workbook() >>> ws = wb.active >>> ws['A1'].value = 'Ячейка `A1`' >>> ws['D4'].value = 'Ячейка `D4`' # задаем стиль шрифта текста - цвет ячейке >>> ft = Font(color="FF0000") # применяем стиль к ячейкам >>> ws['A1'].font = ft >>> ws['D4'].font = ft # это изменение не сработает >>> ws['D4'].font.italic = True # Если необходимо изменить шрифт, # то его необходимо переназначить новым стилем ws['A1'].font = Font(color="FF0000", italic=True) >>> wb.save('test.xlsx')
Создания нового стиля на основе другого.
Модуль openpyxl поддерживает копирование стилей.
Пример создания нового стиля на основе другого:
>>> from openpyxl.styles import Font >>> from copy import copy # задаем стиль >>> ft1 = Font(name='Arial', size=14) # копируем стиль >>> ft2 = copy(ft1) # а вот теперь на основе скопированного стиля # можно создать новый, изменив атрибуты >>> ft2.name = "Tahoma" # имя шрифта первого стиля >>> ft1.name # 'Arial' # имя шрифта нового стиля >>> ft2.name # 'Tahoma' # размер остался как у первого >>> ft2.size # copied from the # 14.0
Цвета для шрифтов, фона, границ.
Цвета для шрифтов, фона, границ и т.д. Можно задать тремя способами: индексированный, aRGB или тема. Индексированные цвета являются устаревшей реализацией, и сами цвета зависят от индекса, предоставленного в рабочей книге или в приложении по умолчанию. Цвета темы полезны для дополнительных оттенков цветов, но также зависят от темы, присутствующей в рабочей книге. Поэтому рекомендуется использовать цвета aRGB.
Цвета aRGB.
Цвета RGB устанавливаются с использованием шестнадцатеричных значений красного, зеленого и синего.
>>> from openpyxl.styles import Font >>> font = Font(color="FF0000")
Альфа-значение теоретически относится к прозрачности цвета, но это не относится к стилям ячеек. Значение по умолчанию 00 будет добавлено к любому простому значению RGB:
>>> from openpyxl.styles import Font >>> font = Font(color="00FF00") >>> font.color.rgb # '0000FF00'
Применение стилей.
Стили применяются непосредственно к ячейкам.
>>> from openpyxl import Workbook >>> from openpyxl.styles import Font, PatternFill >>> wb = Workbook() >>> ws = wb.active >>> c = ws['A1'] >>> c.value = 'Ячейка `A1`' >>> c.font = Font(size=12) # можно напрямую >>> ws['A2'].value = 'Ячейка `A2`' >>> ws['A2'].font = Font(size=12, bold=True) >>> wb.save('test.xlsx')
Стили также могут применяться к столбцам и строкам, но обратите внимание, что это относится только к ячейкам, созданным (в Excel) после закрытия файла. Если необходимо применить стили ко всем строкам и столбцам, то нужно применить стиль к каждой ячейке самостоятельно.
Это ограничение формата файла:
>>> col = ws.column_dimensions['A'] >>> col.font = Font(bold=True) >>> row = ws.row_dimensions[1] >>> row.font = Font(underline="single")
Горизонтальное и вертикальное выравнивание текста.
Горизонтальное и вертикальное выравнивание в ячейках выставляется атрибутом ячейки .alignment и классом Alignment().
Пример горизонтального выравнивания текста:
>>> from openpyxl import Workbook >>> from openpyxl.styles import Alignment >>> wb = Workbook() >>> ws = wb.active >>> ws['A1'].value = 1500 >>> ws['A2'].value = 1500 >>> ws['A3'].value = 1500 # выравниваем текст в ячейках стилями >>> ws['A1'].alignment = Alignment(horizontal='left') >>> ws['A2'].alignment = Alignment(horizontal='center') >>> ws['A3'].alignment = Alignment(horizontal='right') # сохраняем и смотрим что получилось >>> wb.save('test.xlsx')
Вертикальное выравнивание в основном применяется когда изменена высота строки или были объединены несколько ячеек.
Пример вертикального выравнивания данных в ячейке:
>>> from openpyxl import Workbook >>> from openpyxl.styles import Alignment >>> wb = Workbook() >>> ws = wb.active # объединим ячейки в диапазоне `B2:E2` >>> ws.merge_cells('B2:E2') # в данном случае крайняя верхняя-левая ячейка это `B2` >>> megre_cell = ws['B2'] # запишем в нее текст >>> megre_cell.value = 'Объединенные ячейки `B2 : E2`' # установить высоту строки >>> ws.row_dimensions[2].height = 30 # установить ширину столбца >>> ws.column_dimensions['B'].width = 40 # выравнивание текста >>> megre_cell.alignment = Alignment(horizontal="center", vertical="center") # сохраняем и смотрим что получилось >>> wb.save("test.xlsx")
Оформление границ ячеек.
Цвет и стиль границ/бордюров ячеек выставляется атрибутом ячейки .border и классом Border() совместно с классом Side().
При этом аргумент стиля границ ячеек border_style может принимать ОДИН из следующих значений: ‘dashDotDot’, ‘medium’, ‘dotted’, ‘slantDashDot’, ‘thin’, ‘hair’, ‘mediumDashDotDot’, ‘dashDot’, ‘double’, ‘mediumDashed’, ‘dashed’, ‘mediumDashDot’ и ‘thick’.
Пример стилизации границ одной ячейки:
>>> from openpyxl import Workbook >>> from openpyxl.styles import Border, Side >>> wb = Workbook() >>> ws = wb.active >>> cell = ws['B2'] # установить высоту строки >>> ws.row_dimensions[2].height = 30 # установить ширину столбца >>> ws.column_dimensions['B'].width = 40 # определим стили сторон >>> thins = Side(border_style="medium", color="0000ff") >>> double = Side(border_style="dashDot", color="ff0000") # рисуем границы >>> cell.border = Border(top=double, bottom=double, left=thins, right=thins) >>> wb.save("styled_border.xlsx")
Пример стилизации границ нескольких ячеек:
from openpyxl import Workbook from openpyxl.styles import Border, Side wb = Workbook() ws = wb.active # определим стили сторон thins = Side(border_style="thin", color="0000ff") double = Side(border_style="double", color="ff0000") # начинаем заполнение области ячеек 10x10 данными # при этом будем стилизировать границы области for r, row in enumerate(range(5, 15), start=1): for c, col in enumerate(range(5, 15), start=1): # это значение, которое будем записывать в ячейку val_cell = r*c # левая верхняя ячейка if r == 1 and c == 1: ws.cell(row=row, column=col, value=val_cell).border = Border(top=double, left=thins) # правая верхняя ячейка elif r == 1 and c == 10: ws.cell(row=row, column=col, value=val_cell).border = Border(top=double, right=thins) # верхние ячейки if r == 1 and c != 1 and c != 10: ws.cell(row=row, column=col, value=val_cell).border = Border(top=double) # левая нижняя ячейка elif r == 10 and c == 1: ws.cell(row=row, column=col, value=val_cell).border = Border(bottom=double, left=thins) # правая нижняя ячейка elif r == 10 and c == 10: ws.cell(row=row, column=col, value=val_cell).border = Border(bottom=double, right=thins) # нижние ячейки elif r == 10 and c != 1 and c != 10: ws.cell(row=row, column=col, value=val_cell).border = Border(bottom=double) # левые ячейки elif c == 1 and r != 1 and r != 10: ws.cell(row=row, column=col, value=val_cell).border = Border(left=thins) # правые ячейки elif c == 10 and r != 1 and r != 10: ws.cell(row=row, column=col, value=val_cell).border = Border(right=thins) else: # здесь ячейки просто заполняются данными ws.cell(row=row, column=col, value=val_cell) # сохраняем и смотрим что получилось wb.save("styled_border.xlsx")
Заливка ячеек цветом и цвет текста.
Цвет заливки ячеек выставляется атрибутом ячейки .fill и классом PatternFill().
Обязательный аргумент fill_type (по умолчанию равен None) класса PatternFill() может принимать значения:
- если
fill_type='solid', то нужно обязательно указывать аргумент цвета заливкиfgColor. - следующие значения аргумента
fill_typeприменяются самостоятельно (без аргументаfgColor) и представляют собой предустановленные цвета заливки :‘darkHorizontal’,‘lightDown’,‘lightGray’,‘darkDown’,‘darkGrid’,‘darkUp’,‘darkGray’,‘darkVertical’,‘darkTrellis’,‘mediumGray’,‘lightVertical’,‘lightTrellis’,‘lightGrid’,‘lightHorizontal’,‘gray0625’,‘lightUp’,‘gray125’.
Внимание: если аргумент fill_type не указан, то fgColor не будет иметь никакого эффекта!
Пример заливки одной ячейки:
>>> from openpyxl import Workbook >>> from openpyxl.styles import PatternFill, Font, Alignment >>> wb = Workbook() >>> ws = wb.active # объединим ячейки в диапазоне `B2:E2` >>> ws.merge_cells('B2:E2') >>> megre_cell = ws['B2'] # запишем в нее текст >>> megre_cell.value = 'Объединенные ячейки `B2 : E2`' # установить высоту строки >>> ws.row_dimensions[2].height = 30 # установить ширину столбца >>> ws.column_dimensions['B'].width = 40 # заливка ячейки цветом >>> megre_cell.fill = PatternFill('solid', fgColor="DDDDDD") # шрифт и цвет текста ячейки >>> megre_cell.font = Font(bold=True, color='FF0000', name='Arial', size=14) # ну и для красоты выровним текст >>> megre_cell.alignment = Alignment(horizontal='center', vertical='center') # сохраняем и смотрим что получилось >>> wb.save("cell_color.xlsx")
Именованные стили NamedStyle.
В отличие от простых стилей ячеек, именованные стили изменяемы и используется для объединения в себе нескольких стилей, таких как шрифты, границы, выравнивание и т. д. Они имеют смысл, когда необходимо применить форматирование к множеству разных ячеек одновременно. Об именованных стилях можно думать как о классах CSS при оформлении HTML-разметки. Именованные стили регистрируются в рабочей книге.
Примечание. После назначения ячейке именованного стиля, дальнейшие/дополнительные изменения этого стиля не повлияют на стиль ячейки.
Как только именованный стиль зарегистрирован в рабочей книге, на него можно ссылаться просто по имени.
Создание именованного стиля.
>>> from openpyxl.styles import NamedStyle, Font, Border, Side # создание переменной именованного стиля >>> name_style = NamedStyle(name="highlight") # применение стилей к созданной переменной >>> name_style.font = Font(bold=True, size=20) >>> bd = Side(style='thick', color="000000") >>> name_style.border = Border(left=bd, top=bd, right=bd, bottom=bd)
После создания именованного стиля его нужно зарегистрировать в рабочей книге:
>>> wb.add_named_style(name_style)
Именованные стили также будут автоматически зарегистрированы при первом назначении их ячейке:
>>> ws['A1'].style = name_style
После регистрации стиля в рабочей книге, применять его можно только по имени:
>>> ws['D5'].style = 'highlight'
Встроенные стили в Excel.
Спецификация включает в себя некоторые встроенные стили, которые также могут быть использованы. К сожалению, имена для этих стилей хранятся в их локализованных формах. OpenPyxl узнает только английские имена и только так, как они записаны в официальной документации.
Использование встроенных в Excel стилей здесь не рассматривается, так как при их применении могу возникать существенные искажения.
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
In this article, We are going to change the value in an Excel Spreadsheet using Python.
Method 1: Using openxml:
openpyxl is a Python library to read/write Excel xlsx/xlsm/xltx/xltm files. It was born from a lack of an existing library to read/write natively from Python the Office Open XML format. openpyxl is the library needed for the following task. You can install openpyxl module by using the following command in Python.
pip install openpyxl
Function used:
- load_workbook(): function used to read the excel spreadsheet
- workbook.active: points towards the active sheet in the excel spreadsheet
- workbook.save(): saves the workbook
Approach:
- Import openpyxl library
- Start by opening the spreadsheet and selecting the main sheet
- Write what you want into a specific cell
- Save the spreadsheet
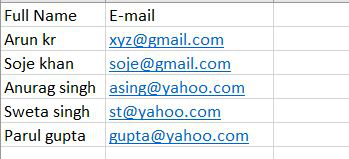
Excel File Used:

Below is the implementation:
Python3
from openpyxl import load_workbook
workbook = load_workbook(filename="csv/Email_sample.xlsx")
sheet = workbook.active
sheet["A1"] = "Full Name"
workbook.save(filename="csv/output.xlsx")
Output:
Method 1: Using xlwt/xlrd/xlutils.
This package provides a collection of utilities for working with Excel files. Since these utilities may require either or both of the xlrd and xlwt packages, they are collected together here, separate from either package.You can install xlwt/xlrd/xlutils modules by using the following command in Python
pip install xlwt pip install xlrd pip install xlutils
Prerequisite:
- open_workbook(): function used to read the excel spreadsheet
- copy(): copies the content of a workbook
- get_sheet(): points towards a specific sheet in excel workbook
- write(): writes data in the file
- save(): saves the file
Approach:
- Open Excel File
- Make a writable copy of the opened Excel file
- Read the first sheet to write within the writable copy
- Modify value at the desired location
- Save the workbook
- Run the program
Excel File Used:
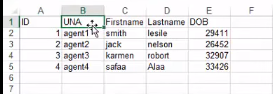
Below is the implementation:
Python3
import xlwt
import xlrd
from xlutils.copy import copy
rb = xlrd.open_workbook('UserBook.xls')
wb = copy(rb)
w_sheet = wb.get_sheet(0)
w_sheet.write(0,1,'Modified !')
wb.save('UserBook.xls')
Output:
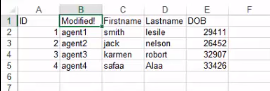
After
Like Article
Save Article
OpenPyXL gives you the ability to style your cells in many different ways. Styling cells will give your spreadsheets pizazz! Your spreadsheets can have some pop and zing to them that will help differentiate them from others. However, don’t go overboard! If every cell had a different font and color, your spreadsheet would look like a mess.
You should use the skills that you learn in this article sparingly. You’ll still have beautiful spreadsheets that you can share with your colleagues. If you would like to learn more about what styles OpenPyXL supports, you should check out their documentation.
In this article, you will learn about the following:
- Working with fonts
- Setting the alignment
- Adding a border
- Changing the cell background-color
- Inserting images into cells
- Styling merged cells
- Using a built-in style
- Creating a custom named style
Now that you know what you’re going to learn, it’s time to get started by discovering how to work with fonts using OpenPyXL!
Working with Fonts
You use fonts to style your text on a computer. A font controls the size, weight, color, and style of the text you see on-screen or in print. There are thousands of fonts that your computer can use. Microsoft includes many fonts with its Office products.
When you want to set a font with OpenPyXL, you will need to import the Font class from openpyxl.styles. Here is how you would do the import:
from openpyxl.styles import Font
The Font class takes many parameters. Here is the Font class’s full list of parameters according to OpenPyXL’s documentation:
class openpyxl.styles.fonts.Font(name=None, sz=None, b=None, i=None, charset=None, u=None,
strike=None, color=None, scheme=None, family=None, size=None, bold=None, italic=None,
strikethrough=None, underline=None, vertAlign=None, outline=None, shadow=None,
condense=None, extend=None)
The following list shows the parameters you are most likely to use and their defaults:
- name=’Calibri’
- size=11
- bold=False
- italic=False
- vertAlign=None
- underline=’none’
- strike=False
- color=’FF000000′
These settings allow you to set most of the things you’ll need to make your text look nice. Note that the color names in OpenPyXL use hexadecimal values to represent RGB (red, green, blue) color values. You can set whether or not the text should be bold, italic, underlined, or struck-through.
To see how you can use fonts in OpenPyXL, create a new file named font_sizes.py and add the following code to it:
# font_sizes.py
import openpyxl
from openpyxl.styles import Font
def font_demo(path):
workbook = openpyxl.Workbook()
sheet = workbook.active
cell = sheet["A1"]
cell.font = Font(size=12)
cell.value = "Hello"
cell2 = sheet["A2"]
cell2.font = Font(name="Arial", size=14, color="00FF0000")
sheet["A2"] = "from"
cell2 = sheet["A3"]
cell2.font = Font(name="Tahoma", size=16, color="00339966")
sheet["A3"] = "OpenPyXL"
workbook.save(path)
if __name__ == "__main__":
font_demo("font_demo.xlsx")
This code uses three different fonts in three different cells. In A1, you use the default, which is Calibri. Then in A2, you set the font size to Arial and increase the size to 14 points. Finally, in A3, you change the font to Tahoma and the font size to 16 points.
For the second and third fonts, you also change the text color. In A2, you set the color to red, and in A3, you set the color to green.
When you run this code, your output will look like this:

Try changing the code to use other fonts or colors. If you want to get adventurous, you should try to make your text bold or italicized.
Now you’re ready to learn about text alignment.
Setting the Alignment
You can set alignment in OpenPyXL by using openpyxl.styles.Alignment. You use this class to rotate the text, set text wrapping, and for indentation.
Here are the defaults that the Alignment class uses:
- horizontal=’general’
- vertical=’bottom’
- text_rotation=0
- wrap_text=False
- shrink_to_fit=False
- indent=0
It’s time for you to get some practice in. Open up your Python editor and create a new file named alignment.py. Then add this code to it:
# alignment.py
from openpyxl import Workbook
from openpyxl.styles import Alignment
def center_text(path, horizontal="center", vertical="center"):
workbook = Workbook()
sheet = workbook.active
sheet["A1"] = "Hello"
sheet["A1"].alignment = Alignment(horizontal=horizontal,
vertical=vertical)
sheet["A2"] = "from"
sheet["A3"] = "OpenPyXL"
sheet["A3"].alignment = Alignment(text_rotation=90)
workbook.save(path)
if __name__ == "__main__":
center_text("alignment.xlsx")
You will center the string both horizontally and vertically in A1 when you run this code. Then you use the defaults for A2. Finally, for A3, you rotate the text 90 degrees.
Try running this code, and you will see something like the following:

That looks nice! It would be best if you took the time to try out different text_rotation values. Then try changing the horizontal and vertical parameters with different values. Pretty soon, you will be able to align your text like a pro!
Now you’re ready to learn about adding borders to your cells!
Adding a Border
OpenPyXL gives you the ability to style the borders on your cell. You can specify a different border style for each of the four sides of a cell.
You can use any of the following border styles:
- ‘dashDot’
- ‘dashDotDot’
- ‘dashed’
- ‘dotted’
- ‘double’
- ‘hair’
- ‘medium’
- ‘mediumDashDot’
- ‘mediumDashDotDot’,
- ‘mediumDashed’
- ‘slantDashDot’
- ‘thick’
- ‘thin’
Open your Python editor and create a new file named border.py. Then enter the following code in your file:
# border.py
from openpyxl import Workbook
from openpyxl.styles import Border, Side
def border(path):
pink = "00FF00FF"
green = "00008000"
thin = Side(border_style="thin", color=pink)
double = Side(border_style="double", color=green)
workbook = Workbook()
sheet = workbook.active
sheet["A1"] = "Hello"
sheet["A1"].border = Border(top=double, left=thin, right=thin, bottom=double)
sheet["A2"] = "from"
sheet["A3"] = "OpenPyXL"
sheet["A3"].border = Border(top=thin, left=double, right=double, bottom=thin)
workbook.save(path)
if __name__ == "__main__":
border("border.xlsx")
This code will add a border to cell A1 and A3. The top and bottom of A1 use a “double” border style and are green, while the cell sides are using a “thin” border style and are colored pink.
Cell A3 uses the same borders but swaps them so that the sides are now green and the top and bottom are pink.
You get this effect by creating Side objects in the border_style and the color to be used. Then you pass those Side objects to a Border class, which allows you to set each of the four sides of a cell individually. To apply the Border to a cell, you must set the cell’s border attribute.
When you run this code, you will see the following result:

This image is zoomed in a lot so that you can easily see the borders of the cells. It would be best if you tried modifying this code with some of the other border styles mentioned at the beginning of this section so that you can see what else you can do.
Changing the Cell Background Color
You can highlight a cell or a range of cells by changing its background color. Highlighting a cell is more eye-catching than changing the text’s font or color in most cases. OpenPyXL gives you a class called PatternFill that you can use to change a cell’s background color.
The PatternFill class takes in the following arguments (defaults included below):
- patternType=None
- fgColor=Color()
- bgColor=Color()
- fill_type=None
- start_color=None
- end_color=None
There are several different fill types you can use. Here is a list of currently supported fill types:
- ‘none’
- ‘solid’
- ‘darkDown’
- ‘darkGray’
- ‘darkGrid’
- ‘darkHorizontal’
- ‘darkTrellis’
- ‘darkUp’
- ‘darkVertical’
- ‘gray0625’
- ‘gray125’
- ‘lightDown’
- ‘lightGray’
- ‘lightGrid’
- ‘lightHorizontal’
- ‘lightTrellis’
- ‘lightUp’
- ‘lightVertical’
- ‘mediumGray’
Now you have enough information to try setting the background color of a cell using OpenPyXL. Open up a new file in your Python editor and name it background_colors.py. Then add this code to your new file:
# background_colors.py
from openpyxl import Workbook
from openpyxl.styles import PatternFill
def background_colors(path):
workbook = Workbook()
sheet = workbook.active
yellow = "00FFFF00"
for rows in sheet.iter_rows(min_row=1, max_row=10, min_col=1, max_col=12):
for cell in rows:
if cell.row % 2:
cell.fill = PatternFill(start_color=yellow, end_color=yellow,
fill_type = "solid")
workbook.save(path)
if __name__ == "__main__":
background_colors("bg.xlsx")
This example will iterate over nine rows and 12 columns. It will set every cell’s background color to yellow if that cell is in an odd-numbered row. The cells with their background color changes will be from column A through column L.
When you want to set the cell’s background color, you set the cell’s fill attribute to an instance of PatternFill. In this example, you specify a start_color and an end_color. You also set the fill_type to “solid”. OpenPyXL also supports using a GradientFill for the background.
Try running this code. After it runs, you will have a new Excel document that looks like this:

Here are some ideas that you can try out with this code:
- Change the number of rows or columns that are affected
- Change the color that you are changing to
- Update the code to color the even rows with a different color
- Try out other fill types
Once you are done experimenting with background colors, you can learn about inserting images in your cells!
Inserting Images into Cells
OpenPyXL makes inserting an image into your Excel spreadsheets nice and straightforward. To make this magic happen, you use the Worksheet object’s add_image() method. This method takes in two arguments:
img– The path to the image file that you are insertinganchor– Provide a cell as a top-left anchor of the image (optional)
For this example, you will be using the Mouse vs. Python logo:
![]()
The GitHub repository for this book has the image for you to use.
Once you have the image downloaded, create a new Python file and name it insert_image.py. Then add the following:
# insert_image.py
from openpyxl import Workbook
from openpyxl.drawing.image import Image
def insert_image(path, image_path):
workbook = Workbook()
sheet = workbook.active
img = Image("logo.png")
sheet.add_image(img, "B1")
workbook.save(path)
if __name__ == "__main__":
insert_image("logo.xlsx", "logo.png")
Here you pass in the path to the image that you wish to insert. To insert the image, you call add_image(). In this example, you are hard-coding to use cell B1 as the anchor cell. Then you save your Excel spreadsheet.
If you open up your spreadsheet, you will see that it looks like this:
![]()
You probably won’t need to insert an image into an Excel spreadsheet all that often, but it’s an excellent skill to have.
Styling Merged Cells
Merged cells are cells where you have two or more adjacent cells merged into one. If you want to set the value of a merged cell with OpenPyXL, you must use the top left-most cell of the merged cells.
You also must use this particular cell to set the style for the merged cell as a whole. You can use all the styles and font settings you used on an individual cell with the merged cell. However, you must apply the style to the top-left cell for it to apply to the entire merged cell.
You will understand how this works if you see some code. Go ahead and create a new file named style_merged_cell.py. Now enter this code in your file:
# style_merged_cell.py
from openpyxl import Workbook
from openpyxl.styles import Font, Border, Side, GradientFill, Alignment
def merge_style(path):
workbook = Workbook()
sheet = workbook.active
sheet.merge_cells("A2:G4")
top_left_cell = sheet["A2"]
light_purple = "00CC99FF"
green = "00008000"
thin = Side(border_style="thin", color=light_purple)
double = Side(border_style="double", color=green)
top_left_cell.value = "Hello from PyOpenXL"
top_left_cell.border = Border(top=double, left=thin, right=thin,
bottom=double)
top_left_cell.fill = GradientFill(stop=("000000", "FFFFFF"))
top_left_cell.font = Font(b=True, color="FF0000", size=16)
top_left_cell.alignment = Alignment(horizontal="center",
vertical="center")
workbook.save(path)
if __name__ == "__main__":
merge_style("merged_style.xlsx")
Here you create a merged cell that starts at A2 (the top-left cell) through G4. Then you set the cell’s value, border, fill, font and alignment.
When you run this code, your new spreadsheet will look like this:

Doesn’t that look nice? You should take some time and try out some different styles on your merged cell. Maybe come up with a better gradient than the gray one used here, for example.
Now you’re ready to learn about OpenPyXL’s built-in styles!
Using a Built-in Style
OpenPyXL comes with multiple built-in styles that you can use as well. Rather than reproducing the entire list of built-in styles in this book, you should go to the official documentation as it will be the most up-to-date source for the style names.
However, it is worth noting some of the styles. For example, here are the number format styles you can use:
- ‘Comma’
- ‘Comma [0]’
- ‘Currency’
- ‘Currency [0]’
- ‘Percent’
You can also apply text styles. Here is a listing of those styles:
- ‘Title’
- ‘Headline 1’
- ‘Headline 2’
- ‘Headline 3’
- ‘Headline 4’
- ‘Hyperlink’
- ‘Followed Hyperlink’
- ‘Linked Cell’
OpenPyXL has several other built-in style groups. You should check out the documentation to learn about all the different styles that are supported.
Now that you know about some of the built-in styles you can use, it’s time to write some code! Create a new file and name it builtin_styls.py. Then enter the following code:
# builtin_styles.py
from openpyxl import Workbook
def builtin_styles(path):
workbook = Workbook()
sheet = workbook.active
sheet["A1"].value = "Hello"
sheet["A1"].style = "Title"
sheet["A2"].value = "from"
sheet["A2"].style = "Headline 1"
sheet["A3"].value = "OpenPyXL"
sheet["A3"].style = "Headline 2"
workbook.save(path)
if __name__ == "__main__":
builtin_styles("builtin_styles.xlsx")
Here you apply three different styles to three different cells. You use “Title”, “Headline 1” and “Headline 2”, specifically.
When you run this code, you will end up having a spreadsheet that looks like this:

As always, you should try out some of the other built-in styles. Trying them out is the only way to determine what they do and if they will work for you.
But wait! What if you wanted to create your style? That’s what you will cover in the next section!
Creating a Custom Named Style
You can create custom styles of your design using OpenPyXL as well. To create your style, you must use the NamedStyle class.
The NamedStyle class takes the following arguments (defaults are included too):
- name=”Normal”
- font=Font()
- fill=PatternFill()
- border=Border()
- alignment=Alignment()
- number_format=None
- protection=Protection()
- builtinId=None
- hidden=False
- xfId=None
You should always provide your own name to your NamedStyle to keep it unique. Go ahead and create a new file and call it named_style.py. Then add this code to it:
# named_style.py
from openpyxl import Workbook
from openpyxl.styles import Font, Border, Side, NamedStyle
def named_style(path):
workbook = Workbook()
sheet = workbook.active
red = "00FF0000"
font = Font(bold=True, size=22)
thick = Side(style="thick", color=red)
border = Border(left=thick, right=thick, top=thick, bottom=thick)
named_style = NamedStyle(name="highlight", font=font, border=border)
sheet["A1"].value = "Hello"
sheet["A1"].style = named_style
sheet["A2"].value = "from"
sheet["A3"].value = "OpenPyXL"
workbook.save(path)
if __name__ == "__main__":
named_style("named_style.xlsx")
Here you create a Font(), Side(), and Border() instance to pass to your NamedStyle(). Once you have your custom style created, you can apply it to a cell by setting the cell’s style attribute. Applying a custom style is done in the same way as you applied built-in styles!
You applied the custom style to the cell, A1.
When you run this code, you will get a spreadsheet that looks like this:

Now it’s your turn! Edit the code to use a Side style, which will change your border. Or create multiple Side instances so you can make each side of the cell unique. Play around with different fonts or add a custom background color!
Wrapping Up
You can do a lot of different things with cells using OpenPyXL. The information in this article gives you the ability to format your data in beautiful ways.
In this article, you learned about the following topics:
- Working with fonts
- Setting the alignment
- Adding a border
- Changing the cell background-color
- Inserting images into cells
- Styling merged cells
- Using a built-in style
- Creating a custom named style
You can take the information that you learned in this article to make beautiful spreadsheets. You can highlight exciting data by changing the cell’s background color or font. You can also change the cell’s format by using a built-in style. Go ahead and give it a try.
Experiment with the code in this article and see how powerful and valuable OpenPyXL is when working with cells.
Related Reading
- Reading Spreadsheets with OpenPyXL and Python
- Creating Spreadsheets with OpenPyXL and Python
- Automating Excel with Python (book)
Время прочтения: 5 мин.
Ответ приходит в виде openpyxl, библиотеки Python, которая позволяет вам читать файлы Excel и управлять ими. Помимо базовых задач, таких как поиск и изменение значений ячеек, вы также можете агрегировать диапазоны ячеек, добавлять стиль к своим шрифтам и даже строить графики, используя всего несколько строк кода.
Загрузка рабочей книги и листа
Сначала нужно установить библиотеку openpyxl. Чтобы загрузить рабочую книгу из существующего файла Excel, сначала нужно импортировать модуль load_workbook, затем создать экземпляр load_workbook(), указав путь к файлу Excel в качестве единственного аргумента. Также нужно будет указать лист, к которому необходимо получить доступ из рабочей книги. Выполнение команды печати в переменной sheet вернёт имя активного листа.
#импортируем модули
from openpyxl import Workbook, load_workbook
#создаем экземпляр с именем пути к файлу excel
wb = load_workbook("/users/user1/downloads/example.xlsx")
#выбираем активный лист
sheet = wb.active
print(sheet)
Доступ к значению ячейки Чтобы получить доступ к значению ячейки, нужно передать имя ячейки в квадратных скобках после имени листа, за которым следует метод value.
print(sheet["A1"].value)
print(sheet["A2"].value)
print(sheet["B3"].value)
Изменение значения ячейки Можно изменить значение ячейки, обратившись к значению, а затем указав новое значение с помощью оператора equal. Необходимо запустить метод save(), чтобы изменения вступили в силу. Не забывайте всегда закрывать файл в Excel перед внесением каких-либо изменений, чтобы Python не выдавал ошибку.
#изменяем значение ячейки
sheet["A2"] = "TestTest"
#сохраняем файл
wb.save("/users/user1/downloads/example1.xlsx")
Создание нового листа Создать новый лист так же просто, как использовать метод create_sheet() и передать имя листа. Затем можно использовать имена листов, чтобы вернуть список всех листов в рабочей книге.
#создаем новый лист
wb.create_sheet("New_sheet")
#возвращаем список листов
print(wb.sheetnames)
Создание нового файла
Можно создать пустую рабочую книгу, используя метод Workbook(). Чтобы добавить данные в первую строку, буду использовать метод append().
#создаем новую рабочую книгу
new_wb = Workbook()
#выбираем активный лист
ws = new_wb.active
#переименовываем активный лист
ws.title = "New_sheet2"
#добавляем данные в активный лист
ws.append(["1","2","3","4"])
#сохраняем
new_wb.save("/users/user1/downloads/example3.xlsx")
Каждый раз, когда я использую метод append(), он добавляет новую строку на лист.
#заполняем несколько строк
ws.append(["5","6","7","8"])
ws.append(["9","10","11","12"])
ws.append(["13"])
# сохраняем
new_wb.save("/users/user1/downloads/example3.xlsx")
Вставка и удаление строк
Можно вставить новую строку в лист, используя метод insert_rows(), а затем указав номер строки, по которой нужно выполнить вставку.
#вставляем новую строку
ws.insert_rows(1)
#сохраняем
new_wb.save("/users/user1/downloads/example3.xlsx")
Таким же образом можно удалять строки, используя метод delete_rows() и указав позицию строки.
#удаляем строку
ws.delete_rows(1)
#сохраняем
new_wb.save("/users/user1/downloads/example3.xlsx")
Объединение ячеек и разъединение ячеек
Объединить ячейки так же просто, как использовать метод merge_cells() и указать диапазон.
#объединяем ячейки
ws.merge_cells("A1:A2")
#сохраняем
new_wb.save("/users/user1/downloads/example3.xlsx")
Можно отключить их с помощью метода unmerge_cells().
#разъединяем ячейки
ws.unmerge_cells("A1:A2")
#сохраняем
new_wb.save("/users/user1/downloads/example3.xlsx")
Вставка и удаление столбцов
Можно вставлять столбцы в любую позицию, указав номер в методе insert_cols().
#вставляем столбец
ws.insert_cols(2)
#сохраняем
new_wb.save("/users/user1/downloads/example3.xlsx")
Метод delete_cols() удалит указанные столбцы.
#удаляем столбцы
ws.delete_cols(1,2)
#сохраняем
new_wb.save("/users/user1/downloads/example3.xlsx")
Копирование и перемещение значений ячеек
Можно скопировать значения в любом диапазоне ячеек и переместить их в новую позицию с помощью метода move_range(). Он принимает три аргумента: диапазон перемещаемых данных, затем строки, которые могут быть положительным (количество строк вниз) или отрицательным (количество строк вверх) целым числом. Последний аргумент — cols, который также является либо положительным (количество столбцов справа), либо отрицательным (количество столбцов слева) целым числом. Перемещу диапазон A1:B1 на четыре строки вниз и на один столбец вправо.
#диапазон перемещения
ws.move_range("A1:B1",rows=4,cols=1)
#сохраняем
new_wb.save("/users/user1/downloads/example3.xlsx")
А теперь некоторые функции разберу на примере.
Кейс – делаю расчет в Excel по формуле
Многие сталкивались с ситуацией, когда было множество готовых excel—файлов и в них необходимо провести одинаковую операцию. Сейчас рассмотрю пример, когда нужно применить одинаковую формулу во множестве файлов. Может быть 5,10,100 файлов по которым нужно рассчитать, например, сумму значений в двух столбцах. С помощью python и библиотеки openpyxl можно избавиться от ручного применения формул автоматизировав этот процесс. Ниже представлен код, который по очереди к каждому excel-файлу из папки применяет формулу и записывает новый excel-файл с результатом расчёта по формуле.
import openpyxl
import os
path = r'C:UsersUser1' # Задаем путь к папке с excel-файлами, в которых будем рассчитывать формулу
files = [i for i in os.listdir(path) if 'xlsx' in i] # В этой папке выбираем названия только excel-файлов и создаем из них список
for i in files: # Идем по каждому excel-файлу
x = openpyxl.open(i) # Открываем этот файл
sheet = x.active # Выбираем лист для работы
cell = sheet.cell(row= sheet.max_row+1, column = 2) # Создаем ячейку с координатами, где показываем результаты расчета
cell.value = "=СУММ(A2:B{})".format(sheet.max_row) # Пишем формулу в ячейку
cell.font = cell.font.copy(bold = True) # Изменяем стиль шрифта
x.save('formulas_{}.xlsx'.format(i.split('.')[0])) # сохраняем результат в файл
В моём примере расположения столбцов для расчёта в каждом файле одинаковое (столбец A и столбец B), но количество строк может быть разным, соответственно результат по формуле тоже будет располагаться в разной строке под данными. Чтобы не высчитывать количество строк в каждом файле, применяю метод sheet.max_row, когда задаю ячейку для записи результата +1 строка в переменную cell, чтобы результат на следующей строке, под данными.

Надеюсь, читатели, которые только погружаются в Python, смогли получить общее представление о том, как работать с файлами Excel на Python. С openpyxl вы cможете сделать форматирование, создавать сводные таблицы и диаграммы, делать фильтрацию и сортировку, агрегировать значения ячеек, изменять шрифт, перемещение данные на новый лист. С этими возможностями можно ознакомиться в официальной документации.
Узнайте, как читать и импортировать файлы Excel в Python, как записывать данные в эти таблицы и какие библиотеки лучше всего подходят для этого.
Известный вам инструмент для организации, анализа и хранения ваших данных в таблицах — Excel — применяется и в data science. В какой-то момент вам придется иметь дело с этими таблицами, но работать именно с ними вы будете не всегда. Вот почему разработчики Python реализовали способы чтения, записи и управления не только этими файлами, но и многими другими типами файлов.
Из этого учебника узнаете, как можете работать с Excel и Python. Внутри найдете обзор библиотек, которые вы можете использовать для загрузки и записи этих таблиц в файлы с помощью Python. Вы узнаете, как работать с такими библиотеками, как pandas, openpyxl, xlrd, xlutils и pyexcel.
Данные как ваша отправная точка
Когда вы начинаете проект по data science, вам придется работать с данными, которые вы собрали по всему интернету, и с наборами данных, которые вы загрузили из других мест — Kaggle, Quandl и тд
Но чаще всего вы также найдете данные в Google или в репозиториях, которые используются другими пользователями. Эти данные могут быть в файле Excel или сохранены в файл с расширением .csv … Возможности могут иногда казаться бесконечными, но когда у вас есть данные, в первую очередь вы должны убедиться, что они качественные.
В случае с электронной таблицей вы можете не только проверить, могут ли эти данные ответить на вопрос исследования, который вы имеете в виду, но также и можете ли вы доверять данным, которые хранятся в электронной таблице.
Проверяем качество таблицы
- Представляет ли электронная таблица статические данные?
- Смешивает ли она данные, расчеты и отчетность?
- Являются ли данные в вашей электронной таблице полными и последовательными?
- Имеет ли ваша таблица систематизированную структуру рабочего листа?
- Проверяли ли вы действительные формулы в электронной таблице?
Этот список вопросов поможет убедиться, что ваша таблица не грешит против лучших практик, принятых в отрасли. Конечно, этот список не исчерпывающий, но позволит провести базовую проверку таблицы.
Лучшие практики для данных электронных таблиц
Прежде чем приступить к чтению вашей электронной таблицы на Python, вы также должны подумать о том, чтобы настроить свой файл в соответствии с некоторыми основными принципами, такими как:
- Первая строка таблицы обычно зарезервирована для заголовка, а первый столбец используется для идентификации единицы выборки;
- Избегайте имен, значений или полей с пробелами. В противном случае каждое слово будет интерпретироваться как отдельная переменная, что приведет к ошибкам, связанным с количеством элементов на строку в вашем наборе данных. По возможности, используйте:
- подчеркивания,
- тире,
- горбатый регистр, где первая буква каждого слова пишется с большой буквы
- объединяющие слова
- Короткие имена предпочтительнее длинных имен;
- старайтесь не использовать имена, которые содержат символы ?, $,%, ^, &, *, (,), -, #,? ,,, <,>, /, |, , [,], {, и };
- Удалите все комментарии, которые вы сделали в вашем файле, чтобы избежать добавления в ваш файл лишних столбцов или NA;
- Убедитесь, что все пропущенные значения в вашем наборе данных обозначены как NA.
Затем, после того, как вы внесли необходимые изменения или тщательно изучили свои данные, убедитесь, что вы сохранили внесенные изменения. Сделав это, вы можете вернуться к данным позже, чтобы отредактировать их, добавить дополнительные данные или изменить их, сохранив формулы, которые вы, возможно, использовали для расчета данных и т.д.
Если вы работаете с Microsoft Excel, вы можете сохранить файл в разных форматах: помимо расширения по умолчанию .xls или .xlsx, вы можете перейти на вкладку «Файл», нажать «Сохранить как» и выбрать одно из расширений, которые указаны в качестве параметров «Сохранить как тип». Наиболее часто используемые расширения для сохранения наборов данных в data science — это .csv и .txt (в виде текстового файла с разделителями табуляции). В зависимости от выбранного варианта сохранения поля вашего набора данных разделяются вкладками или запятыми, которые образуют символы-разделители полей вашего набора данных.
Теперь, когда вы проверили и сохранили ваши данные, вы можете начать с подготовки вашего рабочего окружения.
Готовим рабочее окружение
Как убедиться, что вы все делаете хорошо? Проверить рабочее окружение!
Когда вы работаете в терминале, вы можете сначала перейти в каталог, в котором находится ваш файл, а затем запустить Python. Убедитесь, что файл лежит именно в том каталоге, к которому вы обратились.
Возможно, вы уже начали сеанс Python и у вас нет подсказок о каталоге, в котором вы работаете. Тогда можно выполнить следующие команды:
# Import `os`
import os
# Retrieve current working directory (`cwd`)
cwd = os.getcwd()
cwd
# Change directory
os.chdir("/path/to/your/folder")
# List all files and directories in current directory
os.listdir('.')Круто, да?
Вы увидите, что эти команды очень важны не только для загрузки ваших данных, но и для дальнейшего анализа. А пока давайте продолжим: вы прошли все проверки, вы сохранили свои данные и подготовили рабочее окружение.
Можете ли вы начать с чтения данных в Python?
Установите библиотеки для чтения и записи файлов Excel
Даже если вы еще не знаете, какие библиотеки вам понадобятся для импорта ваших данных, вы должны убедиться, что у вас есть все, что нужно для установки этих библиотек, когда придет время.
Подготовка к дополнительной рабочей области: pip
Вот почему вам нужно установить pip и setuptools. Если у вас установлен Python2 ⩾ 2.7.9 или Python3 ⩾ 3.4, то можно не беспокоиться — просто убедитесь, что вы обновились до последней версии.
Для этого выполните следующую команду в своем терминале:
# Для Linux/OS X
pip install -U pip setuptools
# Для Windows
python -m pip install -U pip setuptoolsЕсли вы еще не установили pip, запустите скрипт python get-pip.py, который вы можете найти здесь. Следуйте инструкциям по установке.
Установка Anaconda
Другой вариант для работы в data science — установить дистрибутив Anaconda Python. Сделав это, вы получите простой и быстрый способ начать заниматься data science, потому что вам не нужно беспокоиться об установке отдельных библиотек, необходимых для работы.
Это особенно удобно, если вы новичок, но даже для более опытных разработчиков это способ быстро протестировать некоторые вещи без необходимости устанавливать каждую библиотеку отдельно.
Anaconda включает в себя 100 самых популярных библиотек Python, R и Scala для науки о данных и несколько сред разработки с открытым исходным кодом, таких как Jupyter и Spyder.
Установить Anaconda можно здесь. Следуйте инструкциям по установке, и вы готовы начать!
Загрузить файлы Excel в виде фреймов Pandas
Все, среда настроена, вы готовы начать импорт ваших файлов.
Один из способов, который вы часто используете для импорта ваших файлов для обработки данных, — с помощью библиотеки Pandas. Она основана на NumPy и предоставляет простые в использовании структуры данных и инструменты анализа данных Python.
Эта мощная и гибкая библиотека очень часто используется дата-инженерами для передачи своих данных в структуры данных, очень выразительных для их анализа.
Если у вас уже есть Pandas, доступные через Anaconda, вы можете просто загрузить свои файлы в Pandas DataFrames с помощью pd.Excelfile():
# импорт библиотеки pandas
import pandas as pd
# Загружаем ваш файл в переменную `file` / вместо 'example' укажите название свого файла из текущей директории
file = 'example.xlsx'
# Загружаем spreadsheet в объект pandas
xl = pd.ExcelFile(file)
# Печатаем название листов в данном файле
print(xl.sheet_names)
# Загрузить лист в DataFrame по его имени: df1
df1 = xl.parse('Sheet1')Если вы не установили Anaconda, просто выполните pip install pandas, чтобы установить библиотеку Pandas в вашей среде, а затем выполните команды, которые включены в фрагмент кода выше.
Проще простого, да?
Для чтения в файлах .csv у вас есть аналогичная функция для загрузки данных в DataFrame: read_csv(). Вот пример того, как вы можете использовать эту функцию:
# Импорт библиотеки pandas
import pandas as pd
# Загрузить csv файл
df = pd.read_csv("example.csv") Разделитель, который будет учитывать эта функция, по умолчанию является запятой, но вы можете указать альтернативный разделитель, если хотите. Перейдите к документации, чтобы узнать, какие другие аргументы вы можете указать для успешного импорта!
Обратите внимание, что есть также функции read_table() и read_fwf() для чтения файлов и таблиц с фиксированной шириной в формате DataFrames с общим разделителем. Для первой функции разделителем по умолчанию является вкладка, но вы можете снова переопределить это, а также указать альтернативный символ-разделитель. Более того, есть и другие функции, которые вы можете использовать для получения данных в DataFrames: вы можете найти их здесь.
Как записать Pandas DataFrames в файлы Excel
Допустим, что после анализа данных вы хотите записать данные обратно в новый файл. Есть также способ записать ваши Pandas DataFrames обратно в файлы с помощью функции to_excel().
Но, прежде чем использовать эту функцию, убедитесь, что у вас установлен XlsxWriter, если вы хотите записать свои данные в несколько листов в файле .xlsx:
# Установим `XlsxWriter`
pip install XlsxWriter
# Указать writer библиотеки
writer = pd.ExcelWriter('example.xlsx', engine='xlsxwriter')
# Записать ваш DataFrame в файл
yourData.to_excel(writer, 'Sheet1')
# Сохраним результат
writer.save()Обратите внимание, что в приведенном выше фрагменте кода вы используете объект ExcelWriter для вывода DataFrame.
Иными словами, вы передаете переменную Writer в функцию to_excel() и также указываете имя листа. Таким образом, вы добавляете лист с данными в существующую рабочую книгу: вы можете использовать ExcelWriter для сохранения нескольких (немного) разных DataFrames в одной рабочей книге.
Все это означает, что если вы просто хотите сохранить один DataFrame в файл, вы также можете обойтись без установки пакета XlsxWriter. Затем вы просто не указываете аргумент движка, который вы передаете в функцию pd.ExcelWriter(). Остальные шаги остаются прежними.
Аналогично функциям, которые вы использовали для чтения в файлах .csv, у вас также есть функция to_csv() для записи результатов обратно в файл, разделенный запятыми. Он снова работает так же, как когда вы использовали его для чтения в файле:
# Запишите DataFrame в csv
df.to_csv("example.csv")Если вы хотите иметь файл, разделенный табуляцией, вы также можете передать t аргументу sep. Обратите внимание, что есть другие функции, которые вы можете использовать для вывода ваших файлов. Вы можете найти их все здесь.
Пакеты для разбора файлов Excel и обратной записи с помощью Python
Помимо библиотеки Pandas, который вы будете использовать очень часто для загрузки своих данных, вы также можете использовать другие библиотеки для получения ваших данных в Python. Наш обзор основан на этой странице со списком доступных библиотек, которые вы можете использовать для работы с файлами Excel в Python.
Далее вы увидите, как использовать эти библиотеки с помощью некоторых реальных, но упрощенных примеров.
Использование виртуальных сред
Общий совет для установки — делать это в Python virtualenv без системных пакетов. Вы можете использовать virtualenv для создания изолированных сред Python: он создает папку, содержащую все необходимые исполняемые файлы для использования пакетов, которые потребуются проекту Python.
Чтобы начать работать с virtualenv, вам сначала нужно установить его. Затем перейдите в каталог, в который вы хотите поместить свой проект. Создайте virtualenv в этой папке и загрузите в определенную версию Python, если вам это нужно. Затем вы активируете виртуальную среду. После этого вы можете начать загрузку в другие библиотеки, начать работать с ними и т. д.
Совет: не забудьте деактивировать среду, когда закончите!
# Install virtualenv
$ pip install virtualenv
# Go to the folder of your project
$ cd my_folder
# Create a virtual environment `venv`
$ virtualenv venv
# Indicate the Python interpreter to use for `venv`
$ virtualenv -p /usr/bin/python2.7 venv
# Activate `venv`
$ source venv/bin/activate
# Deactivate `venv`
$ deactivateОбратите внимание, что виртуальная среда может показаться немного проблемной на первый взгляд, когда вы только начинаете работать с данными с Python. И, особенно если у вас есть только один проект, вы можете не понять, зачем вам вообще нужна виртуальная среда.
С ней будет гораздо легче, когда у вас одновременно запущено несколько проектов, и вы не хотите, чтобы они использовали одну и ту же установку Python. Или когда ваши проекты имеют противоречащие друг другу требования, виртуальная среда пригодится!
Теперь вы можете, наконец, начать установку и импорт библиотек, о которых вы читали, и загрузить их в таблицу.
Как читать и записывать файлы Excel с openpyxl
Этот пакет обычно рекомендуется, если вы хотите читать и записывать файлы .xlsx, xlsm, xltx и xltm.
Установите openpyxl с помощью pip: вы видели, как это сделать в предыдущем разделе.
Общий совет для установки этой библиотеки — делать это в виртуальной среде Python без системных библиотек. Вы можете использовать виртуальную среду для создания изолированных сред Python: она создает папку, которая содержит все необходимые исполняемые файлы для использования библиотек, которые потребуются проекту Python.
Перейдите в каталог, в котором находится ваш проект, и повторно активируйте виртуальную среду venv. Затем продолжите установку openpyxl с pip, чтобы убедиться, что вы можете читать и записывать файлы с ним:
# Активируйте virtualenv
$ source activate venv
# Установим `openpyxl` в `venv`
$ pip install openpyxlТеперь, когда вы установили openpyxl, вы можете загружать данные. Но что это за данные?
Доспутим Excel с данными, которые вы пытаетесь загрузить в Python, содержит следующие листы:
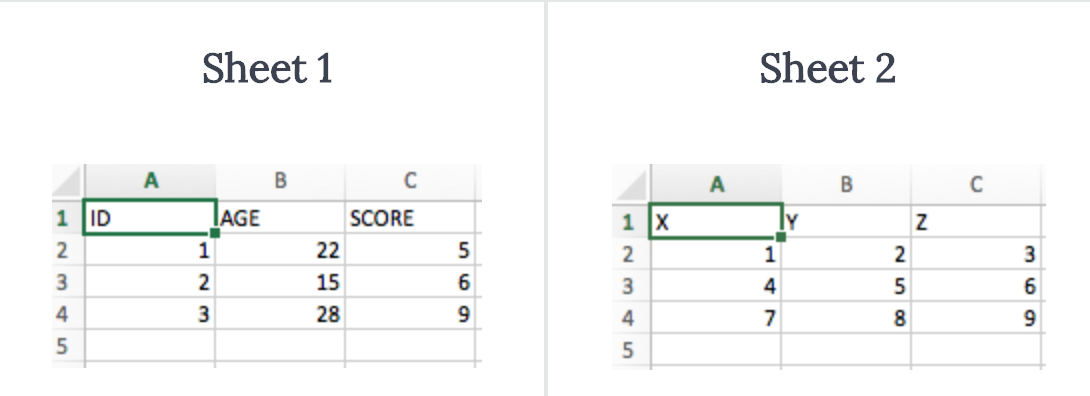
Функция load_workbook() принимает имя файла в качестве аргумента и возвращает объект рабочей книги, который представляет файл. Вы можете проверить это, запустив type (wb). Убедитесь, что вы находитесь в том каталоге, где находится ваша таблица, иначе вы получите error при импорте.
# Import `load_workbook` module from `openpyxl`
from openpyxl import load_workbook
# Load in the workbook
wb = load_workbook('./test.xlsx')
# Get sheet names
print(wb.get_sheet_names())Помните, что вы можете изменить рабочий каталог с помощью os.chdir().
Вы видите, что фрагмент кода выше возвращает имена листов книги, загруженной в Python.Можете использовать эту информацию, чтобы также получить отдельные листы рабочей книги.
Вы также можете проверить, какой лист в настоящее время активен с wb.active. Как видно из кода ниже, вы можете использовать его для загрузки другого листа из вашей книги:
# Get a sheet by name
sheet = wb.get_sheet_by_name('Sheet3')
# Print the sheet title
sheet.title
# Get currently active sheet
anotherSheet = wb.active
# Check `anotherSheet`
anotherSheetНа первый взгляд, с этими объектами рабочего листа вы не сможете многое сделать.. Однако вы можете извлечь значения из определенных ячеек на листе вашей книги, используя квадратные скобки [], в которые вы передаете точную ячейку, из которой вы хотите получить значение.
Обратите внимание, что это похоже на выбор, получение и индексирование массивов NumPy и Pandas DataFrames, но это не все, что вам нужно сделать, чтобы получить значение. Вам нужно добавить атрибут value:
# Retrieve the value of a certain cell
sheet['A1'].value
# Select element 'B2' of your sheet
c = sheet['B2']
# Retrieve the row number of your element
c.row
# Retrieve the column letter of your element
c.column
# Retrieve the coordinates of the cell
c.coordinateКак вы можете видеть, помимо значения, есть и другие атрибуты, которые вы можете использовать для проверки вашей ячейки, а именно: row, column и coordinate.
Атрибут row вернет 2;
Добавление атрибута column к c даст вам ‘B’
coordinate вернет ‘B2’.
Вы также можете получить значения ячеек с помощью функции cell(). Передайте row и column, добавьте к этим аргументам значения, соответствующие значениям ячейки, которую вы хотите получить, и, конечно же, не забудьте добавить атрибут value:
# Retrieve cell value
sheet.cell(row=1, column=2).value
# Print out values in column 2
for i in range(1, 4):
print(i, sheet.cell(row=i, column=2).value)Обратите внимание, что если вы не укажете атрибут value, вы получите <Cell Sheet3.B1>, который ничего не говорит о значении, которое содержится в этой конкретной ячейке.
Вы видите, что вы используете цикл for с помощью функции range(), чтобы помочь вам распечатать значения строк, имеющих значения в столбце 2. Если эти конкретные ячейки пусты, вы просто вернете None. Если вы хотите узнать больше о циклах for, пройдите наш курс Intermediate Python для Data Science.
Есть специальные функции, которые вы можете вызывать для получения некоторых других значений, например, get_column_letter() и column_index_from_string.
Две функции указывают примерно то, что вы можете получить, используя их, но лучше сделать их четче: хотя вы можете извлечь букву столбца с предшествующего, вы можете сделать обратное или получить адрес столбца, когда вы задаёте букву последнему. Вы можете увидеть, как это работает ниже:
# Импорт необходимых модулей из `openpyxl.utils`
from openpyxl.utils import get_column_letter, column_index_from_string
# Вывод 'A'
get_column_letter(1)
# Return '1'
column_index_from_string('A')Вы уже получили значения для строк, которые имеют значения в определенном столбце, но что вам нужно сделать, если вы хотите распечатать строки вашего файла, не сосредотачиваясь только на одном столбце? Использовать другой цикл, конечно!
Например, вы говорите, что хотите сфокусироваться на области между «А1» и «С3», где первая указывает на левый верхний угол, а вторая — на правый нижний угол области, на которой вы хотите сфокусироваться. ,
Эта область будет так называемым cellObj, который вы видите в первой строке кода ниже. Затем вы говорите, что для каждой ячейки, которая находится в этой области, вы печатаете координату и значение, которое содержится в этой ячейке. После конца каждой строки вы печатаете сообщение, которое указывает, что строка этой области cellObj напечатана.
# Напечатать строчку за строчкой
for cellObj in sheet['A1':'C3']:
for cell in cellObj:
print(cells.coordinate, cells.value)
print('--- END ---')Еще раз обратите внимание, что выбор области очень похож на выбор, получение и индексирование списка и элементов массива NumPy, где вы также используете [] и : для указания области, значения которой вы хотите получить. Кроме того, вышеприведенный цикл также хорошо использует атрибуты ячейки!
Чтобы сделать вышеприведенное объяснение и код наглядным, вы можете проверить результат, который вы получите после завершения цикла:
('A1', u'M')
('B1', u'N')
('C1', u'O')
--- END ---
('A2', 10L)
('B2', 11L)
('C2', 12L)
--- END ---
('A3', 14L)
('B3', 15L)
('C3', 16L)
--- END ---Наконец, есть некоторые атрибуты, которые вы можете использовать для проверки результата вашего импорта, а именно max_row и max_column. Эти атрибуты, конечно, и так — общие способы проверки правильности загрузки данных, но они все равно полезны.
# Вывести максимальное количество строк
sheet.max_row
# Вывести максимальное количество колонок
sheet.max_columnНаверное, вы думаете, что такой способ работы с этими файлами сложноват, особенно если вы еще хотите манипулировать данными.
Должно быть что-то попроще, верно? Так и есть!
openpyxl поддерживает Pandas DataFrames! Вы можете использовать функцию DataFrame() из библиотеки Pandas, чтобы поместить значения листа в DataFrame:
# Import `pandas`
import pandas as pd
# конвертировать Лист в DataFrame
df = pd.DataFrame(sheet.values)Если вы хотите указать заголовки и индексы, вам нужно добавить немного больше кода:
# Put the sheet values in `data`
data = sheet.values
# Indicate the columns in the sheet values
cols = next(data)[1:]
# Convert your data to a list
data = list(data)
# Read in the data at index 0 for the indices
idx = [r[0] for r in data]
# Slice the data at index 1
data = (islice(r, 1, None) for r in data)
# Make your DataFrame
df = pd.DataFrame(data, index=idx, columns=cols)Затем вы можете начать манипулировать данными со всеми функциями, которые предлагает библиотека Pandas. Но помните, что вы находитесь в виртуальной среде, поэтому, если библиотека еще не представлена, вам нужно будет установить ее снова через pip.
Чтобы записать ваши Pandas DataFrames обратно в файл Excel, вы можете легко использовать функцию dataframe_to_rows() из модуля utils:
# Import `dataframe_to_rows`
from openpyxl.utils.dataframe import dataframe_to_rows
# Initialize a workbook
wb = Workbook()
# Get the worksheet in the active workbook
ws = wb.active
# Append the rows of the DataFrame to your worksheet
for r in dataframe_to_rows(df, index=True, header=True):
ws.append(r)Но это точно не все! Библиотека openpyxl предлагает вам высокую гибкость при записи ваших данных обратно в файлы Excel, изменении стилей ячеек или использовании режима write-only. Эту библиотеку обязательно нужно знать, когда вы часто работаете с электронными таблицами ,
Совет: читайте больше о том, как вы можете изменить стили ячеек, перейти в режим write-only или как библиотека работает с NumPy здесь.
Теперь давайте также рассмотрим некоторые другие библиотеки, которые вы можете использовать для получения данных вашей электронной таблицы в Python.
Прежде чем закрыть этот раздел, не забудьте отключить виртуальную среду, когда закончите!
Чтение и форматирование Excel-файлов: xlrd
Эта библиотека идеально подходит для чтения и форматирования данных из Excel с расширением xls или xlsx.
# Import `xlrd`
import xlrd
# Open a workbook
workbook = xlrd.open_workbook('example.xls')
# Loads only current sheets to memory
workbook = xlrd.open_workbook('example.xls', on_demand = True)Когда вам не нужны данные из всей Excel-книги, вы можете использовать функции sheet_by_name() или sheet_by_index() для получения листов, которые вы хотите получить в своём анализе
# Load a specific sheet by name
worksheet = workbook.sheet_by_name('Sheet1')
# Load a specific sheet by index
worksheet = workbook.sheet_by_index(0)
# Retrieve the value from cell at indices (0,0)
sheet.cell(0, 0).valueТакже можно получить значение в определённых ячейках с вашего листа.
Перейдите к xlwt и xlutils, чтобы узнать больше о том, как они относятся к библиотеке xlrd.
Запись данных в Excel-файлы с xlwt
Если вы хотите создать таблицу со своими данными, вы можете использовать не только библиотеку XlsWriter, но и xlwt. xlwt идеально подходит для записи данных и форматирования информации в файлах с расширением .xls
Когда вы вручную создаёте файл:
# Import `xlwt`
import xlwt
# Initialize a workbook
book = xlwt.Workbook(encoding="utf-8")
# Add a sheet to the workbook
sheet1 = book.add_sheet("Python Sheet 1")
# Write to the sheet of the workbook
sheet1.write(0, 0, "This is the First Cell of the First Sheet")
# Save the workbook
book.save("spreadsheet.xls")Если вы хотите записать данные в файл, но не хотите делать все самостоятельно, вы всегда можете прибегнуть к циклу for, чтобы автоматизировать весь процесс. Составьте сценарий, в котором вы создаёте книгу и в которую добавляете лист. Укажите список со столбцами и один со значениями, которые будут заполнены на листе.
Далее у вас есть цикл for, который гарантирует, что все значения попадают в файл: вы говорите, что для каждого элемента в диапазоне от 0 до 4 (5 не включительно) вы собираетесь что-то делать. Вы будете заполнять значения построчно. Для этого вы указываете элемент строки, который появляется в каждом цикле. Далее у вас есть еще один цикл for, который будет проходить по столбцам вашего листа. Вы говорите, что для каждой строки на листе, вы будете смотреть на столбцы, которые идут с ним, и вы будете заполнять значение для каждого столбца в строке. Заполнив все столбцы строки значениями, вы перейдете к следующей строке, пока не останется строк.
# Initialize a workbook
book = xlwt.Workbook()
# Add a sheet to the workbook
sheet1 = book.add_sheet("Sheet1")
# The data
cols = ["A", "B", "C", "D", "E"]
txt = [0,1,2,3,4]
# Loop over the rows and columns and fill in the values
for num in range(5):
row = sheet1.row(num)
for index, col in enumerate(cols):
value = txt[index] + num
row.write(index, value)
# Save the result
book.save("test.xls")На скриншоте ниже представлен результат выполнения этого кода:
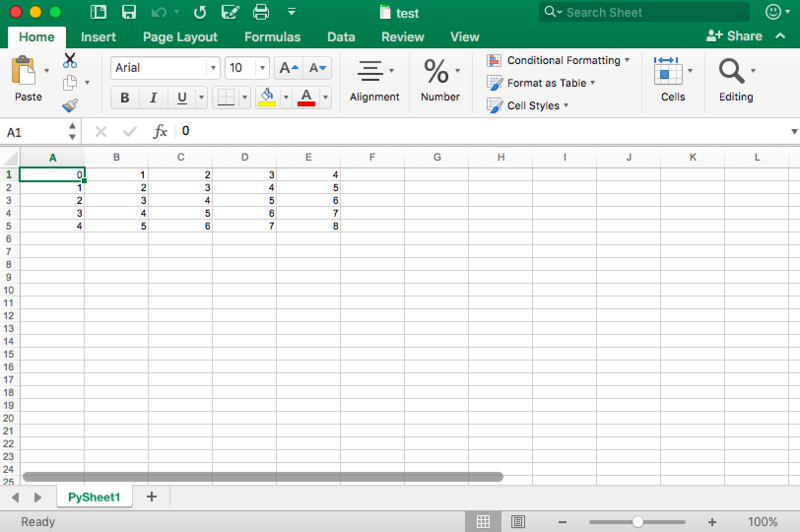
Теперь, когда вы увидели, как xlrd и xlwt работают друг с другом, пришло время взглянуть на библиотеку, которая тесно связана с этими двумя: xlutils.
Сборник утилит: xlutils
Эта библиотека — сборник утилит, для которого требуются и xlrd и xlwt, и которая может копировать, изменять и фильтровать существующие данные. О том, как пользоваться этими командами рассказано в разделе по openpyxl.
Вернитесь в раздел openpyxl, чтобы получить больше информации о том, как использовать этот пакет для получения данных в Python.
Использование pyexcel для чтения .xls или .xlsx файлов
Еще одна библиотека, которую можно использовать для чтения данных электронных таблиц в Python — это pyexcel; Python Wrapper, который предоставляет один API для чтения, записи и работы с данными в файлах .csv, .ods, .xls, .xlsx и .xlsm. Конечно, для этого урока вы просто сосредоточитесь на файлах .xls и .xls.
Чтобы получить ваши данные в массиве, вы можете использовать функцию get_array(), которая содержится в пакете pyexcel:
# Import `pyexcel`
import pyexcel
# Get an array from the data
my_array = pyexcel.get_array(file_name="test.xls")Вы также можете получить свои данные в упорядоченном словаре списков. Вы можете использовать функцию get_dict():
# Import `OrderedDict` module
from pyexcel._compact import OrderedDict
# Get your data in an ordered dictionary of lists
my_dict = pyexcel.get_dict(file_name="test.xls", name_columns_by_row=0)
# Get your data in a dictionary of 2D arrays
book_dict = pyexcel.get_book_dict(file_name="test.xls")Здесь видно, что если вы хотите получить словарь двумерных массивов или получить все листы рабочей книги в одном словаре, вы можете прибегнуть к get_book_dict().
Помните, что эти две структуры данных, которые были упомянуты выше, массивы и словари вашей таблицы, позволяют вам создавать DataFrames ваших данных с помощью pd.DataFrame(). Это облегчит обработку данных.
Кроме того, вы можете просто получить записи из таблицы с помощью pyexcel благодаря функции get_records(). Просто передайте аргумент file_name в функцию, и вы получите список словарей:
# Retrieve the records of the file
records = pyexcel.get_records(file_name="test.xls")Чтобы узнать, как управлять списками Python, ознакомьтесь с примерами из документации о списках Python.
Запись в файл с pyexcel
С помощью этой библиотеки можно не только загружать данные в массивы, вы также можете экспортировать свои массивы обратно в таблицу. Используйте функцию save_as() и передайте массив и имя файла назначения в аргумент dest_file_name:
# Get the data
data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
# Save the array to a file
pyexcel.save_as(array=data, dest_file_name="array_data.xls")Обратите внимание, что если вы хотите указать разделитель, вы можете добавить аргумент dest_delimiter и передать символ, который вы хотите использовать в качестве разделителя между «».
Однако если у вас есть словарь, вам нужно использовать функцию save_book_as(). Передайте двумерный словарь в bookdict и укажите имя файла:
# The data
2d_array_dictionary = {'Sheet 1': [
['ID', 'AGE', 'SCORE']
[1, 22, 5],
[2, 15, 6],
[3, 28, 9]
],
'Sheet 2': [
['X', 'Y', 'Z'],
[1, 2, 3],
[4, 5, 6]
[7, 8, 9]
],
'Sheet 3': [
['M', 'N', 'O', 'P'],
[10, 11, 12, 13],
[14, 15, 16, 17]
[18, 19, 20, 21]
]}
# Save the data to a file
pyexcel.save_book_as(bookdict=2d_array_dictionary, dest_file_name="2d_array_data.xls")При использовании кода, напечатанного в приведенном выше примере, важно помнить, что порядок ваших данных в словаре не будет сохранен. Если вы не хотите этого, вам нужно сделать небольшой обход. Вы можете прочитать все об этом здесь.
Чтение и запись .csv файлов
Если вы все еще ищете библиотеки, которые позволяют загружать и записывать данные в файлы .csv, кроме Pandas, лучше всего использовать пакет csv:
# import `csv`
import csv
# Read in csv file
for row in csv.reader(open('data.csv'), delimiter=','):
print(row)
# Write csv file
data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
outfile = open('data.csv', 'w')
writer = csv.writer(outfile, delimiter=';', quotechar='"')
writer.writerows(data)
outfile.close()Обратите внимание, что в пакете NumPy есть функция genfromtxt(), которая позволяет загружать данные, содержащиеся в файлах .csv, в массивы, которые затем можно поместить в DataFrames.
Финальная проверка данных
Когда у вас есть данные, не забудьте последний шаг: проверить, правильно ли загружены данные. Если вы поместили свои данные в DataFrame, вы можете легко и быстро проверить, был ли импорт успешным, выполнив следующие команды:
# Check the first entries of the DataFrame
df1.head()
# Check the last entries of the DataFrame
df1.tail()Если у вас есть данные в массиве, вы можете проверить их, используя следующие атрибуты массива: shape, ndim, dtype и т.д .:
# Inspect the shape
data.shape
# Inspect the number of dimensions
data.ndim
# Inspect the data type
data.dtype
Что дальше?
Поздравляем! Вы успешно прошли наш урок и научились читать файлы Excel на Python.
Если вы хотите продолжить работу над этой темой, попробуйте воспользоваться PyXll, который позволяет писать функции в Python и вызывать их в Excel.