
Программа Excel предлагает маркетологам гораздо больше возможностей, чем просто создание таблиц, форматирование графиков или использование основных арифметических формул для расчётов.
Зачастую маркетологи работают в условиях многозадачности и незаслуженно забывают о простых инструментах Excel, способных значительно оптимизировать рабочий процесс.
В этом обзоре расскажем о шаблонах таблиц, горячих клавишах и других не всегда очевидных, но тем не менее полезных функциях Excel, которые помогают экономить время специалиста.
Горячие клавиши — это определённые комбинации кнопок на клавиатуре, нажатие которых запускает какую-либо функцию программы. Excel не является исключением и имеет собственный набор горячих клавиш.
- Выделение таблицы: Ctrl (cmd) + A.
- Сохранить: Ctrl + S.
- Сохранить как: Alt + F2 или F12.
- Копировать: Ctrl (cmd) + C.
- Вставить: Ctrl (cmd) + V.
- Вставить новый лист: Alt + Shift + F1.
- Повторить последнюю команду: F4.
- Перемещение к краю таблицы: Ctrl (cmd) + (стрелки).
- Перемещение к краю таблицы с выделением: Ctrl + Shift + (стрелки).
- Перемещение выделенного диапазона: удерживать Ctrl для копирования.
- Смещение диапазона: перетаскивая, удерживать Shift.
- Вставка диапазона со смещением: удерживать Ctrl + Shift.
- Вставить гиперссылку: Ctrl (Cmd) + K.
- Для перехода к соседней ячейке справа: Tab.
- Для перехода к соседней ячейке слева: Shift + Tab.
- Для перехода на следующую ячейку: Enter.
- Для перехода к предыдущей ячейке: Shift + Enter.
- Правка содержимого активной ячейки: F2.
Помимо горячих клавиш, в Excel есть ряд уже готовых к применению шаблонов для создания планов и бюджетов мероприятий, ведения списков участников и учёта ежедневных заданий.
На основе базовых Excel-шаблонов несколько специализированных компаний также разрабатывают варианты для диджитал-маркетологов, которые учитывают цели и особенности именно этой области маркетинга.
Маркетолог должен не только иметь общее видение стратегии и полный обзор мероприятий в рамках этой стратегии, но и регулярно отслеживать ход реализации этих процессов, получать информацию о текущих затратах и своевременно реагировать на изменение рынка. Excel предлагает множество встроенных шаблонов для этих целей.
Например, есть несколько таблиц для ведения бюджета различных маркетинговых мероприятий. Как правило, в каждую из них уже заложены основные статьи расходов и формулы расчёта, которые можно легко модифицировать под собственные нужды и проекты.
Бюджет маркетингового плана
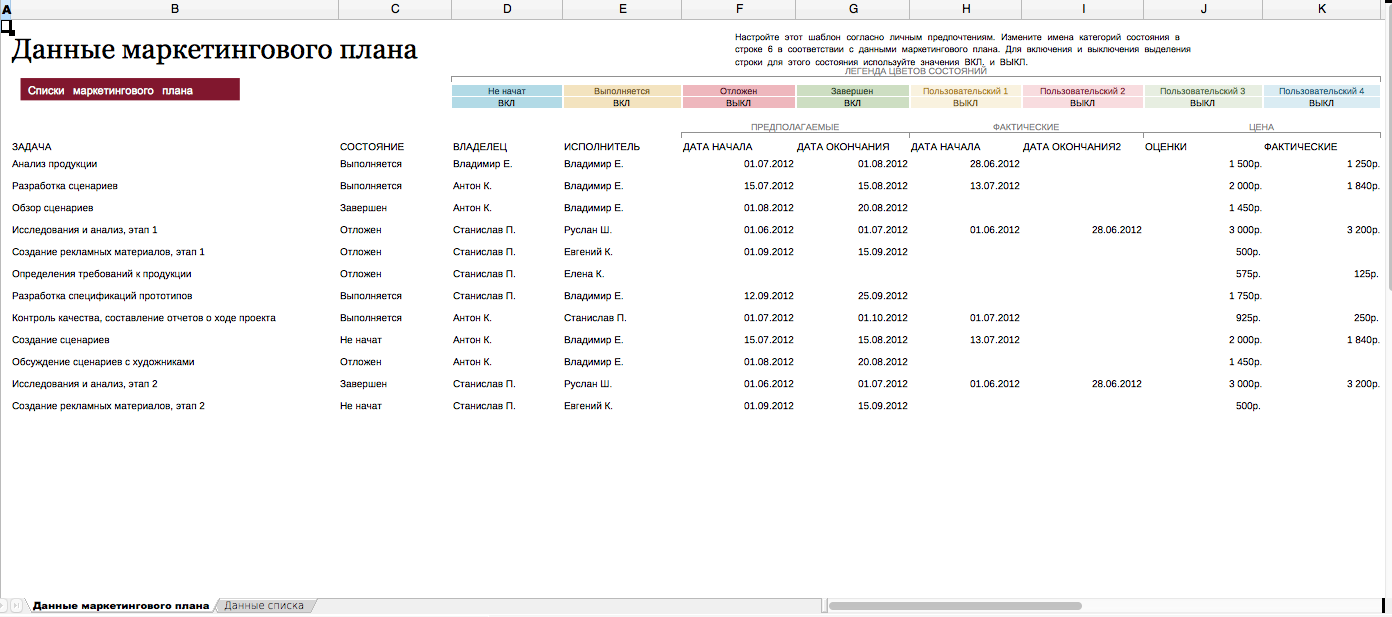
Стандартный бюджет мероприятия
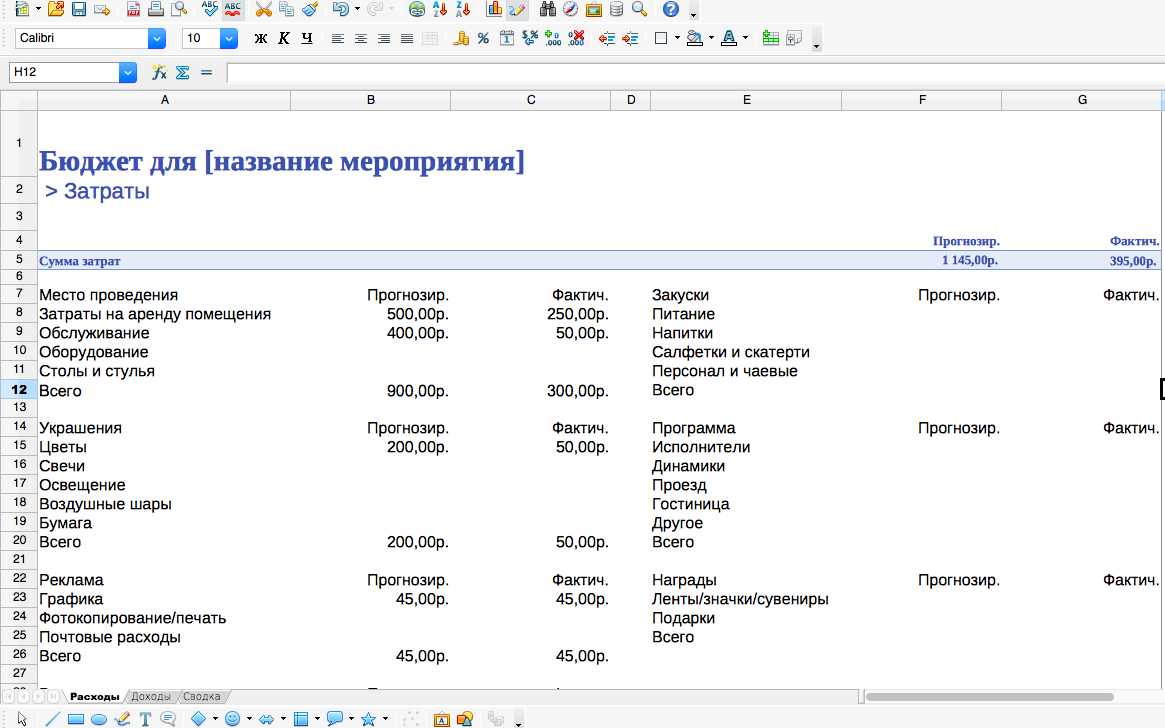
Бюджет канального маркетинга
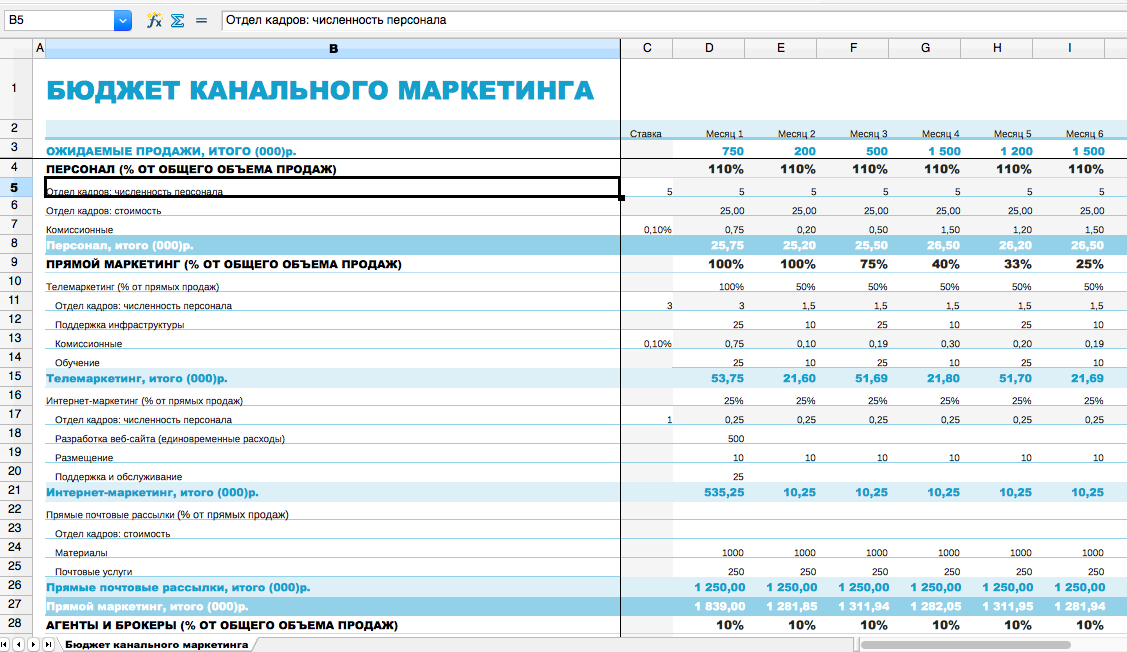
Планировщики идей
Ещё до того как приступить к бюджетированию маркетинговой кампании, специалисты работают над генерированием идей и постановкой маркетинговых целей.
На этот случай Excel предлагает несколько вариантов таблиц-планировщиков. В них можно не только зафиксировать маркетинговые идеи, задачи и цели, но и настроить контроль над их разработкой и исполнением.
В интернете есть множество шаблонов, созданных на базе обычной таблицы Excel и модифицированных под задачи в области диджитал. Компании Hubspot и Vivial предоставляют их бесплатно при условии регистрации на сайте.
Вот один из таких шаблонов: он помогает отслеживать соответствие публикаций общей маркетинговой стратегии с помощью чёткого распределения заданий, учёта срока их исполнения, а также указания краткого содержания материала и используемых ключевых слов.
Работая с постами в социальных сетях, маркетологи стремятся не только повысить интерактивность посетителей, но и увеличить их количество.
Шаблон таблицы размещения публикаций в соцсетях помогает эффективно распределить посты по дням, часам и медийным каналам. Благодаря своей функции автоматического подсчета знаков, Excel особенно полезен в работе с Twitter.
На базе Excel создан и этот вариант единого детального плана для контент-маркетинга на месяц. Шаблон позволяет не только планировать различные формы подачи контента в рамках кампаний, но и одновременно распределять их для размещения на различных медиа-каналах.
Excel-таблицы активно используются для анализа ведения кампаний в Adwords. Этот шаблон упорядочивает информацию по настройке кампаний для разных целевых групп и отражает наиболее эффективные из них.
Работая над стратегией SEO-продвижения, маркетологи одновременно контролируют несколько показателей, которые характеризуют динамику изменений трафика, определяют причины этих изменений и оценивают результаты кампании. Excel-таблицы позволяют создать шаблон оценки SEO-продвижения благодаря аккумулированию входящей информации в одном месте.
Когда цели поставлены, кампании запущены и уже виден результат некоторых из них, можно обратиться к ещё одному шаблону — таблице для ежемесячного отчёта по метрикам. Она отражает изменения метрик по каналам ежемесячно и выдает итоговую сводку за год.
Неотъемлемая часть работы маркетолога — визуализация информации о проделанной работе и её представление руководству компании, партнерам или клиентам.
Excel предлагает несколько встроенных функций форматирования, благодаря которым таблицы и графики становятся красочнее и понятнее для заинтересованной аудитории.
Одно из самых простых решений — воспользоваться встроенными стилями для таблиц и выделить строки разными цветами.
Найти стили в Excel для Windows можно по следующему пути: Home > Styles > Format as Table. На Mac: Tables > Table Styles.
Визуально украсят таблицу и элементы, предлагаемые функцией «Условное форматирование». С помощью создания различных условий для ячеек таблицы можно выделить разными цветами минимальные и максимальные значения табличных данных, а также добавить в ячейки гистограммы и другие иконки для иллюстрации данных.
Чтобы воспользоваться этой функцией, в разделе Conditional Formatting необходимо выбрать одно из предложенных условий, либо создать своё. Для Mac функция расположена в разделе Format.
Если представление данных требует их объединения и классификации, можно воспользоваться функцией «Сводные таблицы». Особенно полезными оказываются эти таблицы при работе с большим объемом данных.
Сводные таблицы позволяют фильтровать, группировать и сравнивать данные.
Чтобы создать этот инструмент на Mac, необходимо в разделе Data выбрать функцию Pivot Table. На Windows: Insert > Table > Pivot Table.
Программа предложит создать сводную таблицу либо на листе с исходной, либо на отдельном листе. Далее на странице появится конструктор сводных таблиц (Pivot Table Builder), который предложит выбрать нужные для анализа поля и указать анализируемое значение. В списке полей располагаются названия колонок исходной таблицы.
Сводная таблица позволяет как угодно распределять данные между колонками и столбцами, добавлять один или несколько анализируемых параметров, группировать данные и устанавливать необходимые фильтры.
Функция также позволяет в любой момент изменить поля, поменять их местами или добавить новые, а также обновить или детализировать параметры для получения более точной информации.
Диджитал-маркетологи часто используют эту функцию для прогнозирования трафика посещений сайта или просмотра публикаций. На основе данных сводных таблиц получают информацию, необходимую для запуска наиболее эффективных кампаний в Adwords или Яндекс.Метрике.
- Сможете уверенно работать в Excel и легко использовать расширенные возможности программы
- Узнаете, как создавать наглядные и удобные отчёты и оптимизировать свою работу
- Научитесь анализировать эффективность продаж и рекламы и контролировать затраты
Разобравшись с таблицами, перейдём к следующим возможностям визуализации данных: созданию и обработке графиков.
Отличным подспорьем в работе с графиками является функция «Рекомендованный график». Программа предлагает сравнить несколько версий графической визуализации данных перед тем, как сделать выбор в пользу того или иного варианта. Чтобы воспользоваться этой функцией нужно выбрать Recommended Charts в разделе Insert.
Excel включает в себя богатый набор стандартных инструментов для обработки графиков: выбор цветового решения, изменение фона графика, а также обработку осей координат и подписей к ним — легенд.
Работая с графиками, необходимо предварительно сортировать данные и выбирать наиболее выгодное расположение легенд и осей координат. Это обеспечит понятную визуализацию.
Также в программе можно создавать брендированные графики. Все эти функции доступны в разделе Insert > Charts.
Добавление легенды на диаграмму
Улучшение фона графика
Предварительная сортировка данных
В Excel есть большое количество встроенных формул для автоматизации расчётов. На базе уже существующих формул продвинутые пользователи создают собственные варианты, которые помогают производить сложные расчёты в течение нескольких секунд даже для больших объёмов данных.
Рассмотрим пять неочевидных, но интересных для маркетологов формул.
Формула «вертикальный просмотр» (ВПР, VLOOKUP)
Позволяет найти данные в текстовой строке таблицы или диапазоне ячеек и добавить их в другую таблицу. Особенно популярна эта формула при работе над SEO-оптимизацией и используется для анализа статистики запросов.
Для создания формулы необходимо указать ячейку с искомым значением, диапазон поиска и номер столбца, содержащего возвращаемое значение (в нашем примере это второй столбец — B).
Формула «частота» и построение гистограмм (ЧАСТОТА, FREQUENCY)
Для её использования необходимо создать небольшую дополнительную таблицу.
В первом столбце этой таблицы (bins) нужно указать бóльшие значения интересующих нас интервалов (то есть для интервала от 80 до 89 в столбце для расчета мы указываем 89). Во втором столбце (Frequency) следует ввести формулу «частота» с указанием диапазона данных для поиска и созданного столбца с интервалами.
Программа автоматически посчитает распределения частот в вертикальном массиве.
После этого останется лишь создать ещё один столбец с более подробным описанием интервала и создать график в виде гистограммы.
Формула «если» (ЕСЛИ, IF)
Выполняет проверку заданных условий, выбирая один из двух возможных результатов:
1) Если сравнение истинно;
2) Если сравнение ложно.
В своем самом простом виде эта формула выглядит так: IF(logical_test, value_if_true, value_if_false).
Например, нам необходимо проанализировать таблицу с бюджетами мероприятий на предмет соответствия реальных затрат запланированным суммам. В этом случае формула будет выглядеть следующим образом:
Для более сложных вычислений формула утяжеляется новыми условиями и внедрением формул в формулу, что часто приводит к ошибкам в вычислениях. Поэтому рекомендуется разбивать сложные задания на небольшие этапы и использовать эту формулу в самом простом её виде.
Формула «сцепить» (СЦЕПИТЬ, CONCATENATE)
Объединяет текстовое содержимое нескольких ячеек в одну. Для «сцепки» нужно в формуле указать как номера ячеек с нужным текстом, так и сам текст. Всего можно ввести до 255 элементов и до 8192 символов.
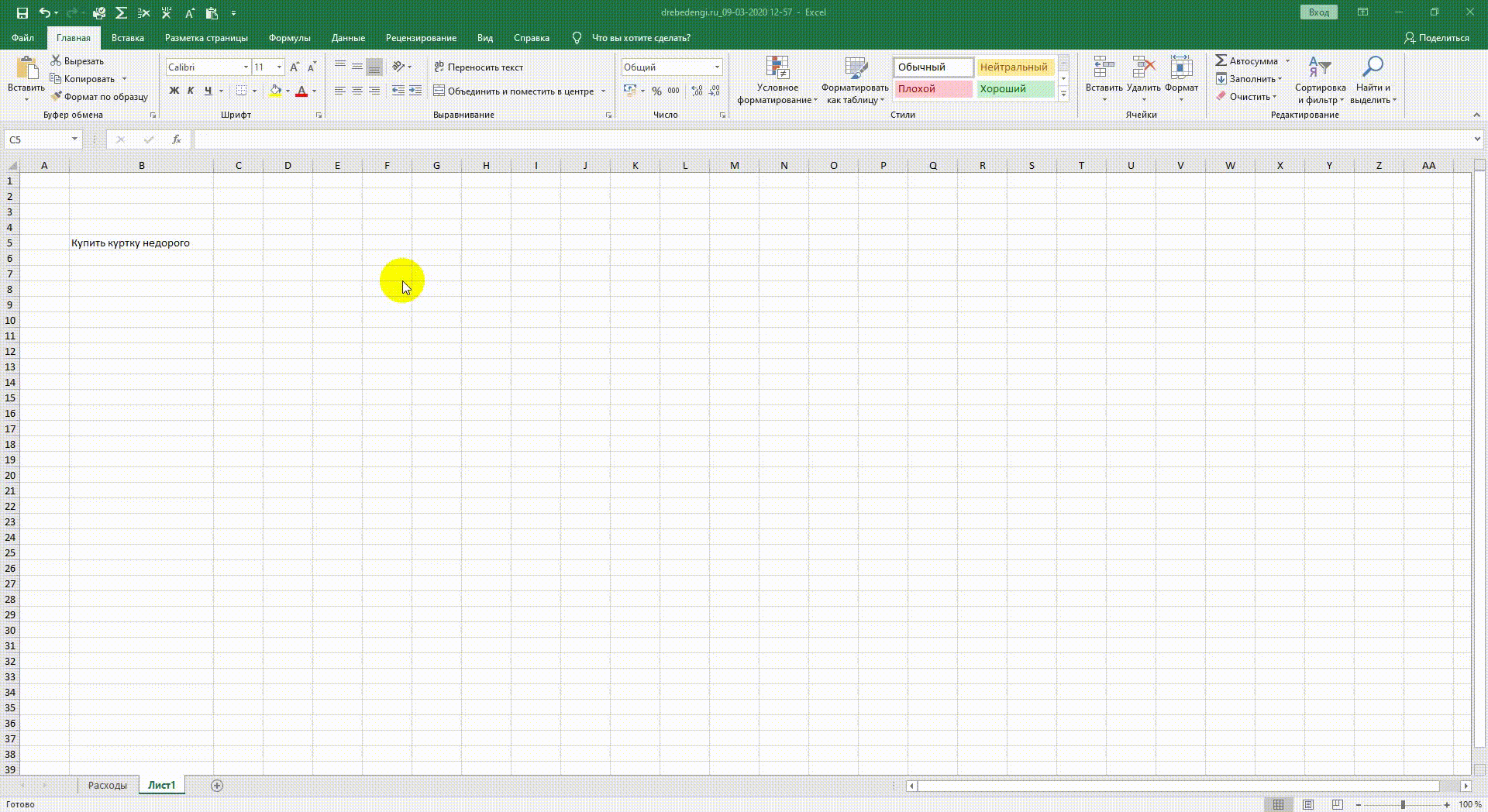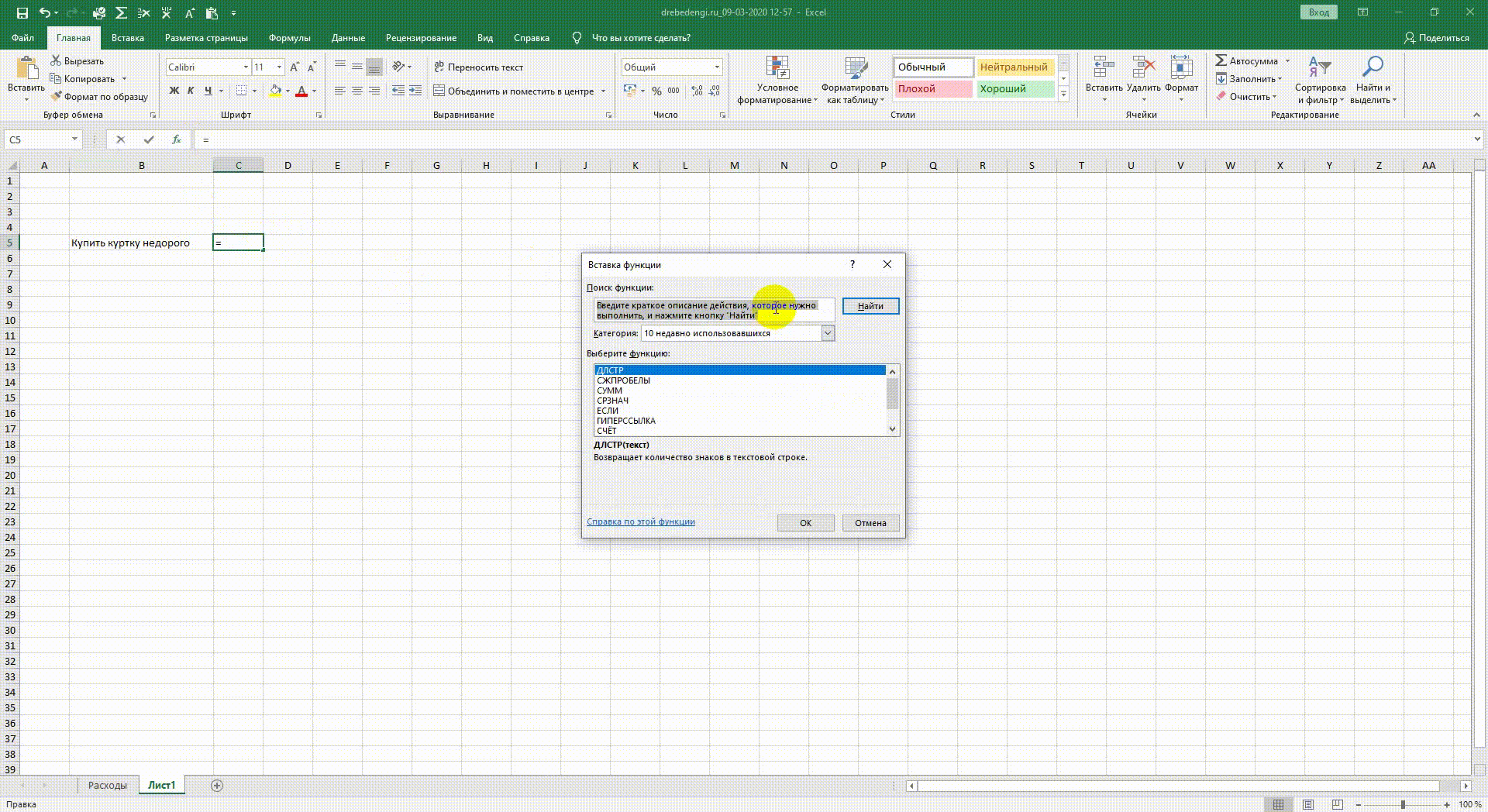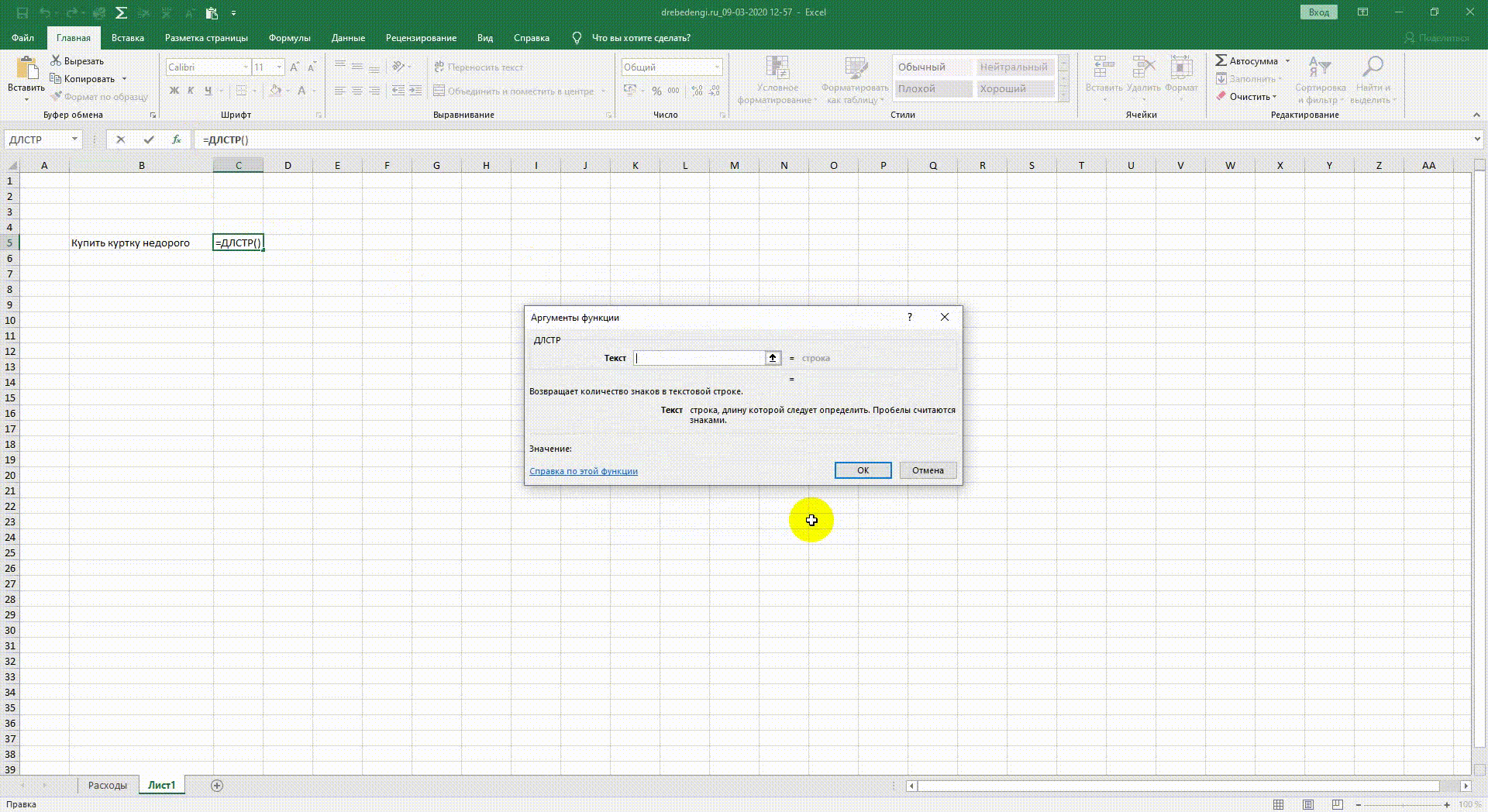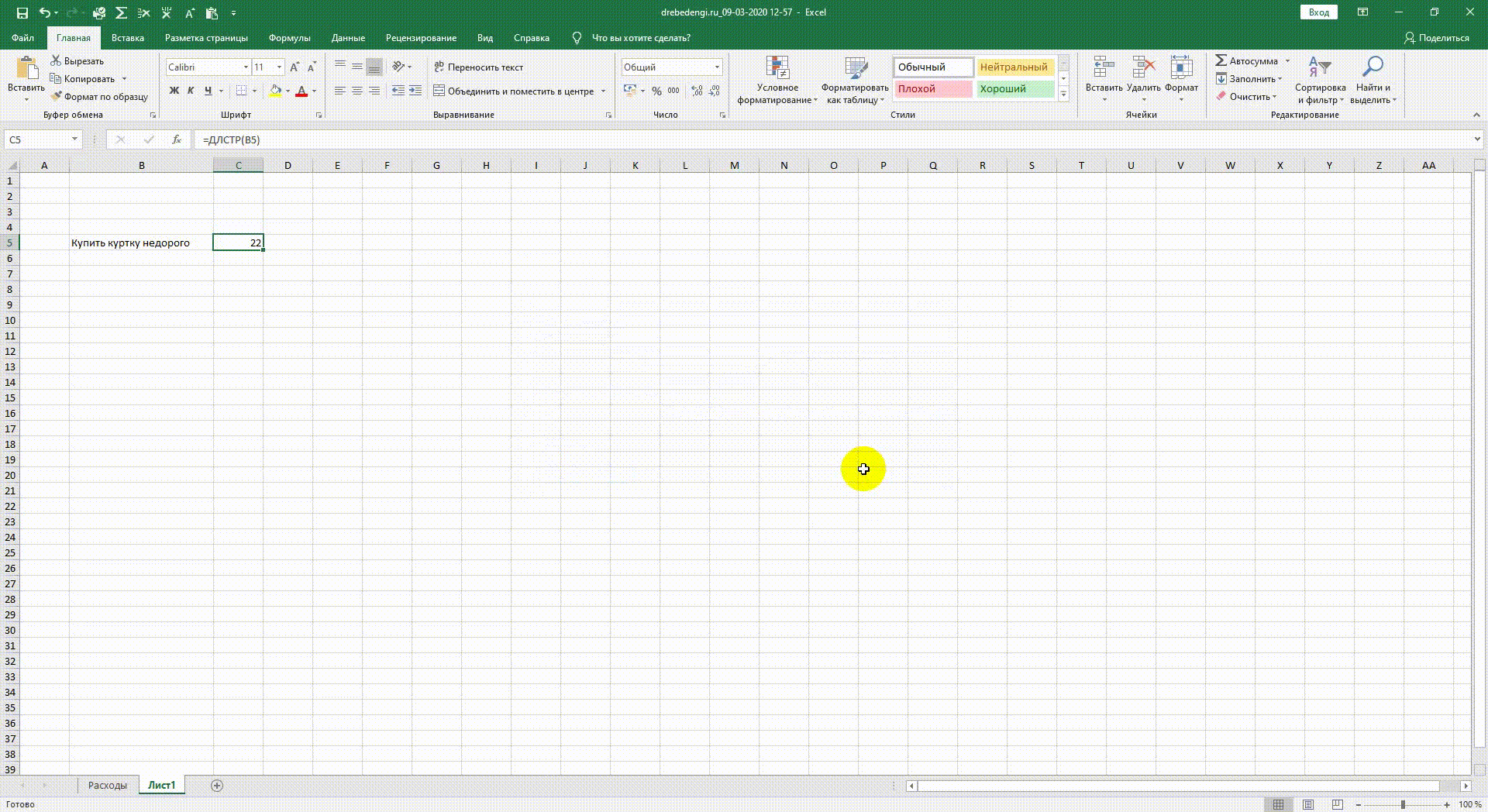
Формула «длина строки» (ДЛСТР, LEN)
Позволяет определить длину текста в указанной ячейке. Эта формула является незаменимой для работы с рекламными кампаниями в Adwords и Метрике, а также с Twitter.
Инструменты Excel способны значительно ускорить работу маркетологов: с ними можно быстрее спланировать продажи, разработать маркетинговый план или сравнить эффективность рекламных кампаний.
Эта статья не является подробным разбором всех возможностей Excel, которые используются для работы с маркетинговыми данными. Она охватывает лишь некоторые функции программы, особенно полезные для работы маркетологов или разработанные непосредственно для них. Надеемся, они вам пригодятся.
Мнение автора и редакции может не совпадать. Хотите написать колонку для Нетологии? Читайте наши условия публикации. Чтобы быть в курсе всех новостей и читать новые статьи, присоединяйтесь к Телеграм-каналу Нетологии.
Excel — программа для работы с электронными таблицами. Системы аналитики используют Excel для импорта и экспорта данных.
Excel подойдет не всем. Крупным организациям приходится работать с непрерывным и большим объемом информации, координировать работу нескольких отделов и чаще исправлять ошибки. Если вы крупная организация, пользуйтесь профильными CRM-системами.
Excel подойдет малому бизнесу и частным маркетологам. Excel поможет вам организовать работу: составить список клиентов, спланировать продажи, разработать маркетинговый план, сравнить эффективность рекламных кампаний. Это экономит время и деньги: вы храните, обрабатываете и загружаете информацию в едином рабочем пространстве.
Разберем, как настроить рабочее пространство, использовать таблицы и диаграммы, спарклайны и формулы.
Сочетания и горячие клавиши в Excel
Напомним, как сэкономить время при работе в программе Excel с помощью базовых сочетаний клавиш.
Общие действия
|
Выделение таблички |
|
Сохранить |
|
Сохранить как |
|
Копировать выделенные данные |
|
Вставить выделенное |
|
Вставить новый лист |
|
Отмена операции |
|
Вырезать диапазон данных |
Эти сочетания клавиш пригодятся и для работы в Microsoft Word.
Работа с таблицами
Чтобы быстро перемещаться по странице или таблице, пригодятся еще несколько сочетаний.
|
Перемещение к краю таблицы |
|
Перемещение к краю таблицы с выделением |
|
Вставить гиперссылку: Ctrl + K |
Ввод текста
|
Для перехода к соседней ячейке справа |
|
Для перехода к соседней ячейке слева |
|
Для перехода на следующую ячейку |
|
Для перехода к предыдущей ячейке |
Все сочетания в поддержке Office:
Сочетание клавиш для Windows
Сочетание клавиш для Mac
Персонализация Excel — как добавить кнопки на панель быстрого доступа
Очень удобная функция, но мало кто о ней знает. Используйте ее, чтобы вынести самые часто используемые функции на панель быстрого доступа. Для этого нужно кликнуть на нужную функцию и выбрать “Добавить на панель быстрого доступа”.

Как форматировать таблицы
Форматировать таблицы должен уметь каждый маркетолог.
Данные, в которых однородные элементы расположены с строчках (например, статистика из систем контекстной рекламы или веб-аналитики) перед выполнением каких-либо действий лучше форматировать «Как таблицу».
Благодаря форматированию можно не только преобразить, но и структурировать таблицу.

Используйте готовые стили таблиц для быстрого форматирования.
Можете создавать и применять в работе свой собственный стиль таблицы.
Как сделать собственный стиль:
1. В окне открытого листа выделите любую ячейку таблицы.
2. Перейдите к вкладке «Конструктор» и в группе «Стили таблиц», раскройте меню кнопки «Дополнительные параметры».
3. В списке команд выберите пункт «Создать стиль таблицы».
4. В окне «Создание экспресс стиля таблицы» в графе «Имя» наберите название стиля.

5. В группе «Элемент таблицы» выберите в списке элемент для форматирования и нажмите кнопку «Формат».
6. В окне «Формат ячеек» на вкладках «Шрифт», «Граница» и «Заливка» задайте нужные параметры стиля.
7. Примените действия кнопкой «ОК».
Форматирование таблиц можно дополнительно настраивать, задавая параметры экспресс-стилей для элементов таблиц. Например, строк заголовков и итогов, первого и последнего столбцов, чередующихся строк и столбцов, а также параметры автофильтра. Для этого выделяем диапазон (клик внутрь таблицы и Ctrl+A) и зажимаем Ctrl+T. Подтверждаем выбранный диапазон, если в таблице есть заголовки, выбираем опцию “Таблица с заголовками”.
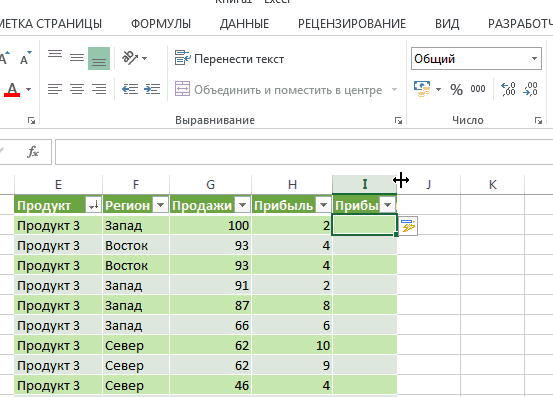
Таблица приобретет новое форматирование и в заголовках появятся фильтры:
- При создании формулы, она автоматически растянется на весь столбец;
- Во вкладке “Конструктор” можно добавить внизу таблицы итоговую строку (“Строка итогов”), в которой можно делать вычисления по щелчку мыши.
Преимущество форматирования данных в качестве таблицы — это множество вариантов сортировки и фильтрации. Вы можете получить к ним доступ, щелкнув на любой из треугольников, расположенных внизу, в строке заголовка. Если в вашем столбце текст, вы увидите параметры фильтра, специфичные для текста, и, если цифры, они будут сопоставляться с числами.

Подробно об этом в поддержке MS Office.
Форматирование таблиц помогает отследить данные, которые вы хотите, также ускоряет процесс нахождения информации с помощью фильтров. Благодаря фильтрации по цвету можно быстро сделать анализ, к примеру, по объему продаж. Вы можете получить все те же функциональные возможности, добавив фильтры в строку заголовка.
Как выбрать стиль таблицы
Если в книге есть диапазон данных, не отформатированный как таблица, Excel автоматически преобразует его в таблицу, когда вы выберете ее стиль. Можно изменить формат существующей таблицы, выбрав другой вариант:
1. Выделите любую ячейку таблицы или диапазон ячеек, который вы хотите форматировать как таблицу.
2. На вкладке Главная выберите Форматировать как таблицу.
3. Выберите нужный стиль
Условное форматирование позволяет быстро выделить на листе важные сведения. Но иногда встроенных правил форматирования недостаточно. Создав собственную формулу для правила условного форматирования, можно выполнять действия, которые не под силу встроенным правилам в сервисе.
Диаграммы
Маркетинговые данные часто представляют в виде диаграм, т.к.их удобно представлять визуально.
Даже с большим набором данных, которые нелегко начертить, можно использовать условное форматирование, или по крайней мере добавить несколько подсказок о данных в таблицы. Но если вы не имеете дело с большим и тяжелым набором данных, вам следует визуально представить свои данные, наглядно показав результат.

К примеру, вы делаете отчетность по продажам каждый месяц. Смотря на цифры достаточно сложно быстро сделать анализ, выросли продажи в сравнении с предыдущем месяцем или нет. Используйте графики, где наглядно можно проследить динамику продаж в течение длительного промежутка времени.
Возможность быстрого анализа данных часто помогает принимать более эффективные деловые решения.
Сводные таблицы
Удобный инструмент анализа табличных данных — сводная таблица.
Используйте отчет сводной таблицы, чтобы обобщать и анализировать большой объем информации.
С помощью сводной таблицы вы сможете:
- распределять данные между колонками и столбцами
- добавлять один или несколько анализируемых параметров
- группировать данные
- устанавливать фильтры
Их можно создавать с помощью нескольких действий и быстро настраивать в зависимости от того, как вы хотите отобразить результаты.
Например, вот список расходов семьи и сводная таблица, созданная на его основе:
|
Данные о расходах семьи: |
Соответствующая сводная таблица: |

|
 |
Как сделать сводную таблицу
- Щелкните на любую ячейку в диапазоне таблицы.
- Выберете Вставка > Таблицы > Сводные таблицы
- Появится диалоговое окно Создание сводной таблицы, в котором указан ваш диапазон или имя таблицы.
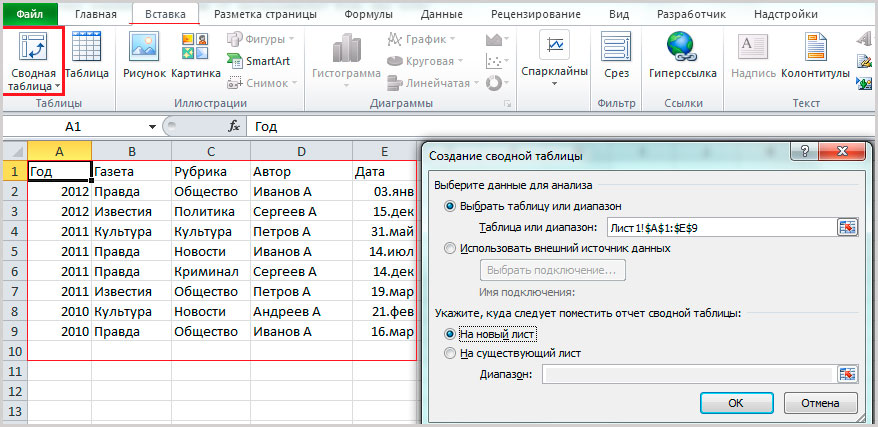
- В разделе укажите, куда вы хотите поместить отчет сводной таблицы. Выберите “На новый лист” или “На существующий лист”. При выборе варианта “На существующий лист” укажите лист и ячейку.
- Нажмите ОК. Excel создаст пустую сводную таблицу и выведет список Поля сводной таблицы.
Можно вручную перетаскивать элементы в любые поля сводной таблицы. Если элемент больше не нужен, просто перетащите его за пределы списка полей. Возможность перестановки элементов — особенность сводной таблицы, благодаря которой можно быстро и просто изменять ее вид.

Как сделать сводную таблицу из нескольких источников данных
Если вам нужно построить сводную сразу из нескольких источников данных, добавьте на панель быстрого доступа «Мастер сводных таблиц и диаграмм», в котором есть такая опция.
Сделать это можно следующим образом: «Файл» → «Параметры» → «Панель быстрого доступа» → «Все команды» → «Мастер сводных таблиц и диаграмм» → «Добавить»:

После этого на ленте появится соответствующая иконка, нажатие на которую вызывает того самого мастера:

При щелчке на неё появляется диалоговое окно:

В нём вам необходимо выбрать пункт «В нескольких диапазонах консолидации» и нажать «Далее». В следующем пункте можно выбрать «Создать одно поле страницы» или «Создать поля страницы». Если вы хотите самостоятельно придумать имя для каждого из источников данных — выберите второй пункт:
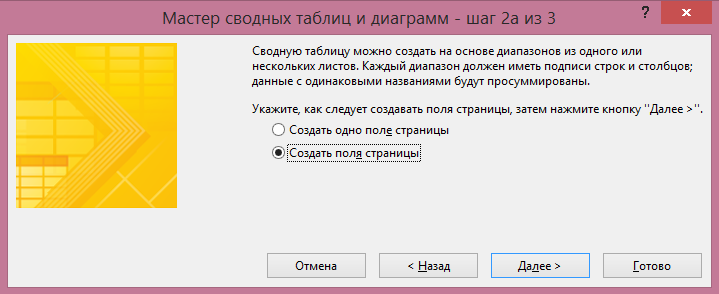
В следующем окне добавьте все диапазоны, на основании которых будет строиться сводная, и задайте им наименования.
После этого в последнем диалоговом окне укажите, где будет размещаться отчёт сводной таблицы — на существующем или новом листе.

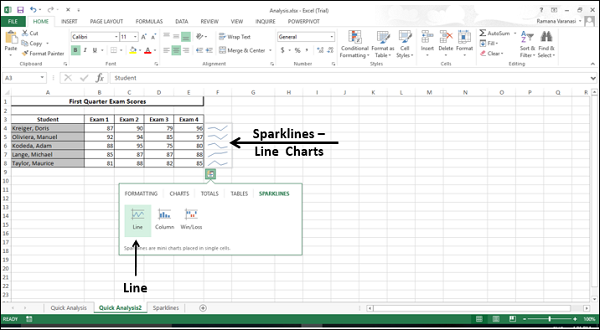
Спарклайны (Sparklines)
Спарклайны — графики, которые располагаются в ячейке таблицы. Помогают визуализировать данные и замечать тенденции, как на рисунке ниже.
Формулы Excel в помощь интернет-маркетологу
Давайте рассмотрим функции Excel, которые нужны для работы с рекламными кампаниями.
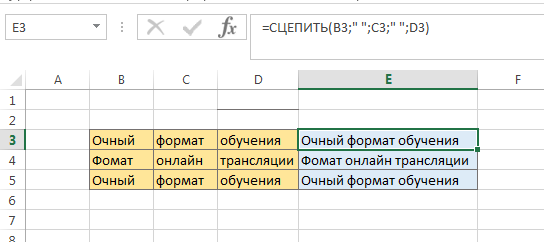
Полезная функция склеивания текстовых строк: =СЦЕПИТЬ(A7;B7).
Функция облегчает работу при подборе ключевых слов методом мозгового штурма, когда нужно сцепить слова из разных ячеек.

Преобразование букв из строчных в прописные и наоборот. За это отвечают следующие функции:
=СТРОЧН(A9) – преобразует все буквы в строчные;
=ПРОПИСН(A11) – преобразует все буквы в прописные;
=ПРОПНАЧ(A10) – преобразует первую букву каждого слова в заглавную, остальные в строчные.

Для чего нужны данные функции?
Одна из них пригодится при создании рекламных объявлений по схеме «1 фраза = 1 объявление». Копируем запросы в столбец с заголовками и применяем к новым заголовкам функцию ПРОПНАЧ.
При работе с рекламными кампаниями и анализе статистики может возникнуть необходимость в логических функциях. Рассмотрим пример с самой распространенной логической функцией ЕСЛИ:
=ЕСЛИ(C6>33;»Превышен лимит»;»Все ок»).
В примере функция применяется для проверки длины заголовка. Если значение в ячейке больше 33, выводится сообщение «Превышен лимит», если меньше – «Все ок».
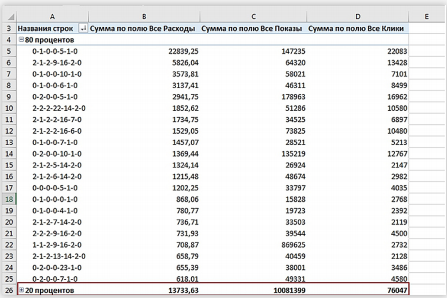
Правило сортировки 80/20 (правило Паретто)
Это правило можно использовать для анализа аккаунта сервиса контекстной рекламы по кампаниям или для кампаний с большим расходом. Обычно большую часть бюджета (80%) расходуют 20% кампаний, так же и 80% расхода рекламной кампании тратят 20% ключевых слов. Этим 20% нужно уделять больше внимания и времени, а остальным 80% на начальном этапе можно пренебречь (или анализировать в последнюю очередь). Чтобы они не мешали и не усложняли таблицы, их лучше скрыть.
В Сводной таблице можно сделать группировку с помощью нарастающего итога. Выводим “Все расходы” дважды, один подсчитываем нарастающим итогом в % (Показывать значения как — % от Суммы нарастающим итогом). Группируем 2 группы “80процентов” и “20процентов” с помощью функции Группировать.

Так вы сможете сосредоточиться на самых важных кампаниях.
Как зачистить спецсимволы и минус-слова в заголовках объявлений
При копировании ключевых слов в заголовки вставляется большое количество ненужных символов. Убрать лишние символы и слова можно с помощью функции поиска и замены.
Чтобы удалить минус-слова, воспользуйтесь комбинацией клавиш Ctrl+F, в модальном окне на вкладке «Заменить» в поле «Найти» введите знак “-” и после него поставьте “*”. Поле «Заменить» оставляем пустым.
По такому же принципу можно удалить все кавычки и другие ненужные в тексте символы. В итоге получается «чистый» список ключевых фраз без лишних значений, кавычек и минус-фраз.
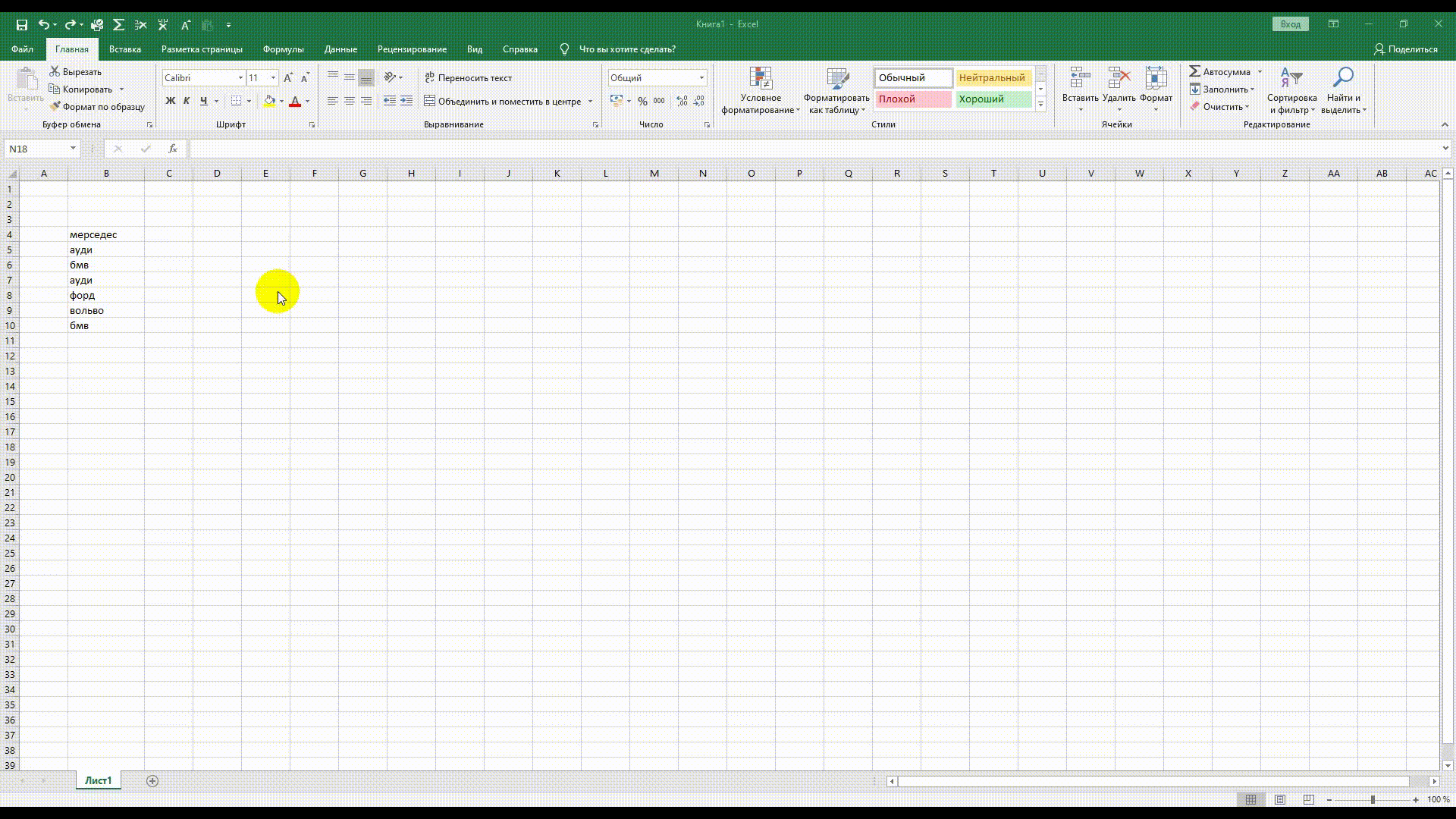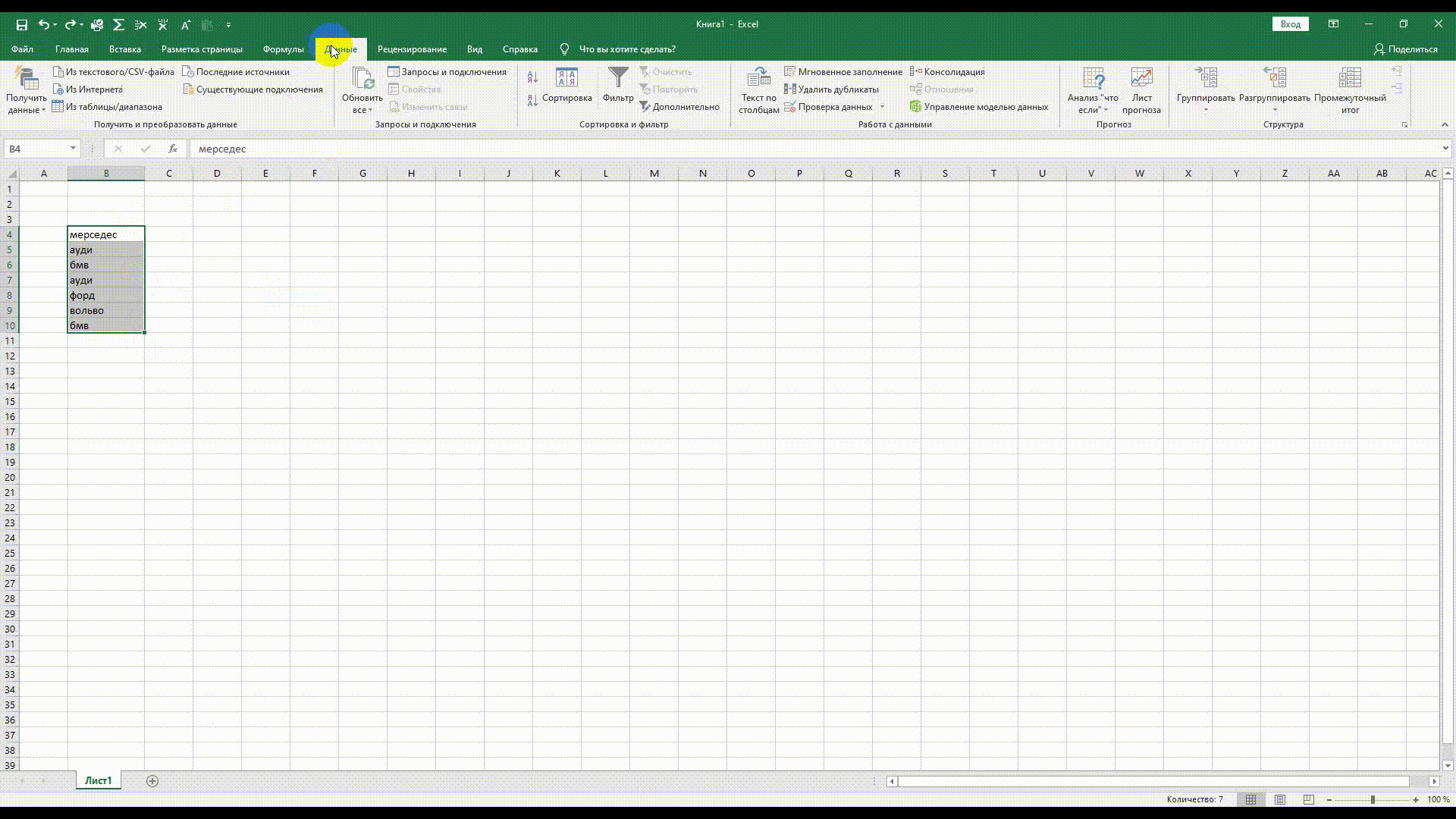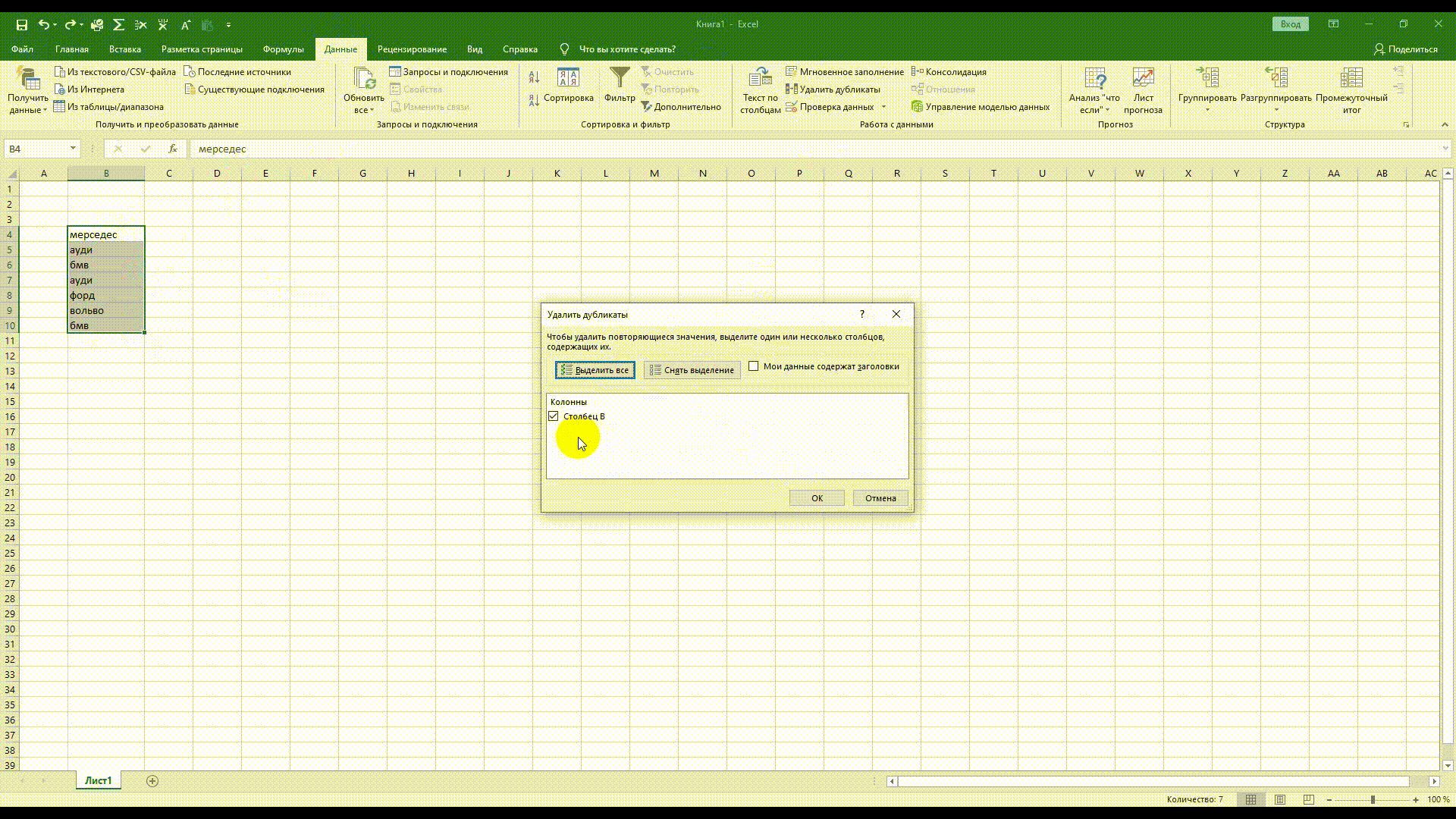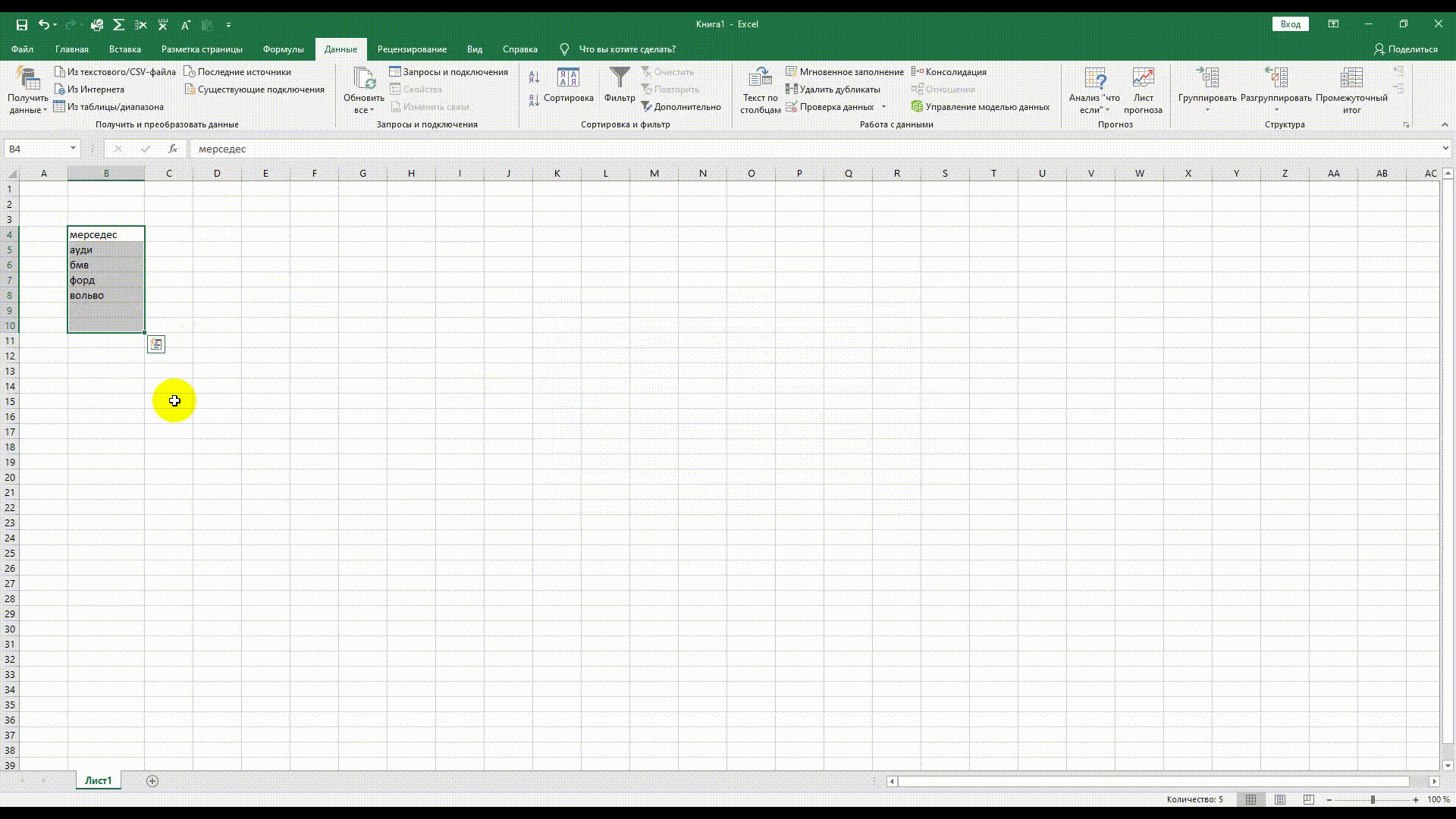
Как удалить дубли
При сборе большого количества ключевых слов можно упустить слова, которые повторяются. Воспользуйтесь встроенным функционалом Excel. Выделяем область данных, заходим в Меню «Данные» → «Удалить дубликаты».
Зачем нужна функция ВПР
ВПР — вертикальный просмотр — VLOOKUP — Vertical LOOK UP)
Чтобы быстро получить данных из этих больших таблиц, используйте функции подстановок. Основное применение данных функций — это подставить данные и сравнить несколько таблиц. Функция ВПР часто используется для анализа статистики запросов.
Допустим, мы ищем количество просмотров по фразе «купить недорогой смартфон».
Результатом поиска будет значение ячейки, где стоит слово из запроса «планшет»: 23112.
С помощью этой функции можно найти данные, соответствующие значению слова «планшет» из ячейки С3, что служит искомым. Вторым аргументом «таблица» тут будет выступать диапазон A1: B6, а третьим «номер столбца» — число «2». Итак, в результате получается формула: =ВПР (С3;А1:B6;2).
Секрет функции ВПР в организации данных таким образом, чтобы искомое значение отображалось слева от значения, которое нужно найти.
Формулы для работы с семантикой — ДЛСТР
Функция = ДЛСТР(LEN) определяет количество символов в текстовой строке, например, в заголовках или текстах объявлений.

Встроенные шаблоны под задачи маркетологов
В интернете множество шаблонов на базе Excel под задачи в области digital. Компания Hubspot предоставляет их бесплатно при условии регистрации на сайте компании.
Пример: шаблон Excel для анализа ведения кампаний в Яндекс.Директ и Google Adwords:
Excel-таблицы используются для анализа ведения кампаний в Яндекс.Директ и Google Adwords. Этот шаблон упорядочивает информацию по настройке кампаний для разных целевых групп и отражает наиболее эффективные из них.
Скачать шаблон можно тут.
Больше готовых шаблонов под задачи интернет-маркетолога в блоге Hubspot.com.
Заключение
Мы разобрали основные возможности программы Excel для повседневной работы. Изучайте Excel, и вы сэкономите время разработки объявлений, создания отчетов и другой рутинной работы интернет-маркетолога.
Чтобы помочь нашим студентам освоить Excel быстрее и на практике, мы разработали курс Excel для интернет-маркетологов. На нем вы научитесь:
- Эффективно использовать MS Excel
- Проводить анализ статистических рекламных выгрузок и визуализировать данные
- Работать с основными формулами при анализе рекламных кампаний
- Оптимизировать бюджеты на рекламу
- Составлять медиапланы
- Быстро и наглядно приводить отчеты в отличное состояние
- Усвоите горячие клавиши по работе в Excel
Рекламная модель pay per click (PPC) предполагает оплату только за ту размещенную рекламу, по которой пользователь кликнул. Чтобы качественно оптимизировать кампанию, не стоит не забывать о данных. Без их анализа добиться высоких результатов сложно.
Зная Excel или «Google Таблицы» выше базового уровня, вы повысите эффективность работы и качество анализа. Есть целый ряд функций и формул, которые помогут сделать его быстрее. Семь рассмотренных ниже вариантов помогут определить наиболее эффективную оптимизацию PPC.
Упомянутые ниже формулы подходят не только для Excel, но и для «Google Таблиц». Если у вас русифицированная версия Excel, функции прописываются русскими буквами. Это второй вариант формулы в случаях, где она указана.
Основные формулы
Их стоит знать каждому — они помогут упростить работу с громоздкими задачами.
1. Дельта
С помощью дельты вы сможете оценить скорость изменений. Для специалистов performance-маркетинга это особенно важно. Необходимо четко понимать, как меняются показатели, чтобы разработать эффективную оптимизацию.
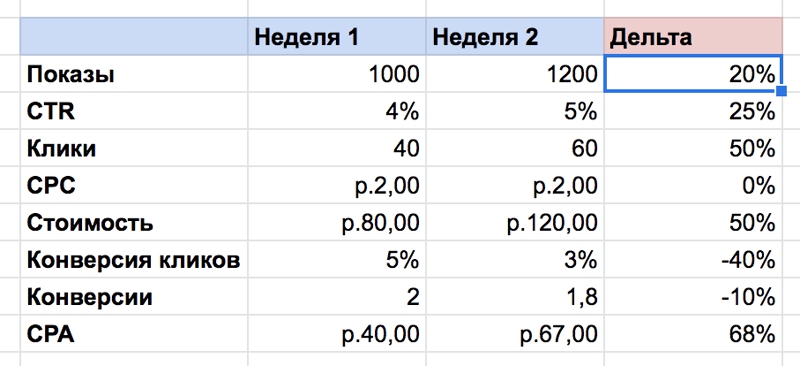
В примере дельта конверсии кликов очень высокая. Если посмотреть на абсолютные цифры — 5 % и 3 % — легко упустить серьезное снижение. Дельта явно показывает, что конверсия кликов должна улучшиться, чтобы повысить Cost Per Action (CPA) кампании.
Для применения функции используйте следующую формулу:
=(ячейка2)/(ячейка1) – 1;
=E2/D2-1.
2. Пошаговые изменения
Расчеты пошаговых изменений согласуются с выводами из дельты. Чем больше значение дельты, тем выше будет и показатели пошаговых изменений. В целом можно использовать только одну из этих формул. Совместное применение не даст каких-то новых данных.
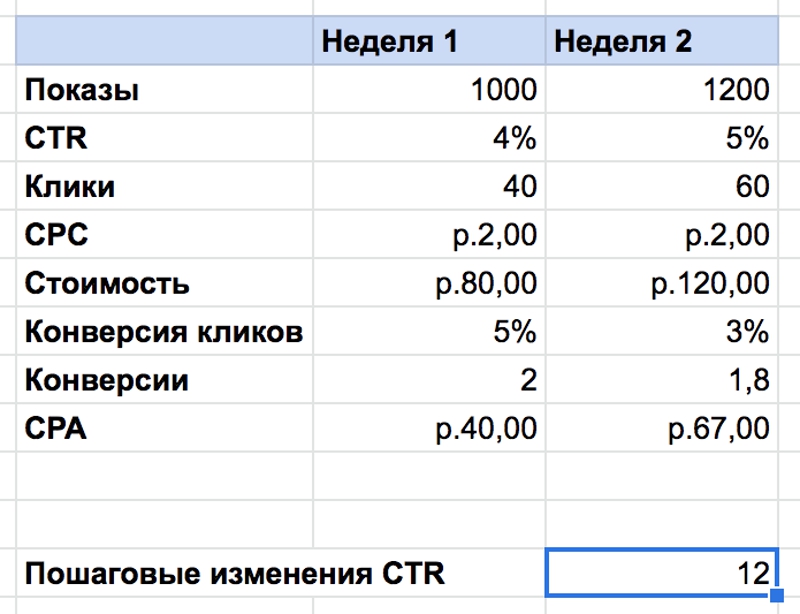
Также учитывайте, что эта формула работает только для постоянных данных, которые не меняются. Однако в маркетинге такое бывает редко. Если показы вырастут на 50 %, CTR, скорее всего, снизится. Сначала попробуйте дельту, чтобы оценить изменения производительности.
Для применения функции используйте следующую формулу:
=[показатель2]*([ячейка2]-[ячейка1]);
=E2*(E3-D3).
3. Сцепка строк, или конкатенация
Если вам на ежедневной основе нужно объединять объемные данные, эта функция будет наиболее полезной. Она позволяет совмещать содержимое нескольких ячеек в одну текстовую строку.
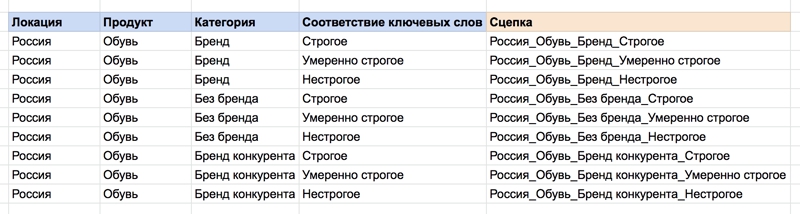
Важно отметить, что функция не ограничивается ячейками. Текст и символы можно включить в формулу в качестве полей за счет использования кавычек.
Для применения функции используйте следующую формулу:
=CONCATENATE(текст_1; [текст_2; …])
=СЦЕПИТЬ(текст_1; [текст_2; …])
= CONCATENATE(K4;»_»;L4;»_»; M4;»_»;N4).
Подготовка наборов данных для анализа
Сводные таблицы очень важны для PPC-маркетолога. Однако для их правильной работы придется потратить время, чтобы набор данных был целостным и детализированным. Приведенные ниже функции и формулы помогут с этим.
4. ВПР, или VLOOKUP
Это одна из главных функций, которые должны освоить поисковые маркетологи, поскольку часто наборы данных необходимо дополнять или модифицировать с учетом собранных на других платформах.
Если отчетность находится за пределами платформы PPC, вы точно сталкивались с проблемами объединения данных. Лучше всего извлекать их на максимально детализированном уровне и использовать VLOOKUP для добавления фильтров.
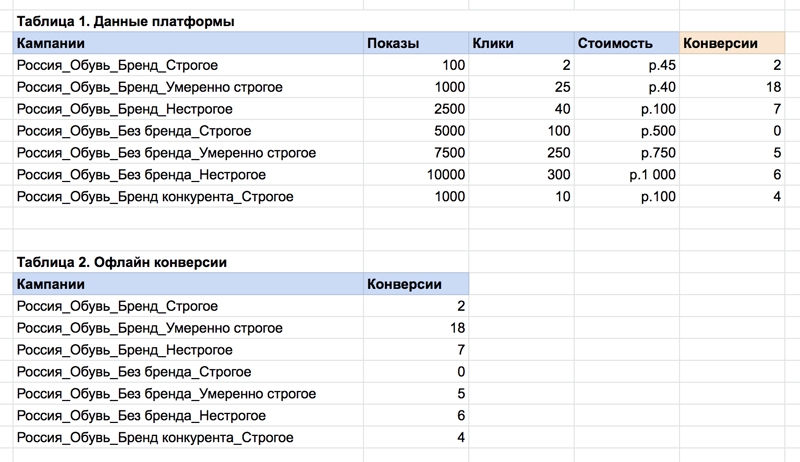
Например, если у вас запрашивают разбивку географических показателей, выберите уровень города, создайте таблицу, связывающую города с регионами, и добавьте столбец для региона в набор данных с помощью VLOOKUP.
Для применения функции используйте следующую формулу:
=VLOOKUP(искомое значение; таблица; номер_столбца; [ЛОЖЬ])
=ВПР(искомое значение; таблица; номер_столбца; [ЛОЖЬ])
=VLOOKUP(Q4;$Q$15:$R$21;2;False)
5. Трансформирование даты в неделю
Функция «Если» или IF полезна при извлечении отчетов. У еженедельных выкладок с платформы могут быть ограничения. Чтобы их обойти, извлеките данные на уровне дня/даты. Затем добавьте столбец в набор данных за неделю, используя формулу.
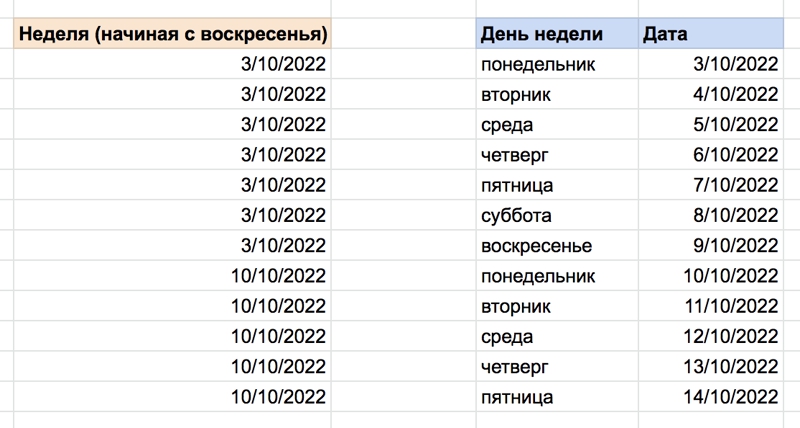
Обратите внимание, что стандартные настройки в Excel указывают 1= воскресенье, 7=суббота. Индикатор дня недели необходимо обновить как в логике оператора IF, так и в возвращаемом значении if false.
Для применения функции используйте следующую формулу:
=IF(WEEKDAY(ячейка с датой1)=от 1 до 7; ячейка с датой1; ячейка с датой1- WEEKDAY(ячейка с датой1))
=ЕСЛИ(ДЕНЬНЕД(ячейка с датой1)=2; ячейка с датой1; ячейка с датой1-ДЕНЬНЕД(ячейка с датой1-2))
=IF(WEEKDAY(R26)=2;R26;R26-WEEKDAY(R26-2))
Инструменты для крупных наборов данных
Если вам нужно работать с крупными базами данных, пригодятся две рассматриваемые ниже формулы.
6. Заполнение категорий
На первый взгляд формула может показаться сложной, но она очень практична для специалистов поискового маркетинга. С ее помощью вы сможете искать в ячейке определенное слово или фразу. Если она соответствует критериям, формула вернет текст, введенный в поле text if true.

Формула может объединять в себе поиск сразу нескольких параметров. В этом случае воспользуйтесь вариантом № 3. В нем описывается поиск разного текста по двум ячейкам, но можно подставить больше формул через точку с запятой до «текст в случае необнаружения».
=IF(ISNUMBER(SEARCH(«искомый текст»;номер ячейки для поиска));»текст в случае обнаружения»;»текст в случае необнаружения»)
=ЕСЛИ(ЕЧИСЛО(ПОИСК(«искомый текст «;номер ячейки для поиска));»текст в случае обнаружения»;»текст в случае необнаружения»)
=IF(ISNUMBER(SEARCH(«искомый текст»;ячейка для поиска1));»текст в случае обнаружения»;IF(ISNUMBER(SEARCH(«искомый текст»;ячейка для поиска2));»текст в случае обнаружения»;»текст в случае необнаружения»))
=IF(ISNUMBER(SEARCH(«%»;D44));»Скидка»;»Ценностное предложение»)
7. Объединение сложных наборов данных
Повысить качество анализа можно, объединив указанные выше методы. Обычно при выгрузке данные содержат несколько сегментов или столбцов атрибутов.
При объединении данных с двух платформ они должны быть одинаково детализированы, в противном случае будут неточности. Чтобы объединить сложные наборы данных, используйте CONCATENATE и вводите формулу в дополнительный столбец. Это будет первым шагом.
Дополнительный столбец будет служить как связующее звено между двумя наборами данных. С помощью функции VLOOKUP импортируйте в него данные из другой исходной таблицы.
Для применения функции используйте следующую формулу:
=CONCATENATE(текст_1; [текст_2; …])
=СЦЕПИТЬ(текст_1; [текст_2; …])
=CONCATENATE(C55;D55)
=VLOOKUP(искомое значение; таблица; номер_столбца; [ЛОЖЬ])
=ВПР(искомое значение; таблица; номер_столбца; [ЛОЖЬ])
=VLOOKUP(B55;$B$64:$E$67;4;False)
Как орешки щелкать!
Выше вы получили немало информации, которую нужно переварить. И это только верхушка айсберга. Excel или «Google Таблицы» — объемные инструменты, на изучение которых требуется немало времени. Однако освоив базу, описанную выше, вам будет проще работать со сложными формулами.
Маркетологам часто приходится работать в режиме многозадачности. Разработка маркетингового плана, составление бюджета, сравнение рекламных кампаний, подбор ключевых слов, создание графиков, планирование продаж. Оптимизировать работу помогает MS Excel – мощнейший аналитический инструмент. Сегодня мы поговорим о полезных для маркетолога функциях в MS Excel.
Персонализация Excel
Персональная настройка рабочего пространства сильно упрощает жизнь. Но многие пользователи, в том числе и опытные, не знают, как добавить кнопки на панель быстрого доступа. Для этого стоит нажать на следующие пункты меню:
Файл – Параметры – Панель быстрого доступа – Добавить
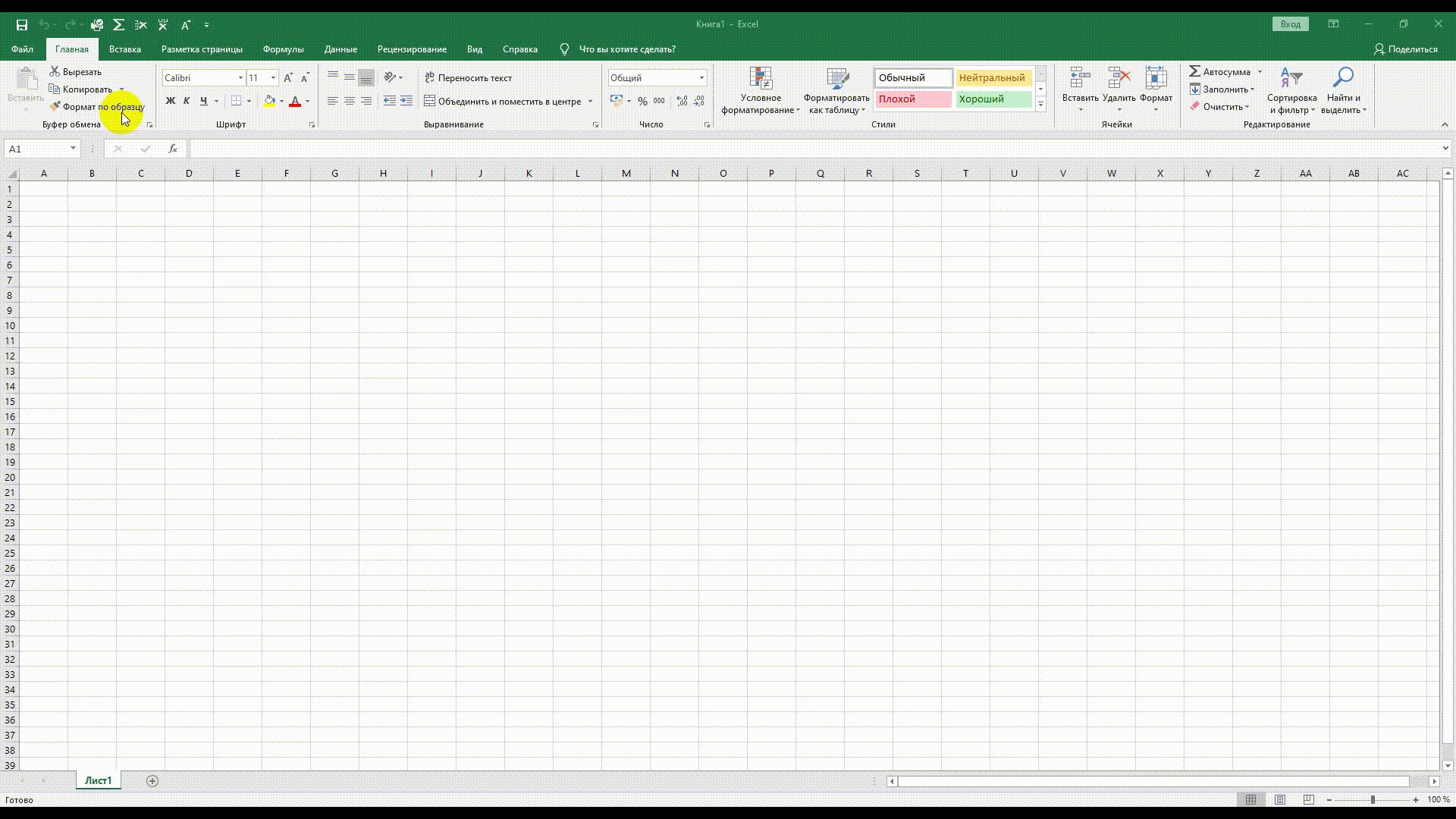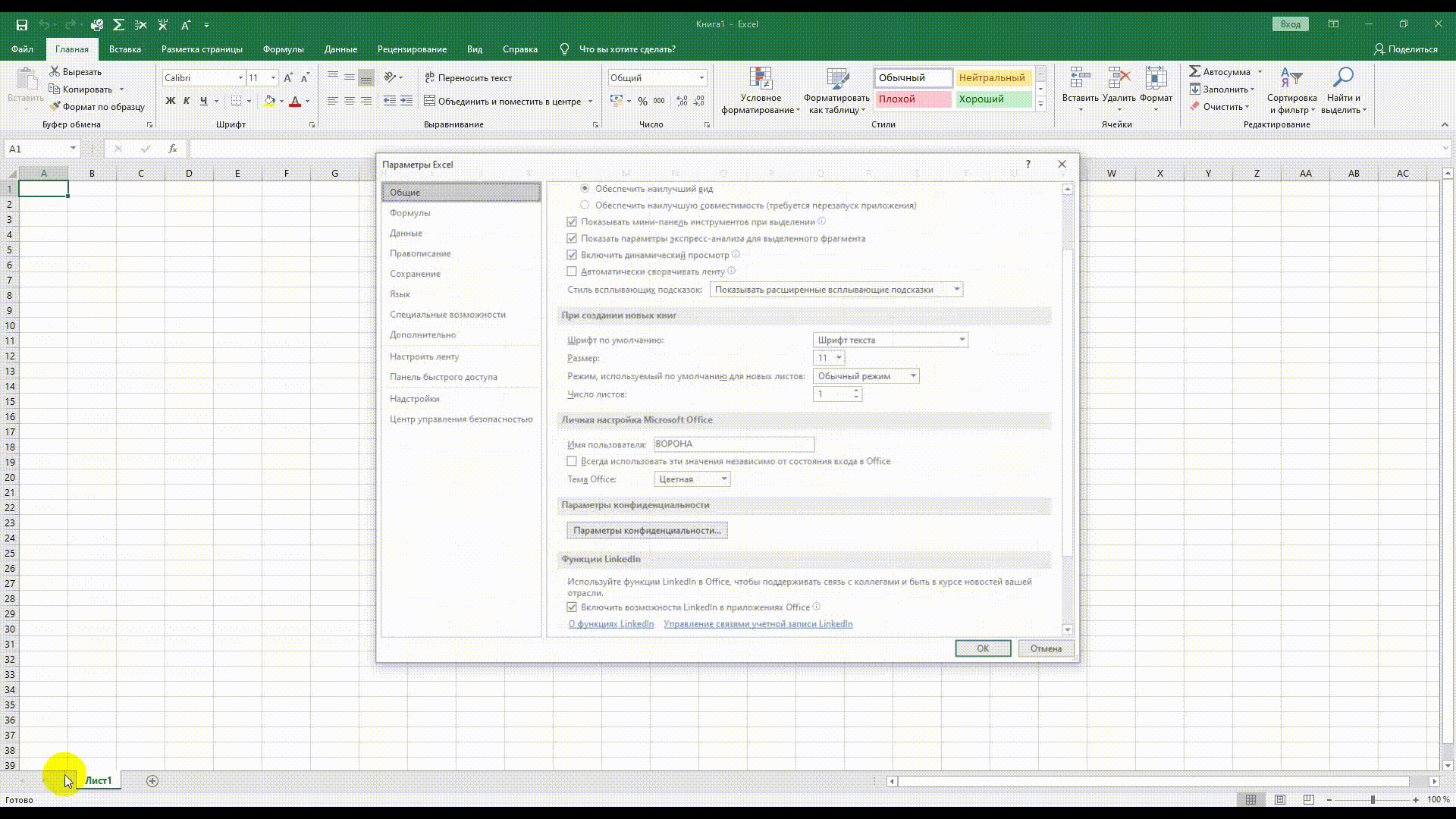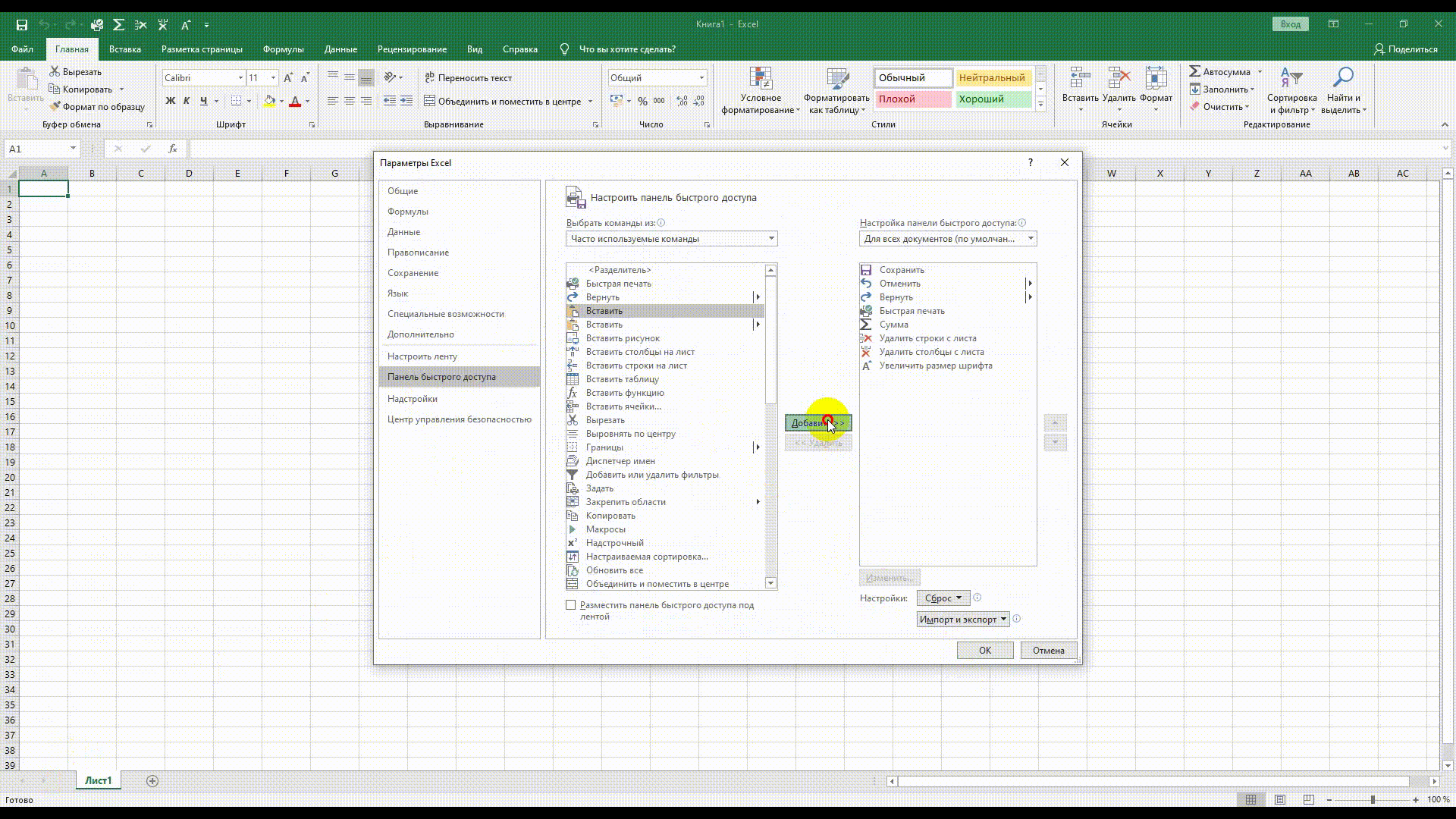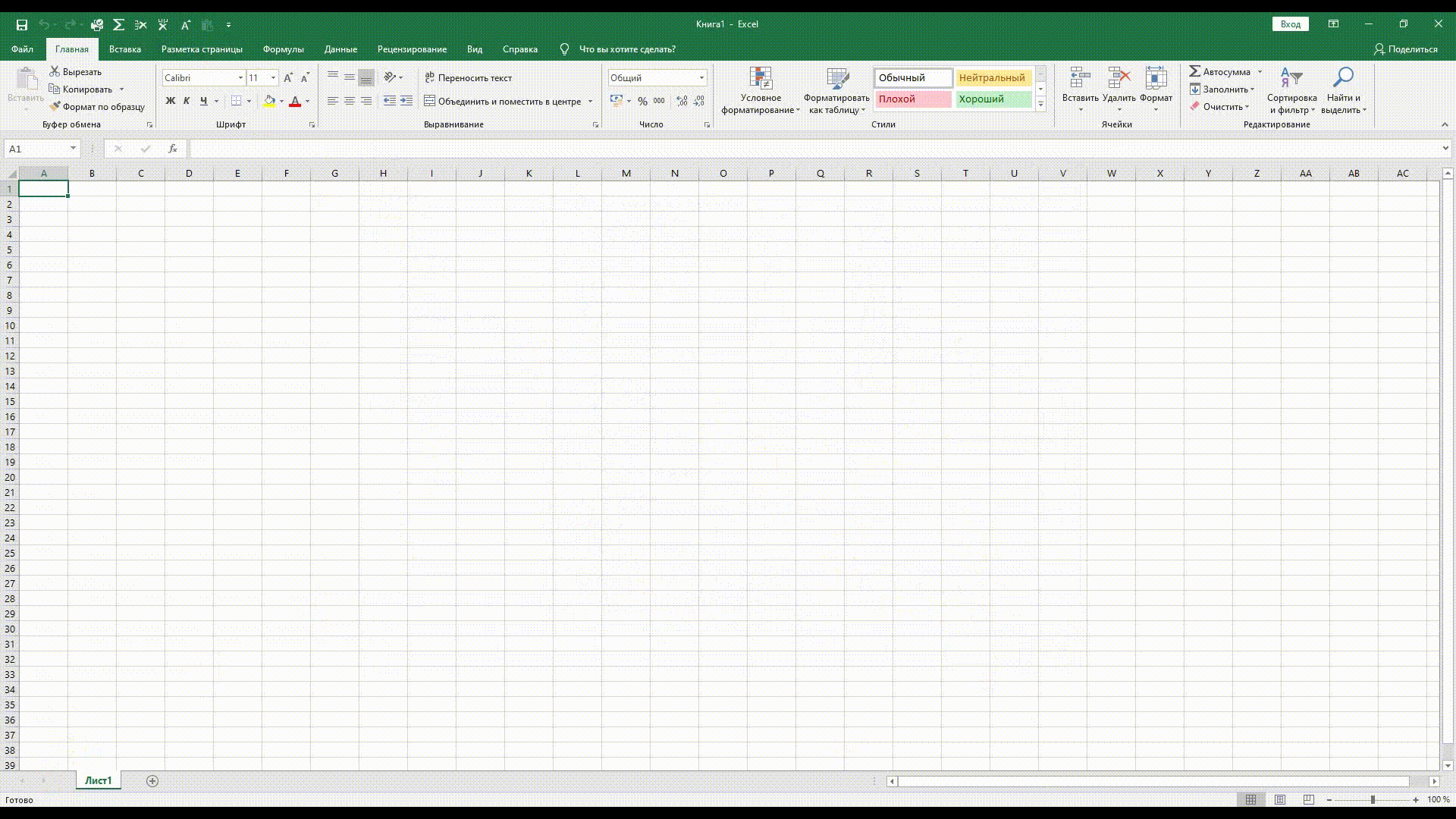
Вывести на панель можно любую функцию, вкладку или команду. При этом настройки сохраняются либо для определенных документов, либо для всех сразу.
Шаблоны для таблиц
В Excel есть встроенные шаблоны для составления типовых таблиц. В стандартной версии их больше сотни. Для удобства поиска они разделены на категории (Анализ, Бизнес, Проекты, Продажи, Годовые и т.д.). Готовых шаблонов достаточно для решения большинства задач маркетолога. Как применить шаблон:
Файл – Создать – Доступные шаблоны
Если встроенных возможностей не хватает, то дополнительные шаблоны можно скачать с сайта Microsoft или сторонних ресурсов. Многие из них находятся в открытом доступе.
Какие шаблоны использую маркетологи:
- Бюджет маркетингового плана;
- Стандартный бюджет мероприятия;
- Бюджет канального маркетинга;
- Пошаговый планировщик идей;
- План размещения публикаций на сайте или в социальных сетях;
- Месячный план контент-маркетинга;
- Ведение кампаний контекстной рекламы;
- Оценка SEO-продвижения;
- Ежемесячный отчет по метрикам.
Шаблоны универсальны – их легко адаптировать под собственные нужды. Готовые решения автоматизируют рутинные операции.

Форматирование таблиц
Однородные данные, находящиеся в строчках (например, отчет, импортированный из системы аналитики), лучше превращать в отдельную таблицу с помощью кнопки Форматировать как таблицу.
В Excel уже есть готовые стили для форматирования. В этом же меню можно создать собственный стиль в конструкторе. Чтобы задать экспресс-стиль, нужно выделить диапазон ячеек, нажать комбинацию Ctrl+T и в выпадающем меню активировать галочку Таблица с заголовками.
Форматировать данные как таблицу нужно для последующего упрощения вычислений. Форматирование дает множество способов сортировки и фильтрации. В ячейках появляются треугольники для их активации на выбор. При этом опции могут оперировать как буквами, так и цифрами.
Например, в бюджет можно добавить Строку итогов, которая будет автоматически считать итоговый бюджет (весь или по отдельным статьям). Или задать два варианта содержимого ячейки, которые задаются треугольником (например, сдал/не сдал).
Еще одна полезная кнопка – Условное форматирование. Она позволяет задать условия выделения определенных ячеек, добавить гистограммы, цветовые шкалы и различные значки. В меню есть готовые правила выделения, при необходимости можно ввести пользовательские условия.
Сводные таблицы
На практике встречаются задачи, когда приходится анализировать и сравнивать данные из нескольких таблиц и выводить результаты в одну. Или на основе одного источника создать отчеты по разным данным.
В Excel имеется готовый инструмент для анализа таблиц – Сводные таблицы. Они позволяют:
- перераспределять данные в строках и столбцах;
- добавлять анализируемые параметры;
- группировать данные;
- применять фильтры.
Например, есть таблица с годовыми расходами, разбитая по месяцам. В строчках указаны месяцы, в столбцах – статьи расходов и сумма. Нужно проанализировать, сколько было потрачено на каждую статью ежемесячно и за год. Сводная таблица может автоматически преобразовать данные в соответствующий вид. Как создать сводную таблицу:
Вставка – Сводная таблицы
В выпадающем меню необходимо указать диапазоны ячеек анализируемых таблиц и поля будущей сводной таблицы. При помощи Мастера сводных таблиц и диаграмм можно брать данные сразу из нескольких источников.
Полезные для маркетолога формулы
Excel – универсальный инструмент для работы с большими массивами данных. В нем много функций, формул и хитростей. Чтобы рассмотреть все фишки, облегчающие работу с маркетинговыми данными, понадобится целая книга. Мы разберем лишь малую часть функционала, которой специалисты пользуются чаще других.
Вертикальный просмотр (ВПР)
Находит данные в текстовой строке таблицы или диапазоне ячеек и добавляет их в другую таблицу. Ее часто используют для анализа SEO-запросов. Например, когда из большого количества ключевых фраз нужно найти самую популярную с заданным ключом.

Склеивание текста (СЦЕПИТЬ)
Объединяет текстовое содержимое ячеек из заданного диапазона. Функция полезна для самостоятельного подбора ключевых фраз. Можно указать до 255 ячеек и до 8192 символов.
Длина строки (ДЛСТР)
Вычисляет количество символов в тексте заданной ячейки. Таким образом проверяются лимиты для рекламных кампаний в Яндекс Директе или Адс и посты для некоторых социальных сетей. Так как в них действуют ограничения на количество символов в объявлениях и постах.
Выделение нужного числа знаков (ЛЕВСИМВ)
Помещает в ячейку заданное количество символов из выделенной ячейки. Данная функция помогает маркетологам понять, как будет выглядеть тайтл – заголовок страницы, выводящийся в поисковой выдаче в виде ссылки на сайт. Для этого в формулу подставляется оптимальная длина заголовка для Яндекса и Google.
Логическая функция ЕСЛИ и ее производные
Наиболее часто применяемая маркетологами логическая функция. Проверяет ячейку на соответствие заданным условиям. По результатам проверки выводится определенное сообщение. Так анализируются большие объемы данных.
Например, бюджет маркетингового канала. Достаточно задать лимит с помощью функции ЕСЛИ, а не смотреть каждую статью расходов вручную. Еще одно популярное применение функции – разбивка ключевых слов по группам.
Также часто применяются ее разновидности:
=СУММЕСЛИ – суммирует данные в ячейках при выполнении условий.
=СЧЁТЕСЛИ – вычисляет число ячеек, соответствующих условиям.
=ЕСЛИОШИБКА – проверяет значение в ячейке по указанной формуле, если значение неверное, то выводит определенное сообщение.
Преобразование строчных букв в прописные и наоборот
=СТРОЧН – заменяет все буквы строчными.
=ПРОПИСН – делает текст в ячейке прописным.
=ПРОПНАЧ – преобразует первую букву каждого слова в заглавную, остальные – в строчные.
=ЗАМЕНИТЬ(A1;1;1;ПРОПИСН(ЛЕВСИМВ(A1;1))) — преобразует только первую букву первого слова, где значение ячейки A1 меняется на нужную. Особенно это нужно когда нужно отредактировать ключевые слова из Вордстата Яндекс.
Функции для работы с текстом нужны для сбора семантического ядра или исправления скопированного текста. Без них процедуры занимает долгие часы.
Удаление дублей
При работе с большим количеством текста легко упустить повторяющиеся слова и фразы. В Excel есть функция удаления дублей для выделенного диапазона:
Данные – Удалить дубликаты
Она облегчает работу с семантикой.
Удаление лишних символов
При копировании текста из адресной строки браузера в ячейку попадает много ненужных символов. Убрать спецсимволы можно при помощи функции поиска и замены. Вызывается она комбинацией Ctrl+F на выделенном диапазоне.
Во вкладке Заменить находим опцию Найти и вводим символ, который хотим удалить. Справа от него прописываем звездочку, а поле Заменить оставляет пустым. Таким же образом удаляем и другие символы. В итоге останется чистый текст без мусора.
Дополнительные способы для удаления некоторых знаков:
ПЕЧСИМВ – убирает из ячейки все непечатаемые знаки.
СЖПРОБЕЛЫ – удаляет лишние пробелы.
Заключение
Excel – мощнейший аналитический инструмент маркетолога. Он упрощает работу с большими массивами данных, помогает в составлении отчетов, ускоряет подготовку рекламных кампаний, облегчает подбор ключевых фраз. Некоторые его функции сложны в освоении. Но если научиться правильно их применять, они сэкономят кучу времени.
Нужно превратить трафик в реальные заявки? Подняться в выдаче? Исправить ошибки на сайте? Создать продающий ресурс? Внедрить Битрикс24? Привести клиентов из интернета? Позвоните или напишите нам. Специалисты Белой Вороны попадут в точку.
Если Вам понравилась статья — ставим лайк и делимся ей в социальных сетях. Хотите получать больше полезных статей? Подпишитесь на рассылку. Раз в неделю пишем коротко про интернет-маркетинг.
Статьи и публикации 
Исследования в маркетинге
Авторы: Элвин С. Бернс, Рональд Ф. Буш
«Основы маркетинговых исследований с использованием Microsoft Office Excel»,
Издательство «Вильямс»
По материалам PC Magazine
Преимущество вторичных данных заключается в том, что они часто позволяют лучше понимать отчеты, содержащие первичные данные. Роберт Д. Аарон (Robert D. Aaron) — президент и соучредитель корпорации Aaron/Smith Associates, Inc., штаб-квартира которой находится в Атланте. Мистер Аарон утверждает, что клиенты часто просят специалистов по маркетинговым исследованиям сделать нечто большее, чем простой обзор первичных результатов опросов или заседаний фокус-групп. Следовательно, кроме разработки анкет, сбора данных и количественного анализа специалисты по маркетинговым исследованиям должны учитывать дополнительную информацию, полученную из внешних источников. Вторичные данные позволяют повысить ценность отчетов о маркетинговых исследованиях.
Аарон утверждает, что по мере распространения оперативных баз данных проводить поиск вторичных данных стало проще. Сочетание первичных и вторичных данных позволяет исследователям рынка повысить качество своей работы. Аарон считает, что, правильно выполнив поиск вторичных данных, исследователи смогут намного точнее решить поставленную задачу. По мнению Аарона, для этого необходимо сделать следующее.
- В начале каждого проекта следует выполнить поиск вторичных данных. Многие исследователи, контактируя с новым клиентом, должны изучить положение в отрасли и существующие проблемы. Освоив новую информацию, исследователь сможет выработать свою собственную точку зрения и на равных общаться с клиентом.
- Исследование вторичных данных позволяет правильно сформулировать цели и задачи исследования. Вопросы, рассмотренные в опубликованных работах, часто повторяются в новых исследованиях.
- Первичные данные необходимо исследовать в контексте. Результаты, полученные в ходе маркетингового исследования, часто повторяют результаты, ранее опубликованные в статьях и пресс-релизах. Необходимо сравнить вторичные данные, изложенные в научной литературе, с первичными данными, собранными в ходе исследования.
Вторичная информация повышает ценность отчета, поскольку в этом случае результаты излагаются в контексте общего положения в отрасли. Даже если эта информация уже была известна клиенту, иногда полезно подытожить разрозненные данные. Это позволяет найти точки соприкосновения и вызвать доверие к отчету, утверждает Аарон.
Чему должен научиться студент
- Понимать разницу между первичными и вторичными данными.
- Применять вторичные данные и проводить их классификацию.
- Описывать внутренние и внешние базы данных и их структуру.
- Знать преимущества и недостатки вторичных данных.
- Оценивать вторичные данные.
- Находить вторичные данные, владеть стратегиями поиска в базах данных.
- Знать содержание главных источников вторичных данных, принадлежащих правительству и частным организациям.
- Обоснование целесообразности маркетингового исследования.
- Постановка задачи.
- Определение целей.
- Разработка плана.
- Идентификация вида информации и ее источников.
- Выбор методов сбора информации.
- Выбор способов представления собранной информации.
- Определение содержания и размера выборки.
- Сбор данных.
- Анализ данных.
- Подготовка и презентация заключительного отчета.
Итак, специалист по маркетинговым исследованиям Роберт Д. Аарон подчеркнул важность вторичной информации и оперативных баз данных. С его точки зрения, даже если проект предусматривает сбор первичной информации, сначала необходимо проанализировать вторичные данные. Он также подчеркнул, что оперативные базы данных значительно облегчают поиск нужной информации. В этой главе объясняется разница между первичными и вторичными данными, иллюстрируется полезность вторичной информации, перечисляются принципы ее классификации, указываются ее преимущества и недостатки. Кроме того, в ней перечислены основные источники вторичной информации и стратегии ее эффективного поиска. В заключение перечисляются некоторые правительственные и частные источники вторичных данных, полезных для маркетинговых исследований.
Вторичные данные
Сопоставление первичных и вторичных данных
Как показано в главе 3, данные, необходимые для проведения маркетингового исследования, можно разделить на две группы: первичные и вторичные. Первичные данные (primary data) — это информация, собранная исследователем специально для конкретного проекта.
Первичные данные — это информация, собранная исследователем специально для конкретного проекта.
Вторичные данные (secondary data) — это информация, собранная кем-то другим и для иных целей. Регистрируя финансовые операции и деловые операции, коммерческие фирмы, министерства и организации создают вторичные данные. Когда потребители заполняют гарантийные талоны или регистрируют свои автомобили, яхты, компьютерные программы, они тоже создают вторичную информацию. Эти данные используются другими исследователями как вспомогательные. Эволюция Internet открыла пользователям простой и легкий доступ ко вторичным данным.
Доступ ко вторичной информации через Internet представляет собой разновидность интерактивных исследований. Его объем и значение для маркетинга постоянно возрастает.
Начиная с середины 1980-х годов, практически вся документация создавалась, редактировалась, хранилась и предоставлялась пользователям с помощью компьютеров. В течение нескольких лет фирмы организовывали специализированные сервисные центры, предназначенные для распространения информации среди клиентов. Сегодня многие из этих фирм предоставляют свои услуги через Internet. Несмотря на то что некоторые из этих услуг являются платными, в Internet существует огромный массив бесплатной информации. Со временем, после появления сети Internet2, эти данные покажутся просто примитивными. Некоторые эксперты утверждают, что поток информации, существующий в современном варианте Internet, по сравнению с Internet2 напоминает тропинку, соперничающую с многополосным шоссе! Доступко вторичной информации через Internet представляет собой разновидность интерактивных исследований. Его объем и значение для маркетинга постоянно возрастает.
Применение вторичных данных
Вторичные данные очень широко применяются в маркетинговых исследованиях. Редкий проект может обойтись без сбора и анализа вторичной информации. Диапазон применения вторичных данных простирается от предсказания изменений в образе жизни до весьма специальных исследований, касающихся размещения автомобильной стоянки. Корпорация Decision Analyst, Inc., проводящая маркетинговые исследования, создала Web-сайт, целиком посвященный вторичным данным. На этом сайте описываются разнообразные исследования, в частности, предсказание экономических тенденций, организация экономической разведки, оценка международной ситуации, изучение общественного мнения, анализ исторических событий и многие другие.
Вторичные данные очень широко применяются в маркетинговых исследованиях. Редкий проект может обойтись без сбора и анализа вторичной информации. Некоторые проекты вообще сводятся только к анализу вторичных данных.
Специалистов по маркетингу всегда интересует демографическая информация, позволяющая прогнозировать размер рынка на осваиваемой территории. Исследователь может применять вторичные данные для того, чтобы определить количество населения и темпы его роста в конкретном географическом регионе. Министерства нуждаются во вторичных данных, чтобы принимать правильные решения. Например, в министерстве образования должны знать количество детей в возрасте пяти лет, которые в следующем году пойдут в школу. Министерство здравоохранения должно знать, сколько пожилых людей обратится в страховые компании в течение следующих десяти лет. Иногда вторичные данные используются для оценки состояния рынка. Например, поскольку величина налога на галлон топлива открыта для публики, специалист по топливному рынку может легко определить, сколько бензина потребляется в округе. Специалистам по маркетингу доступно множество статей, написанных практически на любые темы. Они позволяют даже новичкам глубже понять существо проблемы. Существует большое количество вторичных данных, характеризующих образ жизни и привычки разных групп населения. Поскольку члены однородных демографических групп характеризуются одинаковыми привычками и вкусами, они внимательно изучаются специалистами по маркетингу. Наиболее важной демографической группой является поколение «бэбибумеров», т.е. людей, родившихся между 1946 и 1964 гг. Как только люди из этого поколения достигнут среднего и пожилого возраста, на передний план выдвинется поколение X, которое также вызовет интерес у специалистов по маркетингу. Применение вторичных демографических данных продемонстрировано в прикладном маркетинговом исследовании 5.1.
Прикладное маркетинговое исследование 5.1
Вы родились между 1977 и 1994 гг.? Значит, вы из поколения Y!
Демографическая информация необходима во многих маркетинговых исследованиях. Слово «демографический» происходит от греческого слова demos — народ. Как правило, в маркетинговых исследованиях изучаются размер населения, его плотность, темпы роста, доход, этнический фон, обеспеченность жильем, уровень розничных продаж и многие другие факторы. Демографический анализ возрастных групп позволяет лучше понять закономерности развития рынка и повысить точность его прогнозирования. Сегодня мы знаем, сколько шестнадцатилетних подростков будет в США в 2021! В течение многих десятилетий специалисты по маркетингу следили за поколением «бэбибумеров», т.е. людьми, родившимися между 1946 и 1964 гг. Они составляли большую часть населения, и их потребности определяли развитие рынка в течение многих лет. В 1950-х годах для обучения «бумеров» было построено большое количество школ. В результате резко возросли объемы продаж учебников, школьной формы и игрушек. Как только «бумеры» достигли подросткового возраста, рок-н-ролл вытеснил со сцены Фрэнка Синатру (Frank Sinatra), Перри Комо (Perry Como) и Дина Мартина (Dean Martin). Звукозаписывающая индустрия обнаружила громадный рынок «бумеров» в возрасте от 12 до 18 лет, музыкальные вкусы которых противоречили вкусам их родителей, предпочитающих джаз и эстраду. Элвис Пресли (Elvis Presley) лучше соответствовал требованиям нового рынка, чем кто-либо еще. Действительно, если бы не потребности рынка, Элвис до сих пор водил грузовики в Мемфисе. Вырастая, «бумеры» требовали создания беспрецедентного, но вполне предсказуемого количества колледжей и университетов, рабочих мест, жилья, курортов, а затем лекарств, товаров и услуг для пожилых людей. Настоящее время сопровождается новыми демографическими требованиями. Поколение Y по величине практически совпадает с поколением «бэбибумеров» и оказывает такое же влияние на деловую активность страны. Несмотря на разногласия демографов о величине этого поколения, большинство считает, что поколение Y включает в себя около 72 млн. американцев, родившихся между 1977 и 1994 гг. По оценкам, величина годового совокупного дохода этой группы населения составляет 187 млрд. долл. Однако, в отличие от поколения «буме-ров», поколение Y характеризуется непредсказуемым поведением и не поддается точному прогнозированию. Большое количество людей, достигших 20 лет, по-прежнему проживает с родителями. Они вытесняют традиционные средства массовой информации, предпочитая видеоигры, DVD и Web-сайты. Поскольку поколение Y образует настолько большую часть населения и оказывает влияние на более молодых людей, оно вызывает острый интерес у специалистов по маркетинговым исследованиям. В частности, компания Honda создала свою модель Element именно для этого поколения потребителей, называя свой автомобиль «общагой на колесах». То же самое проделала компания Chrysler со своим автомобилем PT Cruiser. Однако это не произвело никакого впечатления на поколение Y. Обе модели нашли своего потребителя, но только в группе более пожилых людей. Однако поколение Y вполне предсказуемо, когда речь идет о технологии. Они являются ярыми сторонниками любых новшеств. Производители сотовых телефонов внимательно следят за вкусами представителей поколения Y, чтобы уловить современные тенденции этого сектора рынка. Сотовые телефоны, снабженные видеокамерами и плейерами, уже появились на рынке. Компания Jupiter Research сообщила, что молодые люди в возрасте от 18 до 24 лет около 10 часов в неделю проводят в Internet, 10 часов смотрят телевизор и 5 часов слушают радио. Кроме того, они проводят много времени, пересылая электронные сообщения, забавляясь видеоиграми и обмениваясь музыкальными файлами.
Представители поколения Y за один день тем или иным образом получают до 3 000 рекламных сообщений (таким образом, на протяжении их жизни на них обрушится около 23 миллионов рекламных роликов и объявлений). Это вырабатывает у них стойкий иммунитет к рекламе. Один специалист по рекламе сообщил, что фокус-группы, состоящие из людей в возрасте 21 года, могут сами подсказать рекламную стратегию. Иными словами, они видят правильный способ рекламирования товаров. В отличие от поколения «бэбибумеров», они просматривают рекламные объявления для развлечения, а не в поисках информации. Чтобы привлечь их внимание, рекламодатели должны делать рекламу более изощренной, используя распространение устной информации и скрытый маркетинг.
В настоящее время поколение Y считается наиболее влиятельной силой. Они влияют не только на своих более юных родственников, но и, к удивлению многих, на своих родителей. По сообщениям телеканала MTV, например, родители часто смотрят шоу «Семейка Оззи Осборна» («Ozzi Osbourne and his family») вместе со своими детьми из поколения Y! Несомненно, поколение Y еще долгое время будет в центре внимания специалистов по маркетинговым исследованиям.
Источник: цитируется по статье Weiss, M. J. (2003, September 1). To be or not to be. American Demographics. Распространено компанией Lexis-Nexis 30 октября 2003 г.
Классификация вторичных данных
Поскольку существует огромное количество вторичных данных, специалист по маркетинговым исследованиям должен уметь ими оперировать. Следовательно, специалист по маркетинговым исследованиям должен уметь классифицировать вторичные данные, понимать их преимущества и недостатки, а затем оценивать их смысл.
Внутренние вторичные данные
Вторичные данные подразделяются на внутренние и внешние.
Внутренние вторичные данные — это данные, собранные внутри фирмы. К таким данным относятся записи о продажах, заказы и накладные. Очевидно, что квалифицированный специалист по маркетинговым исследованиям всегда способен определить доступную внутреннюю информацию. Напомним, что в главе 1 был описан анализ внутренних данных, представляющий собой часть подсистемы внутренних отчетов, входящей в маркетинговую информационную систему (МИС). В настоящее время основным источником внутренней информации являются базы данных, содержащие информацию о потребителях, продажах, поставщиках и других субъектах бизнеса, с которыми взаимодействует фирма. Котлер называет прямым маркетингом (database marketing) процесс создания, поддержки и использования внутренних баз данных о потребителях, товарах, поставщиках, посредниках с целью осуществления контактов, сделок и договоров. За последние годы применение внутренних баз данных резко возросло.
Внутренние базы данных
Базой данных называется коллекция данных, описывающих определенные свойства объектов. Базы данных состоят из записей, а записи — из полей.
Прежде чем перейти к обсуждению внутренних и внешних данных, следует понять, что базой данных (databases) называется коллекция данных, описывающих определенные свойства объектов. Единица информации в базе данных называется записью (record). Запись может содержать данные о клиенте, поставщике, конкуренте, товаре, инвентарной единице и т.п. Записи состоят из полей (fields). Например, в базе данных о клиентах каждая запись соответствует одному клиенту. Как правило, поля записей содержат фамилию, адрес, номер телефона, адрес электронной почты, вид купленного товара, дату покупки, место покупки, сведения о гарантиях и другую информацию, которую компания сочтет важной. Большинство баз данных хранятся в компьютерах, позволяющих редактировать, сортировать и анализировать большие объемы информации, хотя до сих пор встречаются компании, ведущие базы данных по-старому.
Внутренние базы данных (internal databases) содержат информацию, собранную компанией в ходе обычной деловой деятельности. Менеджеры по маркетингу, как правило, ведут внутренние базы данных о клиентах. Однако базы данных могут содержать данные по любой теме, например, о товарах, продавцах, единицах хранения и поставщиках. Компании собирают информацию о своих клиентах, когда получают заказ на товар или услугу. В этих ситуациях фирма записывает фамилию, адрес, номер телефона, номер факса, адрес электронной почты, номер кредитной карточки, номер счета в банке и т.п. В совокупности с информацией о проданных в прошлом товарах, предоставляемой правительством и другими коммерческими источниками, компании получают довольно много данных о своих клиентах. Фирмы применяют внутренние базы данных для организации прямого маркетинга и укрепления связей с клиентами (customer relationship management — CRM).Внутренние базы данных могут быть довольно большими и содержать огромное количество числовых данных. Интеллектуальная разведка (data mining) — это название программ, помогающих менеджерам извлекать осмысленную информацию из беспорядочного, на первый взгляд, набора данных, содержащихся в базах данных. Однако даже простые базы данных в малом бизнесе могут оказаться неоценимыми. С помощью баз данных менеджеры узнают, какие товары пользуются спросом, создают инвентарные ведомости и классифицируют клиентов. В сочетании с географическими информационными системами (geographic information systems — GIS) базы данных позволяют создавать карты районов, в которых живут наиболее перспективные клиенты. Внутренние базы данных, наполненные информацией, собранной в ходе обычной деловой деятельности, имеют неоценимое значение для менеджеров. Географические информационные системы обсуждаются в следующей главе.
Информация, содержащаяся во внутренних базах данных, может порождать этические проблемы.
Внутренние базы данных, наполненные информацией, собранной в ходе обычной деловой деятельности, имеют неоценимое значение для менеджеров.
Информация, содержащаяся во внутренних базах данных, может порождать этические проблемы. Имеет ли право ли компания, обслуживающая кредитную карточку клиента, сообщать потенциальным покупателям, какие товары он оплатил в прошлом? Имеет ли право Internet-провайдер наблюдать, какие Web-сайты посещает его клиент? С течением времени клиенты стали все больше заботиться о сохранении неприкосновенности своей частной жизни. В ответ компании стали принимать правила, гарантирующие тайну клиента.
Внешние вторичные данные. Публикации
Публикации — это информация, изложенная в открытых изданиях. Они хранятся в библиотеках или распространяются торговыми ассоциациями, профессиональными организациями и компаниями.
Внешние вторичные данные (external secondary data) — это информация, полученная за пределами фирмы. Существует три источника внешних вторичных данных: 1) публикации;!) синдицированные данные;3) базы данных. Публикации (published sources) — это информация, изложенная в открытых изданиях. Они хранятся в библиотеках или распространяются торговыми ассоциациями, профессиональными организациями и компаниями. Публикации бывают разными: печатными и электронными. Например, в последнее время широкую популярность завоевали электронные журналы. Информацию для публикаций поставляет правительство (например, Бюро переписи населения), некоммерческие организации (торговые палаты, колледжи и университеты), торговые, профессиональные ассоциации (CASRO, AMA, IMRO, MRA) и коммерческие фирмы (например, журнал Sales & Marketing Management, издательства Prentice-Hall, Inc. и McGraw-Hill, а также исследовательские компании). Многие фирмы, специализирующиеся на маркетинговых исследованиях, распространяют вторичную информацию в виде книг, бюллетеней и специальных отчетов.
Для успешного поиска информации необходимо хорошо понимать предназначение публикаций разного вида.
Нарастающий поток публикаций значительно усложняет процесс поиска нужной информации. Для успешного решения этой проблемы необходимо хорошо понимать предназначение публикаций разного вида. Классификация публикаций приведена в табл. 5.1.
Таблица 5.1. Классификация маркетинговых исследований
| 1. Справочные руководства. Предназначение: содержат ссылки на другие источники и рекомендуемую литературу. Справочные руководства указывают, где искать информацию. Пример: Encyclopedia of Business Information Sources. Detroit: Galegroup, 1970-2001. |
| 2. Реферативные журналы. Предназначение: содержат заглавия и аннотации статей, ключевые слова и т.п. Реферативные журналы помогают найти периодическое издание, необходимое для исследования. Пример: ABI/Inform, Ann Arbor, MI: Proquest, 1971-present. |
| 3. Библиографические справочники. Предназначение: содержат списки источников — книг, журналов и т.п. — по интересующей теме. Библиографические справочники позволяют найти источники информации по заданной теме. Пример: Recreation and Entertainment Industries, an Information Source Book. lefferson, NC: Macfarland, 2000. |
| 4. Альманахи, справочники, учебники. Предназначение: содержат публикации, которые должны постоянно быть «под рукой». Пример: Wall Street Journal Almanac. New York: Ballantine Books, Annual. |
| 5. Словари Предназначение: содержат определения терминов по указанной теме. Пример: Concise Dictionary of Business Management. New York: Routledge, 1999. |
| 6. Энциклопедии. Предназначение: содержат тематические статьи, расположенные в алфавитном порядке. Пример: Encyclopedia of’Busine$$ and Finance. New York: Macmillan, 2001. |
| 7. Каталоги. Предназначение: содержат информацию о компаниях, людях, товарах, организациях и т. п. Пример: Career Guide: Dun’s Employment Opportunities Directory.Parsippany, NJ: Dun’s Marketing Services Annual. |
| 8. Статистические справочники. Предназначение: содержат числовую информацию, как правило, в виде таблиц и диаграмм. Пример: Handbook of U. S. Labor Statistics. Lanham, MD: Bernan Press, Annual. |
| 9. Биографические источники. Предназначение: содержат информацию о людях. Пример: D&B Reference book of Corporate Management. Bethlehem, PA: Dun & Bradstreet, 2001. |
| 10. Юридические справочники. Предназначение: содержат информацию о законах, нормативных актах и прецедентах. Пример: United States Code. Washington, DC: Government Printing Office. |
В настоящее время многие библиотеки переводят свои книги в электронный формат. Это позволяет исследователям быстро находить необходимую информацию. Большинство электронных библиотек хранит информацию в виде каталогов и указателей. Каталог (catalog) представляет собой список книг, хранящихся в библиотеке. (Иногда в каталоге указываются периодические издания, которые выписывает библиотека.) Таким образом, каталоги полезны при поиске книг по теме, названию, фамилии автора, дате издания или названию издательства. Указатель (index) — это запись, составленная на основе периодических изданий и содержащая в своих полях фамилию автора, название публикации, ключевые слова, дату опубликования, название издания и т.п. Иногда указатели включают полное содержание журналов (такие указатели называются полнотекстовыми (full-text)). Подобные указатели, как правило, создаются не библиотеками, а специализированными компаниями. Мы будем обсуждать их, когда перейдем к изучению оперативных баз данных.
Синдицированные данные
Синдицированные данные (syndicated services data) предоставляются фирмами, собирающими данные в стандартном формате и распространяющими их среди подписчиков. Такие данные, как правило, являются узкоспециализированными и недоступны для широкой публики.
В разделе «Interactive Leaning», расположенном в конце главы, описывается указатель рейтингов телепрограмм Television Rating Index, составляемый компанией Nielsen Media Research. Из него вы узнаете, какие телевизионные программы являются самыми популярными.
Поставщики синдицированных данных продают информацию многочисленным подписчикам, снижая цены до разумных пределов. Примерами такой информации являются списки слушателей радиостанции Arbitron, указатель рейтингов телепрограмм Television Rating Index, составляемый компанией Nielsen Media Research, и отчеты InfoScan о продажах товаров в розничной сети магазинов, создаваемые компанией Information Resources. Эти компании поставляют своим подписчикам внешние вторичные данные. Деятельность фирм, предоставляющих синдицированные данные, обсуждается в главе 6.
Внешние базы данных
Внешние базы данных (external databases) создаются сторонними компаниями. Их также можно использовать в качестве источника вторичной информации.
Внешние базы данных (external databases) создаются посторонними компаниями. Их также можно использовать в качестве источника вторичной информации. Некоторые из этих баз данных существуют в печатном виде, однако в последние годы они преимущественно являются электронными. Оперативные базы данных (online information databases) — это источники вторичной информации, допускающие применение поисковых серверов. Некоторые из них являются бесплатными, однако большинство оперативных баз данных носят коммерческий характер и доступны только для платных подписчиков (на основе пароля или идентификационного номера). Количество таких баз данных резко возрастает, начиная с 1980-х годов.
Оперативные базы данных — это источники вторичной информации, допускающие применение поисковых серверов. Такие услуги, в частности, предоставляют компании Factiva, Gale Group, Proquest, First Search, Lex-isNexis и Dialog.
На протяжении 1990-х и в начале 2000-х годов произошло слияние большого количества фирм, предоставляющих доступ к оперативным базам данных. Таких компаний стало меньше, но их размер увеличился. В настоящее время пользователям стали доступны миллиарды записей. Базы данных часто создаются вместе со специализированным программным обеспечением. Такое сочетание иногда называется накопителем информации (aggregator) или банком данных (databank). Банки данных предоставляют своим пользователям доступ к большому количеству указателей, каталогов, статистических файлов и текстов статей. Такие услуги, в частности, предоставляют компании Factiva, Gale Group, Pro-quest, First Search, LexisNexis и Dialog. Большую долю банков данных образуют коммерческие базы данных.
Преимущества вторичных данных
Вторичные данные можно быстро найти
Существует пять преимуществ вторичных данных. Во-первых, вторичные данные, в отличие от первичных, можно быстро найти. Достаточно зайти в Internet и, не тратя особых средств, найти все, что необходимо.
5 преимуществ вторичных данных:
- их можно быстро найти;
- для их поиска не требуется много средств;
- они, как правило, доступны;
- они дополняют наборы первичных данных;
- с их помощью иногда можно сразу решить поставленную задачу.
Во-вторых, поиск вторичных данных намного дешевле, чем сбор первичной информации. Несмотря на то что сбор вторичной информации требует определенных затрат, их размер намного меньше, чем стоимость поиска первичной информации. Первичные данные редко удается собрать, не затратив как минимум несколько тысяч долларов. В зависимости от цели исследования эти затраты могут достигать сотен тысяч и даже миллионов долларов. Даже приобретение вторичных данных у коммерческих поставщиков обходится гораздо дешевле, чем сбор первичных данных.
Вторичные данные, как правило, доступны
Третье преимущество вторичных данных заключается в том, что они, как правило, доступны. Независимо от поставленной задачи, кто-то когда-то уже делал что-то подобное. Доступность — это одна из причин, по которой многие специалисты считают, что роль вторичных данных в маркетинговых исследованиях будет со временем возрастать. Развитие компьютерных технологий упрощает поиск и открывает пользователям доступ к миллиардам записей.
Вторичные данные дополняют первичные
В сценарии, описанном в начале главы, вторичные данные дополняли первичные. Применение вторичных данных не отменяет необходимости собирать первичную информацию. Практически всегда главной задачей исследователя является сбор первичной информации, а поиск вторичных данных лишь облегчает ее решение. Вторичные данные позволяют исследователю лучше ознакомиться с положением дел в отрасли, в частности, понять основные тенденции, узнать о главных конкурентах и выяснить насущные проблемы. Поиск вторичных данных поможет уточнить понятия и термины, полезные для проведения первичного исследования. Например, представим себе, что руководство банка наняло маркетинговую компанию, чтобы в сотрудничестве с ней провести опрос клиентов и выяснить, какой имидж сформировался у банка. В этом случае анализ вторичной информации помог идентифицировать составные слагаемые имиджа. Кроме того, после просмотра вторичной информации исследователи выделили три группы клиентов: розничные торговцы, коммерческие компании и банки-корреспонденты. Когда исследователи сообщили об этом руководству банка, первоначальные цели исследования были уточнены: теперь необходимо было выяснить имидж банка в каждой из групп клиентов.
Вторичные данные помогают сразу решить задачу
Вторичные данные ценны не только тем, что их легко собирать, не тратя больших финансовых средств. Иногда они позволяют сразу достичь цели исследования. Например, предположим, что менеджер по маркетингу сети супермаркетов желает разместить телевизионную рекламу на 12 телевизионных каналах, ориентированных на потенциальных покупателей. В результате беглого анализа в распоряжении исследователей оказались данные о влиянии телевизионной рекламы на продажи продуктов питания. Используя эти данные, менеджер может оптимально распределить средства и сразу решить поставленную задачу.
Недостатки вторичных данных
Несмотря на очевидные преимущества вторичных данных, у них есть пять недостатков: несравнимые объекты исследования, несовпадение единиц измерения, несогласованность классификации, устаревание данных и недостоверность. Эти проблемы возникают потому, что вторичные данные собираются не для конкретного исследования, а для других целей. Таким образом, исследователь должен сначала определить границы применимости вторичной информации для решения поставленной задачи. В следующих подразделах мы обсудим лишь первые четыре проблемы, а оценка достоверности вторичных данных будет обсуждаться в следующем разделе.
Несравнимые объекты исследования
Вторичные данные относятся к определенным объектам, например, округу, городу, штату, району и т.п. Их полезность для конкретного проекта зависит от сопоставимости объектов исследования.
Вторичные данные относятся к определенным объектам, например, округу, городу, штату, району и т.п. Их полезность для конкретного проекта зависит от сопоставимости объектов исследования. Например, исследователь, желающий оценить потенциал рынка, может удовлетвориться данными, относящимися к городу. Многие вторичные данные относятся именно к таким объектам. А что если исследователя интересует район, границы которого проходят в двух милях от улицы? В этом случае данные городского уровня не подходят для решения задачи. Предположим, что другой исследователь желает получить демографическую информацию в зависимости от номера почтового отделения, чтобы провести прямой маркетинг. В этом случае данные о городе снова окажутся бесполезными. Несмотря на то что проблема, связанная с несопоставимостью объектов исследования, действительно существует, в настоящее время обилие вторичных данных позволяет смягчить ее последствия. Например, современным исследователям доступны даже данные, характеризующие районы городов. Кроме того, как показано в следующем разделе, географические информационные исследования предоставляют специалистам по маркетингу доступ к данным любого уровня. В частности, именно такие системы позволяют исследователям решать задачи, связанные с изучением небольших районов. К сожалению, иногда необходимые вторичные данные относятся к неподходящим объектам.
Несовпадение единиц измерения
Иногда вторичные данные измеряются в несопоставимых единицах. Например, доход можно измерить в расчете на душу населения, а можно — на отдельную семью.
Иногда вторичные данные измеряются в несопоставимых единицах. Например, при анализе рынков специалисты по маркетинговым исследованиям обычно интересуются уровнем доходов. Как правило, в исследованиях измеряются разные показатели: общий доход, доход после вычета налогов, семейный доход и доход на душу населения. Кроме того, рассмотрим проект, в котором необходимо установить зависимость потенциала бизнеса от площади магазина. К сожалению, вторичные данные характеризуют потенциал бизнеса через объем продаж, количество сотрудников, уровень прибыли и т.д. Большинство данных в США измеряется в американской системе величин (футах, фунтах и т.д.), в то время как практически весь остальной мир перешел на метрическую систему мер (метры, килограммы и т.д.). С течением времени США постепенно тоже переходят на метрическую систему.
Несогласованность классификации
Вторичные данные часто разбивают на категории, подсчитывая частоты в каждом классе. Например, представим себе, что отчет «Исследование покупательской способности» содержит результаты измерения покупательной способности (effective buying income — EBI) в трех разных классах. В первом классе подсчитывается процент семей, доход которых колеблется от 20 до 34 999 долл., а в последнем классе — более 50 000 долл. В большинстве случаев этой классификации вполне достаточно. Однако сомнительно, что корпорация Beneteau, Inc., производитель яхт в Южной Каролине, сможет воспользоваться этими данными. Поскольку покупательная способность среднестатистического клиента этой компании превышает 75 000 долларов, вторичные данные оказываются бесполезными. Что делать исследователю в этой ситуации? Как правило, кто ищет, тот находит. Например, компания Beneteau может получить вторичные данные из справочника Demographics USA. В этом справочнике приведены данные о клиентах, покупательная способность которых превышает 150 000 долл.Вторичные данные часто разбивают на категории, подсчитывая частоты в каждом классе. Иногда эта классификация несогласуется с конкретным проектом.
Устаревание данных
Иногда исследователь обнаруживает правильную, но устаревшую информацию. В таких ситуациях исследователь должен самостоятельно решить, следует ли использовать устаревшие вторичные данные в своем проекте.
Иногда исследователь обнаруживает информацию, которая хотя и оценена в соответствующих единицах измерения, и правильно классифицирована, но уже устарела. Некоторые вторичные данные публикуются только один раз. Однако, даже если вторичные данные публикуются регулярно, после их последней публикации может пройти слишком много времени. В таких ситуациях исследователь должен самостоятельно решить, следует ли использовать устаревшие вторичные данные в своем проекте.
Оценка вторичных данных
Надеемся, что читатель уже убедился, что не все написанное на бумаге — правда. Для того чтобы правильно применять вторичные данные, необходимо критически оценивать информацию, необходимую для принятия решения. Особенно осторожно следует относиться к данным, опубликованным в Internet, поскольку многие Web-сайты не придерживаются строгих стандартов. Для того чтобы правильно оценить вторичные данные, необходимо ответить на пять вопросов.
- Какова цель исследования?
- Кто собирал информацию?
- Какая информация была собрана?
- Как получена информация?
- Как полученные данные согласуются с другой информацией?
Обсудим каждый из этих вопросов.
Какова цель исследования?
Исследования проводятся с определенной целью. К сожалению, иногда их проводят для того, чтобы подтвердить заранее установленную точку зрения или защитить чьи-то интересы. Много лет назад торговые палаты публиковали данные, подтверждавшие рост количества их членов. Это делалось специально для привлечения новых коммерсантов. Однако через несколько лет оказалось, что данные торговых палат недостоверны. В настоящее время эта традиция исчезла, и торговые палаты стали публиковать надежные и корректные данные. Мораль очевидна: исследователь должен критически относиться к публикуемым данным и уметь распознавать тенденциозную информацию. Рассмотрим пример, относящийся к производству одноразовых подгузников. Эта отрасль производства возникла в 1960-х годах. Защитников окружающей среды встревожил прогноз резкого роста потребления этих товаров — ведь их распад продолжается 50 лет. В прогнозе утверждалось, что во второй половине 1980-х годов количество покупателей одноразовых подгузников удвоится. Некоторые штаты ввели дополнительные запрещения, повышенные налоги и даже предупреждающие метки на одноразовые подгузники. Затем специалисты провели «исследование», в котором оценивалось влияние этих товаров на окружающую среду по сравнению с обычными пеленками. Это «исследование» показало, что обычные подгузники представляют еще большую опасность! Как только результаты этих исследований стали известны законодателям, возражения против одноразовых подгузников прекратились. Кто же провел эти «исследования»? Компания Procter & Gamble! Эта компания, владеющая львиной долей акций на рынке одноразовых подгузников, наняла консалтинговую фирму Artur D. Little, Inc. и поручила ей сравнить влияние на окружающую среду обычных и одноразовых подгузников. Это исследование показало, что одноразовые подгузники не более опасны, чем обычные. Еще более тенденциозное исследование провела компания Franklin Associates. Кто оплатил это исследование? Американский бумажный институт — организация, заинтересованная в распространении одноразовых подгузников. Однако прежде, чем делать скоропалительные выводы, рассмотрим еще несколько «исследований». В 1988 году были опубликованы результаты исследования, в ходе которого выяснилось, что использованные водонепроницаемые одноразовые подгузники образуют горы мусора, практически не поддающегося разложению. Кто оплатил это исследование? Отрасль производства тканевых пеленок! В 1991 году было проведено еще одно исследование, в котором доказывалось, что более опасными для окружающей среды являются тканевые пеленки. Угадайте, кто оплатил это исследование?Правильно! Отрасль производства одноразовых подгузников! В прикладном маркетинговом исследовании 5.2 приведено еще несколько примеров, иллюстрирующих важность критического отношения к вторичным данным.
Прикладное маркетинговое исследование 5.2
На самом деле все не так, как в действительности!
Результаты маркетинговых исследований часто используются в качестве вторичных данных, причем иногда их вывод можно сформулировать так: «На самом деле все не так, как в действительности!»*. Мюррей (Murray) и его соавторы иллюстрируют свою точку зрения, цитируя исследование, проведенное группой «активистов» под названием Food Research and Action Center, цель которой — освещать проблемы голода и побуждать правительство к усилению борьбы с голодом. В исследовании сказано, что на протяжении предыдущего года каждый восьмой ребенок хотя бы один раз почувствовал голод. Однако исследователи не измеряли «силу голода» напрямую. Вместо этого они использовали косвенную меру голода. Они слушали, что люди говорят оголоде. (Бюро переписи населения в качестве косвенной меры для измерения голода использует уровень дохода.) Является ли такой способ измерения чувства голода точным? Даже если это и так, телекомпания CBS Network некорректно изложила результаты проведенного исследования, заявив, что каждый восьмой ребенок в США в возрасте до 12 лет голодает каждый день. Это утверждение абсолютно неправильное — ведь в исследовании говорилось о детях, испытывавших голод в прошлом году.** В других исследованиях шла речь о связи, существующей между употреблением кофе и развитием определенного заболевания, а вместо этого в газетах написали, что кофе предотвращает это заболевание.Синтия Кроссен (Cynthia Crossen), репортер и редактор журнала Wall Street Journal, посвятила проблеме достоверности результатов исследований свою книгу. Она предупредила читателей о том, что, несмотря на традиционное доверие, которое американцы испытывают к научной информации, необходимо понимать, что большое количество «исследований» проводится, чтобы повысить объем продаж, поддержать на выборах своего кандидата, навязать клиентам свое мнение, оправдать неудачу и т.п. Множество исследований выполнено не для того, чтобы увеличить знания, а чтобы продать товар или потрафить спонсору.
Более того, если результаты исследования противоречат интересам спонсора, их, как правило, скрывают. Кроссен привела несколько ярких подтверждений своего тезиса. В частности, она описала исследование, в котором утверждалось, будто 62% американцев хотят сохранить в обращении монету стоимостью один цент. Кто был спонсором? Компания, производящая изделия из цинка (одноцентовые монеты производятся из цинка). В другом исследовании вдруг обнаружилось, что 70% владельцев сотовых телефонов считают, будто обладание телефоном помогло им добиться успеха в бизнесе. Кто спонсор? Компания Motorola.Даже исследования эффективности новых лекарств часто финансируются фармацевтическими компаниями, торгующими этими препаратами! Кроссен верит, что бум нечистоплотных исследований связан с деньгами. Именно деньги используются «спонсорами» (покупателями) научных исследований в качестве инструмента влияния на исполнителей. Даже независимые и объективные организации, такие как университеты, часто оказываются под давлением финансового пресса. Некоторые исследователи, вырвавшиеся из-под этого гнета, вольно или невольно все равно попадают под влияние своих спонсоров. Ведь данными часто манипулируют даже без ведома самих исследователей.
Кроссен высветила важную этическую проблему, возникшую в индустрии маркетинговых исследований. Можно ли называть результаты этих исследований совершенно независимыми и объективными? Как видим, далеко не всегда!
Кто собирал информацию?
Отчеты об исследованиях часто публикуются и становятся частью вторичных данных. Однако не все исследования абсолютно объективны. Следует поинтересоваться, кто проводит исследование.
Даже если вы уверены в непредвзятости исследования, необходимо убедиться в компетентности организации, собиравшей информацию. Почему? Просто потому, что организации имеют разные ресурсы и отличаются по качеству работы. А как определить, является ли организация, проводившая сбор данных, компетентной? Во-первых, как правило, авторитетные организации широко известны в той области промышленности, где они проводят исследования. Во-вторых, прочитайте отчет об исследовании. Компетентные фирмы всегда тщательно подходят к составлению отчета и приводят подробные детали исследования, описывая процедуры и методы сбора информации. В-третьих, свяжитесь с прежними клиентами фирмы. Выясните, были ли они удовлетворены качеством работы, выполненной этой организацией.
Какая информация была собрана?
Перед применением результата необходимо понять, что именно было из-1 мерено в ходе исследования.
Существует множество исследований экономической ситуации, потенциала рынка, осуществимости проекта и т.п. Однако как измерялись воздействие, потенциал, осуществимость и т.п.? Есть много примеров, когда целью исследования было изучение одного показателя, а на самом деле измерялся совершенно другой. Рассмотрим исследование, проведенное управлением городского транспорта (Нью-Йорка) для определения количества пассажиров на автобусных маршрутах. Как показывает анализ этого проекта, в нем вообще не измерялось количество пассажиров. Вместо этого был выполнен подсчет пассажирских талонов. Поскольку один пассажир может использовать несколько талонов для поездки в пункт назначения (пересаживаясь с одного автобуса на другой), очевидно, что количество пассажиров в исследовании переоценено. В качестве другого примера рассмотрим оценку «эффективности рекламы». Как ее измерить? Следует ли оценить объем продаж на следующей неделе после появления рекламного ролика? А может быть, необходимо подсчитать долю покупателей, которые могут назвать марку товара на следующий день после просмотра рекламы? Существует ли значительная разница между этими показателями? Может быть, да, а может быть, нет. Это зависит от дальнейших намерений пользователей. Важно лишь, чтобы они ясно понимали, какая именно информация была собрана в исследовании.
Как получена информация?
Оцените метод сбора первичных данных, которые по отношению к вам играют роль вторичных. Освоив наш курс по маркетинговым исследованиям, вы сможете это сделать намного лучше.
Следует поинтересоваться, какими методами была собрана информация из вторичных источников. Что представляла собой выборка? Насколько большой она была? Какой уровень отказов респондентов? Была ли проведена верификация информации? Изучая книгу, читатели могли убедиться, что существует множество альтернативных способов сбора первичной информации и каждый из них имеет большое значение. Даже оценивая вторичные данные, следует помнить, что некто собирал их в качестве первичных. Таким образом, метод сбора информации может оказать влияние на ее природу и качество. К сожалению, не всегда легко определить, каким образом были собраны вторичные данные. Однако, как указывалось ранее, авторитетные организации всегда указывают методы, которыми они пользовались при сборе информации. Если же методы не указаны, а сама информация чрезвычайно важна, необходимо приложить дополнительные усилия, чтобы выяснить это.
Как полученные данные согласуются с другой информацией?
В некоторых случаях вторичные данные распространяются несколькими независимыми организациями. Это позволяет сравнить их между собой и оценить их достоверность. В идеале, если две или несколько независимых организаций публикуют одни и те же данные, им можно доверять. Например, демографические данные об округах, городах и районах широко доступны из многих источников. При оценке репрезентативности исследования определенного географического региона необходимо сравнить демографические характеристики выборки с демографическими показателями всего населения. Из данных Бюро переписи населения следует, что городское население США состоит из 45% мужчин и 55% женщин. Предположим, что в исследуемой выборке оказалось 46% мужчин и 54% женщин. В этом случае данным исследования можно доверять. Однако ситуация, когда две организации публикуют совершенно одинаковые данные, встречается редко. Следовательно, необходимо оценить разницу между ними. Если разница между данными, опубликованными несколькими независимыми организациями, велика, ни одному источнику верить нельзя. В таких ситуациях необходимо тщательно проверить, какая информация была собрана, какие методы при этом использовались и т.п. Например, представим себе, что, получив от корпорации Survey Sampling, Inc. данные о количестве компаний в некоем городе и сравнив их с правительственными данными, опубликованными в справочнике County Business Patterns (CBP), вы обнаружите значительные расхождения. В частности, предположим, что количество компаний, упомянутых в отчете корпорации Survey Sampling, Inc., намного превышает количество компаний, перечисленных в справочнике CBP? Почему? Чтобы ответить на этот вопрос, необходимо сначала определить, какая информация на самом деле собрана этими организациями и как это было сделано. Оказывается, ни одна из этих организаций в действительности не считала компании, зарегистрированные в данном городе. Просто в справочнике CBP указано количество компаний, сообщающих о налогах, выплаченных ее сотрудниками. Некоторые фирмы могут просто скрывать эту информацию, а малые компании, имеющие «неоплачиваемых сотрудников» (т.е. компании, в которых работают только ее владельцы), вообще не включаются в справочник CBP. Следовательно, с одной стороны, суррогатный индикатор CBP занижает количество реально существующих компаний. С другой стороны, фирма Sample Sampling подсчитывает количество компаний, руководствуясь справочником Yellow Pages.
Если разница между данными, опубликованными несколькими независимыми организациями, велика, ни одному источнику верить нельзя. В таких ситуациях необходимо тщательно проверить, измерялись ли одни и те же показатели, какие методы сбора информации использовались и т.п.
Возникает вопрос: «Что такое компания?». В городе может существовать фран-чайзинговая организация, владеющая ресторанами McDonald’s, которой в справочнике Yellow Pages соответствуют девять адресов. Итак, сколько компаний следует учесть в нашем исследовании — одну или девять? Фирма Sample Sampling учтет девять компаний. Следовательно, она переоценивает количество компаний, зарегистрированных в городе. Какие источники данных следует использовать? Это зависит от цели исследования и способа дальнейшего использования этой информации. Корректность источника зависит от того, как именно представлена информация. Ключевым пунктом является необходимость адекватно оценивать корректность разных источников данных, чтобы получать наиболее надежную информацию.
Последнее слово в оценке источника информации остается за публичной оценкой. Например, книги часто рецензируются, и эти рецензии публикуются в газетах и журналах. Многие научные журналы публикуют статьи, которые проходят тщательную предварительную проверку. К тому же научные журналы, как правило, не принимают рекламных объявлений и, следовательно, более объективны. Однако качество информации, публикуемой в обычных журналах, на Web-сайтах и в отчетах, распространяемых компаниями, как правило, оценить намного сложнее.
Обновил Сергей Ломакин
Краткая справка
Прежде чем приступить к обзору, рассмотрим значения определений, которые встретятся в статье.
Синтаксис – это формула функции, которая начинается со знака равенства и состоит из 2 частей: названия функции и аргументов, имеющих определенную последовательность и заключенных в круглые скобки.
Аргументы функции могут быть представлены текстовыми, числовыми, логическими значениями или ссылками на ячейки, диапазон ячеек. Между собой аргументы разделяются точкой с запятой.
Продвинем ваш бизнес
В Google и «Яндексе», соцсетях, рассылках, на видеоплатформах, у блогеров
Подробнее

1. ВПР
ВПР расшифровывается как «вертикальный просмотр».
ВПР позволяет найти данные в текстовой строке таблицы или в диапазоне ячеек и добавить их в другую таблицу.

Синтаксис
Функция состоит из 4 аргументов и представлена следующей формулой:
=ВПР(искомое_значение;таблица;номер_столбца;[интервальный_просмотр])
- «Искомое значение» указывают в первом столбце диапазона ячеек. Аргумент может являться значением или ссылкой на ячейку.
- «Таблица». Группа ячеек, в которой выполняется поиск искомого и возвращаемого значения. Диапазон ячеек должен содержать искомое значение в первом столбце и возвращаемое значение в любом месте.
- «Номер столбца». Номер столбца, содержащий возвращаемое значение.
- «Интервальный просмотр» – необязательный аргумент. Это логическое выражение, определяющее, насколько точное совпадение должна обнаружить функция. В связи с этим условием выделяют 2 функции:
○ Истина – функция, вводимая по умолчанию, ищет ближайшее к искомому значение. Данные первого столбца должны быть упорядочены по возрастанию или в алфавитном порядке.
○ Ложь – ищет точное значение в первом столбце.
Примеры
Рассмотрим несколько примеров использования функции ВПР.
Предположим, нам нужно найти в таблице количество просмотров по запросу «купить планшет».

Чтобы найти в табличке нужное значение, понадобится функция ВПР
Функции нужно найти данные, соответствующие значению «планшет», которое указано в отдельной ячейке (С3) и выступает в роли искомого значения. Аргумент «таблица» здесь – диапазон поиска от A1:B6; номер столбца, содержащий возвращаемое значение – «2». В итоге получаем следующую формулу: =ВПР(С3;А1:B6;2). Результат – 31325 просмотров в месяц.

Используем формулу ВПР
В следующих двух примерах применен интервальный просмотр с двумя вариантами функций: ИСТИНА и ЛОЖЬ.
 при искомом значении «900000»")
Применен интервальный просмотр с функцией ИСТИНА, которая выдает приблизительное значение «886146» («купить машину») при искомом значении «900000»

Применение интервального просмотра с функцией ЛОЖЬ позволяет найти значение, в точности равное искомому
2. ЕСЛИ
Функция ЕСЛИ выполняет проверку заданных условий, выбирая один из двух возможных результатов: если сравнение истинно и если сравнение ложно.
Синтаксис
Формула функции состоит из трех аргументов и выглядит следующим образом:
=ЕСЛИ(логическое_выражение;«значение_если_истина»;«значение_если_ложь»),
где:
- «логическое выражение» – формула;
- «значение если истина» – значение, при котором логическое выражение выполняется;
- «значение если ложь» – значение, при котором логическое выражение не выполняется.
Примеры
Рассмотрим пример использования обычной функции ЕСЛИ.

Выполнение плана продаж здесь обусловлено наличием суммы выручки больше 30 000 руб.
Чтобы узнать, кто из продавцов выполнил план, а кто нет, нужно ввести следующую формулу:
=ЕСЛИ(B2>30000;«План выполнен»;«План не выполнен»)
- Логическое выражение здесь – формула «B2>30000».
- «Значение если истина» – «План выполнен».
- «Значение если ложь» – «План не выполнен».
Вложенные функции ЕСЛИ
Помимо обычной функции ЕСЛИ, которая выдает всего 2 результата – «истина» и «ложь», существуют вложенные функции ЕСЛИ, выдающие от 3 до 64 результатов. В данном случае формула может вмещать в себя несколько функций.

В этом примере одна функция вложена в другую, и всего внесено 3 результата
Вложенные функции довольно сложны в использовании и часто выдают ошибки в формуле, поэтому рекомендую пользоваться ими в самых исключительных случаях.
Существует еще один способ использования функции ЕСЛИ – для проверки, пуста ячейка или нет. Для этого ее можно использовать с функцией ЕПУСТО:
=ЕСЛИ(ЕПУСТО(номер ячейки);«Пустая»;«Не пустая».

Пример совмещения 2 функций, позволяющего выявить верный результат
Вместо функции ЕПУСТО также можно использовать другую формулу:
«номер ячейки=«» (ничего).

Формула не требует добавления других функций
ЕСЛИ – одна из самых популярных функций в Excel. Она помогает определить истинность тех или иных значений, получить результаты по разным данным и выявить пустые ячейки, к тому же ее можно использовать в сочетании с другими функциями.
Функция ЕСЛИ является основой других формул: СУММЕСЛИ, СЧеТЕСЛИ, ЕСЛИОШИБКА, СРЕСЛИ. Мы рассмотрим три из них – СУММЕСЛИ, СЧеТЕСЛИ и ЕСЛИОШИБКА.

«Google Таблицы»: большой и простой гайд
3. СУММЕСЛИ и СУММЕСЛИМН
Функция СУММЕСЛИ позволяет суммировать данные, соответствующие условию и находящиеся в указанном диапазоне.
Синтаксис
Функция состоит из трех аргументов и имеет формулу:
=СУММЕСЛИ(диапазон;условие;[диапазон_суммирования])
- «Условие» – аргумент, определяющий какие именно ячейки нужно суммировать. Это может быть текст, число, ссылка на ячейку или функция. Обратите внимание на то, что условия с текстом и математическими знаками необходимо заключать в кавычки.
- «Диапазон суммирования» – необязательный аргумент. Позволяет указать на ячейки, данные которых нужно суммировать, если они отличаются от ячеек, входящих в диапазон.
Пример
В приведенном ниже примере функция суммировала данные запросов, количество переходов по которым больше 100 000.
, которая является сложением ячеек (B2:B4), удовлетворяющих условию (>100000). Формула: =СУММЕСЛИ(B2:B6;«>100000»)")
Используем синтаксис. В примере функция вычислила сумму (519414), которая является сложением ячеек (B2:B4), удовлетворяющих условию (>100000). Формула: =СУММЕСЛИ(B2:B6;«>100000»)
Если нужно суммировать ячейки в соответствии с несколькими условиями, можно воспользоваться функцией СУММЕСЛИМН.
Синтаксис
Формула функции имеет следующий вид:
=СУММЕСЛИМН(диапазон_суммирования; диапазон_условия1; условие1; [диапазон_условия2; условие2]; …)
«Диапазон условия 1» и «условие 1» – обязательные аргументы, остальные – необязательные.
4. СЧЕТЕСЛИ и СЧЕТЕСЛИМН
Функция СЧеТЕСЛИ считает количество непустых ячеек, соответствующих заданному условию внутри указанного диапазона.
Синтаксис
Формула функции:
=СЧЕТЕСЛИ(диапазон;критерий)
- «Диапазон» – группа ячеек, которые нужно подсчитать.
- «Критерий» – условие, согласно которому выбираются ячейки для подсчета.
Пример
В примере функция подсчитала количество ключей, переходов по которым больше 100 000.

Функция подсчитывает количество элементов, не указывая ссылок на них
В функции СЧЕТЕСЛИ можно использовать только один критерий. Если нужно сделать подсчет по нескольким условиям, примените функцию СЧЕТЕСЛИМН.
Синтаксис
Функция позволяет подсчитать количество ячеек, соответствующих нескольким заданным условиям. Каждому условию соответствует один вариант диапазона ячеек.
Формула функции:
=СЧЕТЕСЛИМН(диапазон_условия1;условие1;[диапазон_условия2;условие2];…)
«Диапазон условия 1» и «условие 1» – обязательные аргументы, остальные необязательны. Можно использовать до 127 пар диапазонов и условий.
5. ЕСЛИОШИБКА
Функция возвращает указанное значение, если вычисление по формуле дает ошибочный результат. Правильный результат она оставляет.
Синтаксис
Функция имеет 2 аргумента и представлена формулой:
=ЕСЛИОШИБКА(значение;значение_если_ошибка),
где:
- «значение» – формула, которая проверяется на наличие ошибки;
- «значение_если_ошибка» – значение, появляющееся в ячейке в том случае, если вычисление в формуле выдало ошибку.

Что-то не сходится
Предположим, что у вас сломался счетчик аналитики, и в ячейке, в которой нужно указать число посетителей, стоит ноль, а число покупок – 32. Как такое может быть? Функция указывает на ошибку и вводит значение, соответствующее ей – «перепроверить».

Функция знает, что на ноль делить нельзя, поэтому вводит значение, указываемое при возможной ошибке
6. ЛЕВСИМВ
Функция ЛЕВСИМВ позволяет выделить необходимое количество знаков с левой стороны строки.
Синтаксис
Функция состоит из 2 аргументов и представлена формулой:
=ЛЕВСИМВ(текст;[число_знаков]),
где:
- «текст» – текстовая строка, содержащая знаки, которые необходимо извлечь;
- «число знаков» – необязательный аргумент, указывающий на количество извлекаемых знаков.
Пример
Использование функции позволяет посмотреть, как будут выглядеть тайтлы к страницам сайта или статьям.

Получаем автоматическое заполнение тайтла
Если вы хотите, чтобы тайтлы были лаконичными и состояли из 60 знаков, функция отсчитает первые 60 символов и покажет, как будет выглядетьтайтл. Для этого необходимо составить формулу: =ЛЕВСИМВ(А5;60), где А5 – адрес рассматриваемой ячейки, «60» – число извлекаемых символов.
7. ПСТР
Функция ПСТР позволяет извлечь необходимое количество символов внутри текста, начиная с указанной позиции.
Синтаксис
Формула функции состоит из 3 аргументов:
=ПСТР(текст;начальная_позиция;число_знаков)
- «Текст» – строка, содержащая символы, которые нужно извлечь.
- «Начальная позиция» – позиция знака, с которого начинается извлекаемый текст.
- «Число знаков» – количество извлекаемых символов.
Пример
Функцию можно применять, чтобы упростить названия тайтлов, убрав стоящие в их начале слова.

Тайтл стал более читабельным
8. ПРОПИСН
Функция ПРОПИСН делает все буквы в тексте прописными.
Синтаксис
Формула функции:
=ПРОПИСН(текст)
«Текст» здесь – текстовый элемент или ссылка на ячейку.
Пример

Если ячеек много, мы сэкономим кучу времени
9. СТРОЧН
Функция СТРОЧН делает все буквы в тексте строчными.
Синтаксис
Формула функции:
=СТРОЧН(текст)
Аргумент «текст» – текстовый элемент или адрес ячейки.
Пример

Замены прошла успешно и «РОЖДЕНИЯ» превратилось в «рождения»
10. ПОИСКПОЗ
Функция ПОИСКПОЗ помогает найти указанный элемент в массиве ячеек и определяет его положение.
Синтаксис
Формула функции:
=ПОИСКПОЗ(искомое_значение;просматриваемый_массив;тип_сопоставления)
«Искомое значение» и «просматриваемый массив» – обязательные аргументы, «тип сопоставления» – необязательный.
Рассмотрим подробнее аргумент «тип сопоставления». Он указывает, каким образом сопоставляется найденное значение с искомым. Существует 3 типа сопоставления:
1 – значение меньше или равно искомому (при указании данного типа нужно учитывать, что просматриваемый массив должен быть упорядочен по возрастанию);
0 – точное совпадение;
-1 – наименьшее значение, которое больше или равно искомому.
Примеры
Рассмотрим следующий пример. Здесь я попыталась узнать, какой из запросов в приведенной таблице имеет количество переходов, которое равно или меньше 900.

Получаем значение 3
Формула функции здесь:
=ПОИСКПОЗ(900;B2:B6;1)
- 900 – искомое значение.
- B2:B6 – просматриваемый массив.
- 1 – тип сопоставления (меньше или равно искомому).
Результат – «3», то есть третья позиция в указанном диапазоне.
11. ДЛСТР
Функция ДЛСТР позволяет определить длину текста, содержащегося в указанной ячейке.
Синтаксис
Формула функции имеет всего один аргумент – текст (номер ячейки):
=ДЛСТР(текст)
Пример
Функцию можно использовать для проверки длины символов в description.

Длина – 125 символов
12. СЦЕПИТЬ
Функция СЦЕПИТЬ позволяет объединить несколько текстовых элементов в одну строку. В формуле для объединения элементов указываются как номера ячеек, содержащих текст, так и сам текст. Можно указать до 255 элементов и до 8192 символов.
Синтаксис
Для того чтобы объединить текстовые элементы без пробелов, используются следующие формулы:
=СЦЕПИТЬ(текст1;текст2;текст3)
Аргумент «текст» – текстовый элемент или ссылка на ячейку.
Примеры
В приведенном ниже примере введена формула:
=СЦЕПИТЬ(А2;B2;С2)

Сделаем ФИО читаемым при помощи формулы
Для того же, чтобы слова в строке разделялись пробелами, в формулу необходимо вставить знаки пробелов в кавычках:
=СЦЕПИТЬ(текст1;« »;текст2;« »;текст3;« »)
В следующем примере функция представлена формулой:
=СЦЕПИТЬ(A2;» «;B2;» «;C2)

Получилось. Текст стал читаемым
Существует и другой вариант добавления пробелов в формулу функции – введение слов, заключенных в кавычки вместе с пробелами:
=СЦЕПИТЬ(«текст1 »;«текст2 »;«текст3 »)

Не перепутайте. Номера ячеек не сработают
13. ПРОПНАЧ
Функция ПРОПНАЧ преобразует заглавные буквы всех слов в тексте в прописные (верхний регистр), а все остальные буквы – в строчные (нижний регистр).
Синтаксис
Функция представлена короткой формулой, имеющей всего один аргумент:
=ПРОПНАЧ(текст)
Пример
Рассмотрим пример, в котором представлены образцы с различными вариантами написания букв. Функция быстро привела их в читабельное состояние.

Получили читаемый текст, исправив регистровку букв в ячейках
Эту функцию очень удобно использовать при составлении списков с именами собственными, для преобразования текстовых элементов, напечатанных строчными, прописными или различными по размеру буквами.
14. ПЕЧСИМВ
Функция ПЕЧСИМВ позволяет удалить все непечатаемые знаки из текста.
Синтаксис
Формула функции:
=ПЕЧСИМВ(текст)
Пример
В приведенном примере текст в ячейке A1 содержит непечатаемые знаки конца абзаца.

Если в ячейке присутствовали непечатаемые знаки конца абзаца, то они будут автоматически удалены
Эту функцию нужно использовать в тех случаях, когда текст переносится в таблицу из других приложений, имеющих знаки, печать которых невозможна в Excel.
15. СЖПРОБЕЛЫ
Функция удаляет все лишние пробелы между словами.
Синтаксис
Формула функции:
=СЖПРОБЕЛЫ(номер_ячейки)
Пример

Лишние пробелы удалены сразу
Функция простая и полезная. Единственный минус состоит в том, что она не различает границ слов, и если внутри него стоят пробелы, функция этого не поймет и не удалит их.

Такие придется поправить вручную
16. НАЙТИ
Функция НАЙТИ позволяет обнаружить искомый текст внутри текстовой строки и указывает на начальную позицию этого текста относительно начала просматриваемой строки.
Синтаксис
Функция НАЙТИ состоит из 3 аргументов и представлена формулой:
=НАЙТИ(искомый_текст;просматриваемый_текст;[начальная_позиция]);
«Начальная позиция» – необязательный аргумент, обозначающий символ, с которого нужно начать поиск.
В первом случае функция находит начальную позицию символа, с которого начинается искомый текст, а во втором начальная позиция определяется указанным количеством байтов.
Пример
В примере функция представлена следующей формулой: =НАЙТИ(«чай»;A4)
")
Аналогичный результат даст функция НАЙТИБ (1 байт равен одному символу)
17. ИНДЕКС
Функция ИНДЕКС позволяет возвращать искомое значение.
Синтаксис
Формула функции ИНДЕКС имеет следующий вид:
=ИНДЕКС(массив; номер_строки; [номер_столбца])
«Номер столбца» – необязательный аргумент.
Пример

Можно заменить ВПР, применив ИНДЕКС + ПОИСКПОЗ
Функцию ИНДЕКС можно использовать вместе с функцией ПОИСКПОЗ с целью замены функции ВПР.
18. СОВПАД
Функция проверяет идентичность двух текстов, и, если они совпадают, выдает значение ИСТИНА, если различаются – значение ЛОЖЬ.
Синтаксис
Формула функции:
=СОВПАД(текст1;текст2)
Пример

Получаем значение true
Пары слов из строк 1 (A1 и B1) и 2 (A2 и B2) различны по написанию, поэтому функция выдает значение ЛОЖЬ, а слова из 3-й строки идентичны, поэтому определяются как ИСТИНА.
Использование функции будет полезно при анализе большого объема информации, чтобы выявить разное написание одних и тех же слов.
19. ИЛИ
Логическая функция ИЛИ возвращает значение ИСТИНА, если хотя бы один аргумент в формуле имеет значение ИСТИНА, и значение ЛОЖЬ, если все аргументы имеют значение ЛОЖЬ.
Синтаксис
Формула функции:
=ИЛИ(логическое_значение1;[логическое_значение2];…)
Здесь «логическое значение1» – обязательный аргумент, остальные аргументы необязательны. В формулу можно добавлять от 1 до 255 логических значений.
Пример
Формула в примере появляется значение ИСТИНА, так как 2 из 3 аргументов имеют значение ИСТИНА.

Истинность подтвердилась
20. И
Функция И возвращает значение ИСТИНА, если все аргументы в формуле имеют значение ИСТИНА, и значение ЛОЖЬ, если хотя бы один из аргументов имеет значение ЛОЖЬ.
Синтаксис
Функция может содержать множество аргументов и имеет формулу:
=И(логическое_значение1;[логическое_значение2];…)
«Логическое_значение1» – обязательный аргумент, остальные аргументы – необязательные.

Проверили корректность формулы. Получилось значение true
В этом примере все аргументы имеют значение ИСТИНА, поэтому результат соответствующий.
Функции И и ИЛИ просты в использовании, но, если сочетать их друг с другом или с другими функциями (ЕСЛИ и НЕ), можно вывести более сложные и интересные формулы.
21. СМЕЩ
Функция СМЕЩ возвращает ссылку на диапазон, отстоящий от ячейки или группы ячеек на указанное число строк и столбцов.
Синтаксис
Функция состоит из 5-ти аргументов и представлена следующей формулой:
=СМЕЩ(ссылка;смещ_по_строкам;смещ_по_столбцам;[высота];[ширина])
Рассмотрим каждый из аргументов:
- «Ссылка» на ячейку или диапазон ячеек, от которых вычисляется смещение.
- «Смещение по строкам» показывает количество строк, которые необходимо отсчитать, чтобы переместить левую верхнюю ячейку массива или одну ячейку в нужное место. Значение аргумента может быть положительным (если отсчет строк ведется вниз) и отрицательным числом (если отсчет строк ведется вверх).
- «Смещение по столбцам». Здесь указывается количество столбцов, которые нужно отсчитать, чтобы переместить ячейку или группу ячеек влево или вправо. Левая верхняя ячейка диапазона при этом должна находиться в указанном месте. Значение аргумента может быть положительным (если отсчет столбца ведется вправо) и отрицательным числом (если отсчет столбца ведется влево).
- «Высота» – необязательный аргумент. Здесь указывается число строк возвращаемой ссылки. Значение аргумента должно быть положительным числом.
- «Ширина» – необязательный аргумент. Здесь указывается число столбцов возвращаемой ссылки. Значение аргумента должно быть положительным числом.
Пример
Рассмотрим пример использования функции СМЕЩ, имеющую следующую формулу:
=СМЕЩ(А4;-2;2)
A4 – ссылка на ячейку, от которой вычисляется смещение.
С2 – ячейка, на которую ссылается ячейка А4, а в ячейке E2 введена формула с результатом «27» – возвращаемая ссылка.

Обратите внимание на подсказку. Мы получили значение 27 – корректно
Зачем маркетологу Excel
Функции Excel помогут при анализе данных страниц сайта, подсчете количества символов в тайтле и description, преобразовании текста, поиске различных элементов в таблице.
В сегодняшнем шоу у вас есть данные гипотетического опроса от Surveymonkey.com или какой-либо другой службы. Если посмотреть на данные в блокноте, это выглядит так.

Этот тип данных разделен запятыми. Если у вас есть текстовый файл, сначала посмотрите его в блокноте. Другой тип данных разделен пробелами. Когда вы посмотрите на эти данные в блокноте, вы увидите что-то вроде этого:

Вы можете открыть эти данные в Excel. Используйте Файл — Открыть. В раскрывающемся списке Тип файлов выберите Все файлы или Текстовые файлы.

После того, как вы переключились на отображение текстовых файлов, щелкните survey.txt и выберите «Открыть».
Если ваш файл имеет расширение .CSV, Excel немедленно откроет его. В противном случае вы переходите к мастеру импорта текста — шаг 1 из 3.
На этом шаге вам нужно выбрать, будет ли ваш файл с разделителями или с фиксированной шириной. В этом случае файл survey.txt разделен, поэтому выберите «Разделить» и нажмите «Далее».

На шаге 2 Excel предполагает, что ваши данные разделены табуляцией. Вам нужно будет установить этот флажок, чтобы указать запятые, отделяющие каждое поле.

Как только вы установите этот флажок, предварительный просмотр данных покажет ваши данные в столбцах.

Щелкните Далее, чтобы перейти к шагу 3.
Если у вас есть поля даты, выберите заголовок Общие над этим полем и укажите правильный формат даты. Другой моей любимой настройкой здесь является настройка «Не импортировать (пропускать)». Если исследовательская компания предоставила мне дополнительные поля, которые мне не понадобятся, я пропущу их.

Щелкните Готово. Ваши данные будут импортированы в Excel.

Осторожно
В оставшейся части этого сеанса Excel, если вы попытаетесь вставить данные с разделителями-запятыми в Excel, операция вставки автоматически разбивает данные на несколько столбцов. Это здорово, если вы этого ожидаете, но бесит, если вы не знаете, почему это случается когда-нибудь, а не в другие. Это действие с использованием параметра с разделителями в мастере текста в столбцы, который вызывает включение этой «функции». Длится до конца сеанса Excel.
Случайная выборка
Ваш руководитель просит вас случайным образом позвонить 10% респондентов. Вместо того , чтобы выбрать первый 10, введите эту формулу справа от ваших данных: =RAND()<=10%. Поскольку RAND () возвращает число от 0 до 0,99999, это пометит около 10% записей TRUE.

Средний ответ с использованием формул
Перейдите к первой пустой строке под вашими данными. Вы хотели бы усреднить ответ. На стандартной панели инструментов есть значок Автосумма. Это греческая буква сигма. Рядом с этим значком находится стрелка раскрывающегося списка. Стрелка раскрывающегося списка содержит параметр для усреднения. Если вы сначала выберите все столбцы от C647 до I647, а затем выберите «Среднее» из раскрывающегося списка, Excel добавит все формулы одним щелчком мыши.

Анализ данных с помощью сводной таблицы
Скажите, что вы хотите проверять рейтинги стойки регистрации с течением времени. Следуй этим шагам.
- Выберите одну ячейку в ваших данных
- В меню выберите Data — Pivot Table and Pivot Chart Report.
- Дважды щелкните Далее.
- На шаге 3 нажмите кнопку «Макет».
- Перетащите дату в область строки. Перетащите Q1FrontDesk в область столбцов. Перетащите респондентов в область данных.
- Дважды щелкните Сумма респондентов в области данных. Переход от суммы к количеству.

- Щелкните ОК. Щелкните Готово.

Теперь у вас есть сводная таблица, в которой показаны все результаты работы стойки регистрации. Большинство из них попадают в диапазон 3-5, но есть несколько, получивших оценку 1 на 3/29, 3/30 и 4/2. Возможно, у вашего сотрудника на стойке регистрации по выходным проблемы с отношением.
Совет в этом шоу взят из Excel для менеджеров по маркетингу .